Python Notebook print() print(1 )"we're the best" )'we are the best' )'we\'re the best' ) "apple" +"car" )'apple' +'tree' )'apple' +'4' )'apple' +str(4 ))1 +2 )"1+2" )'1' )+2 )1.2 )+2 )
数学: print(1 +1 )1 -1 )2 *2 )2 ^1 ) 2 **3 ) 8 %3 ) 8 //3 )
自变量 variable temp=999 +1 1 +temp
while循环 a=1 while a<10 :1
for循环 example_list = [1 ,2 ,3 ,4 ,5 ]for i in example_list:1 )//---这两行都在for 循环内(python十分看重结构)"end" )
for i in range(1 ,10 ,2 ):
a = [7 ,6 ,5 ,4 ,3 ,2 ,1 ]for i in range(0 ,6 ):
if条件 x=1 2 0 if x<y>z:'x is less than y,and y is greater than z' )1 1 if a==b:'a is equal to b' )
x=1 2 0 if x>y:1 )else :2 )
x=1 2 0 if x==1 :elif y==2 :else :'finished' )
def函数 def f () :'this is a f' )
def f (a,b) :1 ,2 )
def sale (price,color,brand,is_second=True) :"price:" ,price,"color:" ,color,"brand:" ,brand,"second:" ,is_second)1000 ,"red" ,True ,"bmw" )
def fun (a) :return a*a1 5 )
全局&局部变量 def fun () :global a20 return a*a
安装numpy模块 cmd 里直接pip install numpy
(如果需要更新输入python -m pip install —upgrade pip )
文件读写 写入内容
text="this is my first text.\nThis is next line." 'my file.txt' ,'w' )
增加内容
text="\nThis is appended line." 'my file.txt' ,'a' )
打印内容
my_file=open ('my file.txt' ,'r' ) #如果没有这个文件就会创建一个,且保存在.py 文件同一个文件夹中read ()print (content)
readline/readlines
my_file=open('my file.txt' ,'r' )
class 类 class Calculate :'Good calculator' 18 def plus (self,x,y) :return ansdef minus (self,x,y) :return ans2 ,3 ))
类init功能 含参构造函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Calculate :'Good calculator' 18 def __init__ (self,name,price,height) :def plus (self,x,y) :return ansdef minus (self,x,y) :return ans'bad calculator' ,15 ,12 )2 ,3 ))
a=input() 'please give a number' )
元组 列表 这两者十分相似
a_tuple=(12 ,3 ,5 ,15 ,6 ) 12 ,3 ,5 ,15 ,6 12 ,4 ,12 ,18 ,12 ] for content in a_list: for content in a_tuple: for index in range(len(a_list)):'index=' ,index,'number=' ,a_list[index])for index in range(len(a_tuple)):'index=' ,index,'number=' ,a_list[index])
a_list=[12 ,4 ,12 ,18 ,12 ] 1 ,0 ) 123 ) 12 ) 2 ])-1 ]) 0 :3 ]) 0 :]) 4 )) 12 )) True )
多维列表 multi_list=[[1 ,2 ,3 ],[2 ,3 ,4 ],[3 ,4 ,5 ]]1 ])0 ][2 ])
字典 a_list=[1 ,2 ,3 ,4 ,5 ]'a' :1 ,'b' :2 ,'c' :3 } 1 :'a' ,2 :'b' ,3 :'c' }'a' ])2 ])del d['b' ] 'd' ]=4
字典套字典/字典套列表
d={'a' :[1 ,2 ,3 ],'b' :{'c' :3 ,5 :'e' }}'a' ][0 ])'b' ]['c' ])'b' ][5 ])
载入模块 载入模块的四种方式
import time
import time as t
from time import time,localtime
from time import *
做一个自己的模块/脚本 先自己写一个模块,并放在.py文件同根目录下
这里我给他命名为 my_mod.py
def printdata (data) :
调用
import my_mod'test my mod' )
continue/break while True :if b==1 :break else :pass
错误处理Try 下面这中方法可以输出错误信息,但是在pychram也可以做到,所以几乎用不到这种方法。
try :'eeee' ,'r' )except Exception as e:
正确的用法出现在这种情况下:
try :'eeee' ,'r+' )except Exception as e:"no such file" )'do you wanna creat a new file' )if re=='yes' :'eeee' ,'w' )"1234567" )else :pass else :"12345" )
zip/lambda/map zip
a=[1 ,2 ,3 ]4 ,5 ,6 ]1 , 4 ), (2 , 5 ), (3 , 6 )]for i,j in zip(a,b):2 ,i*2 )0.5 2 1.0 4 1.5 6 1 , 1 , 4 ), (2 , 2 , 5 ), (3 , 3 , 6 )]
lambda
和函数一样,常用来定义简单的函数
fun=lambda x,y:x+y1 ,2 ))
map
fun=lambda x,y:x+ylist (map (fun,[3 ],[5 ]))print (ans) #[8 ]list (map (fun,[3 ,4 ,5 ],[6 ,7 ,8 ])) #[9 , 11 , 13 ]print (ans)
浅复制/深复制 copy&deepcopy 赋值操作中的copy
a=[1 ,2 ,3 ]0 ]=15
copy模块中的浅复制 copy
import copy1 ,2 ,3 ]0 ]=15
copy模块中的深复制 deepcopy
什么是深复制?为什么要深复制?
看一下下面这个例子
import copy1 ,2 ,[3 ,4 ]]0 ])==id(b[0 ])) 2 ][0 ])==id(b[2 ][0 ])) 2 ][0 ]=15
可以发现列表中的列表并没有被改变地址
因此需要deepcopy 相当于完完全全的重新复制出的一个东西,地址都不同
import copy2 ][0 ])==id(b[2 ][0 ])) #true2 ][0 ]=152 ][0 ])==id(b[2 ][0 ])) #flase
Q:上面这个例子有一点很奇怪,就是用了deepcopy/copy后为什么地址还是不变呢?
A:因为python里万物都是对象,所以数字也是对象。a[0]和b[0]是两个不同的指针,但他们指向的都是”数字1”这个对象的地址,所以他们的id()是相同的。
id(a[2])!=id(b[2])是因为值不同了
pickle模块 有时候用python处理数据需要很长时间,暂停后我们希望下次接着处理,这时候就要用到pickle模块
写入pickle文件
import pickle'a' :1 ,'b' :2 ,'c' :3 }'example.pickle' ,'wb' )
import pickle'example.pickle' ,'rb' )
也可以直接这样用with,就免去了file.close()这一步
import picklewith open('example.pickle' ,'rb' ) as file:
set a={'e' ,'a' ,'b' ,'a' ,'a' ,'c' ,'a' }'this is my test'
a={'e' ,'a' ,'b' ,'a' ,'a' ,'c' ,'a' }'x' ) 'a' )'x' ) 'w' ) 'a' ,'b' ,'c' }'a' ,'x' ,'y' }
set中怎么sort?
a={'e' ,'a' ,'b' ,'a' ,'a' ,'c' ,'a' }
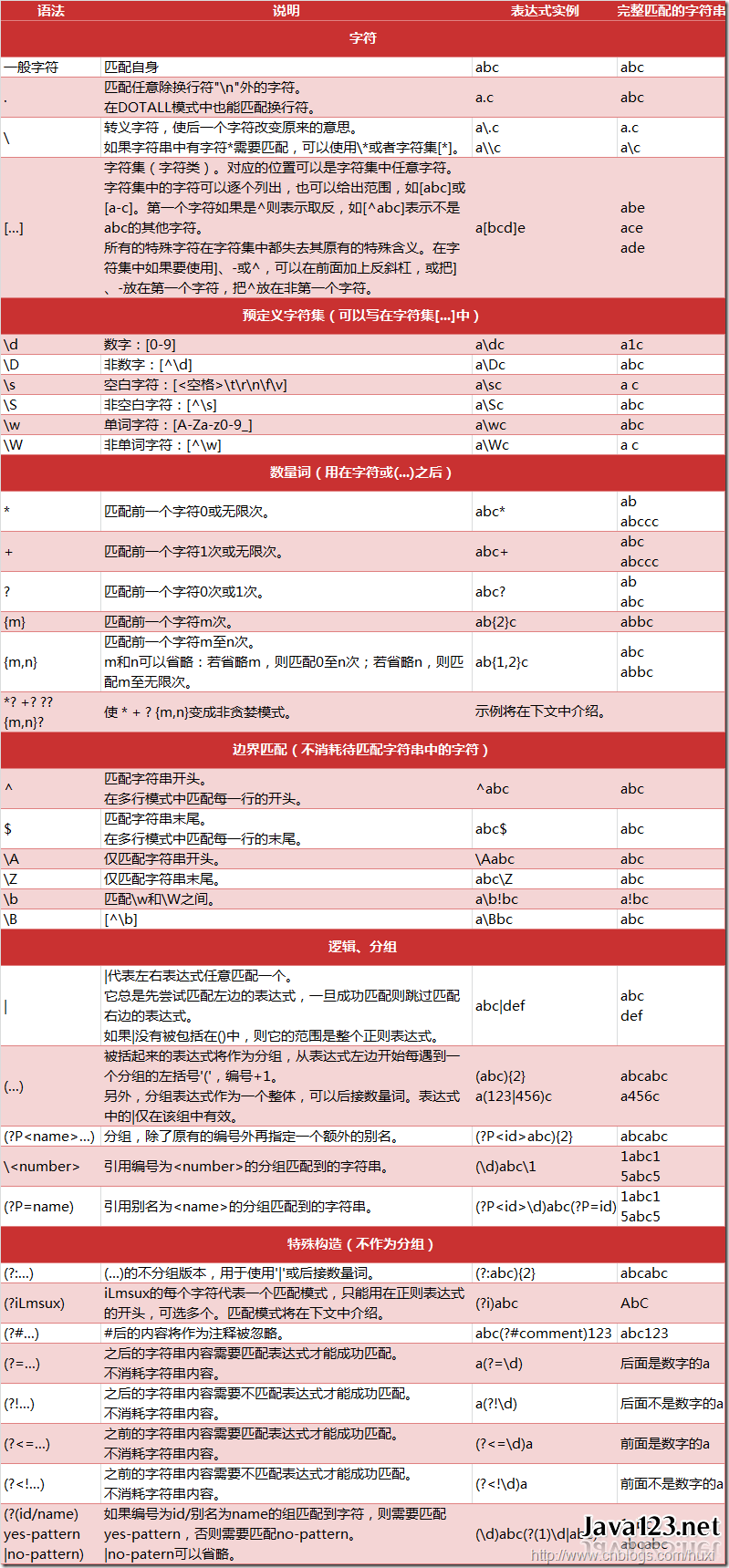
RegEx正则表达 正则表达式 (Regular Expression) 又称 RegEx, 是用来匹配字符的一种工具. 在一大串字符中寻找你需要的内容. 它常被用在很多方面, 比如网页爬虫, 文稿整理, 数据筛选等等. 最简单的一个例子, 比如我需要爬取网页中每一页的标题. 而网页中的标题常常是这种形式.
不用特意记忆,用的时候查一下即可