机器学习基石CH16:Three Learning Principle(完结)
CH16:Three Learning Principle
Occam’s Razor(奥卡姆剃刀)

对数据最简单的解释也是最有说服力的解释。

我们肯定认为左边的好一些。
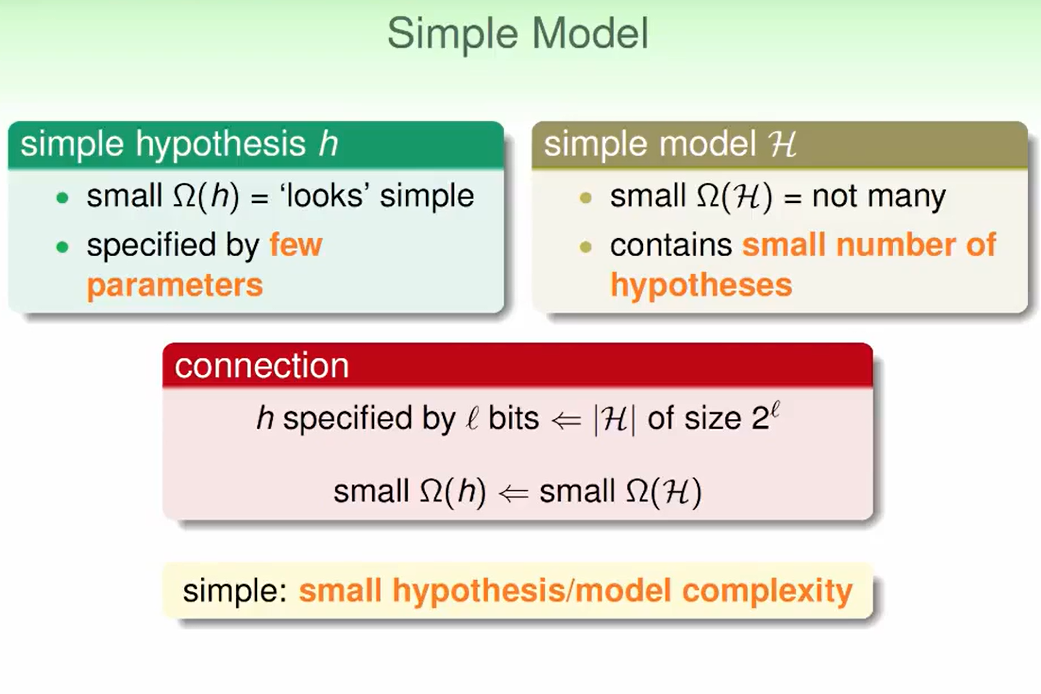
什么叫做simple model,hypothesis很简单的model,hypothesis set里的hypothesis不是很多。

如果我们的资料很乱随机给出,毫无规律可循,那么我们可以完美的分开这些资料的概率是:
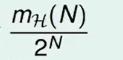
但是如果我们今天通过机器学习分开了这些资料,这意味着大概率我们的资料是可分的,因此这样的机器学习是合理的(资料是可分的,而不是随机的)。
Sampling Bias (抽样偏差)
在美国总统竞选时,Dewey和Truman到了最后选举时,当时已经投完票了,所以进行电话民调,结果显示Dewey会战胜Truman。但最后结果确实相反。
这不是因为bad luck,因为抽样次数还是很多的。也不是编辑部的搞错了的问题。
而是当时电话很贵,富人支持Dewey的比较多,导致了抽样偏差。

因此我们的训练和测试集要来自同样的分布。
同样我们之前说的信用卡发放问题,我们对这个人如果曾经有信用卡和还款情况等因素做了估计,但是我们其实放到实际应用会发现其实效果不是很好,因为我们一直在考虑对有信用卡的人的要求,而那些没有信用卡的人如果有了信用卡会不会还不上这样的问题没有做考虑。
同样我们预策喜欢电影的类型给你10部电影,预策观众喜欢看什么,我们做validation的时候,前7部用来训练model,后3部用来test我们的model,但其实我们没有考虑到模型的时间问题,也就是说一个人看电影在前7部和后面3部电影对这个观众的影响是不同的。比如我们以前喜欢看言情剧,偶然解除了科幻,我们开始看科幻多一些,可是后面三部电影却和前面7部每一部的权重是相同的,这显然不合理,一个观众越后面看的电影应该在预策中影响的权重越大,而不应该是相同的,这也是一种sampling Bias。
Data Snooping(数据窥测)
不要让我们的大脑来做选择,不要偷看资料自己去选择。

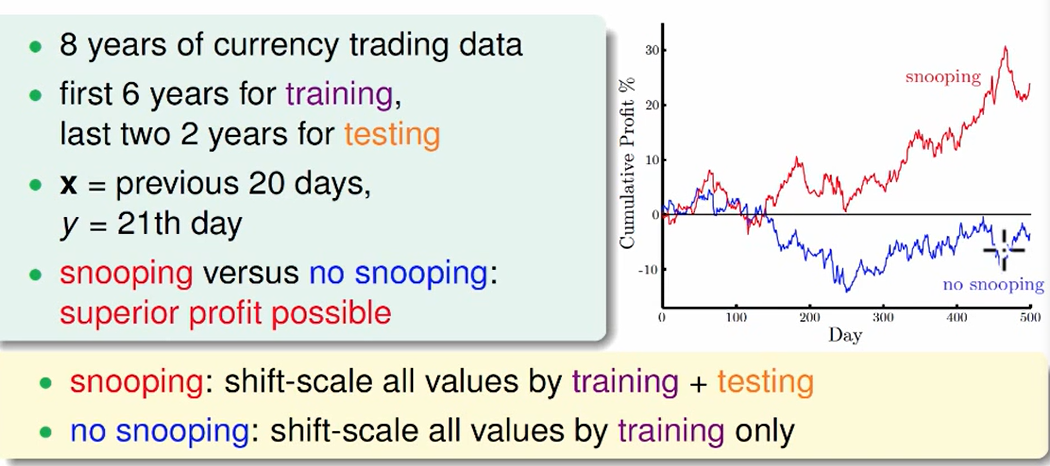

在写论文中同样存在这个问题,如果一个数据集不变,paper里的效果越来越好,但是这都是因为我们看到了前人的论文,看到了他们的模型,这个看到别人的模型也是一种Data Snooping,我们不断地修正这个模型,加了越来越多的东西,只会在某个数据集上做的很好,但是其实泛化能力已经非常差了,放到业界新的数据上,这个模型不一定work。
Power of Three
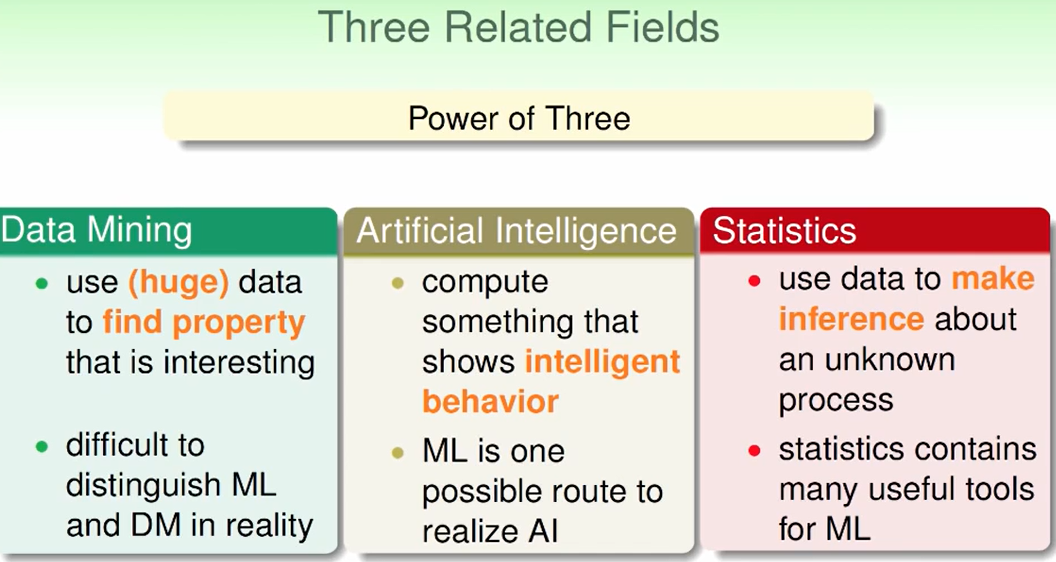
机器学习所相关的三个领域:
三个Bound:

三个模型:
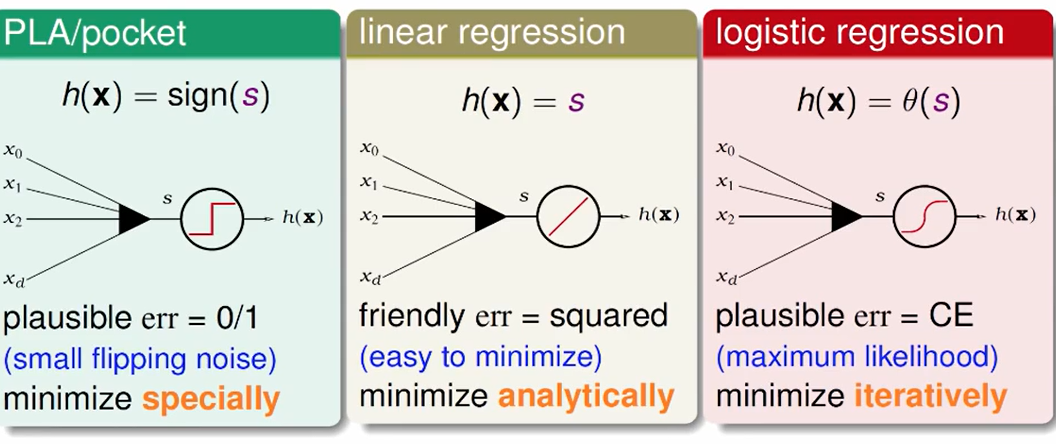
三个关键的工具:
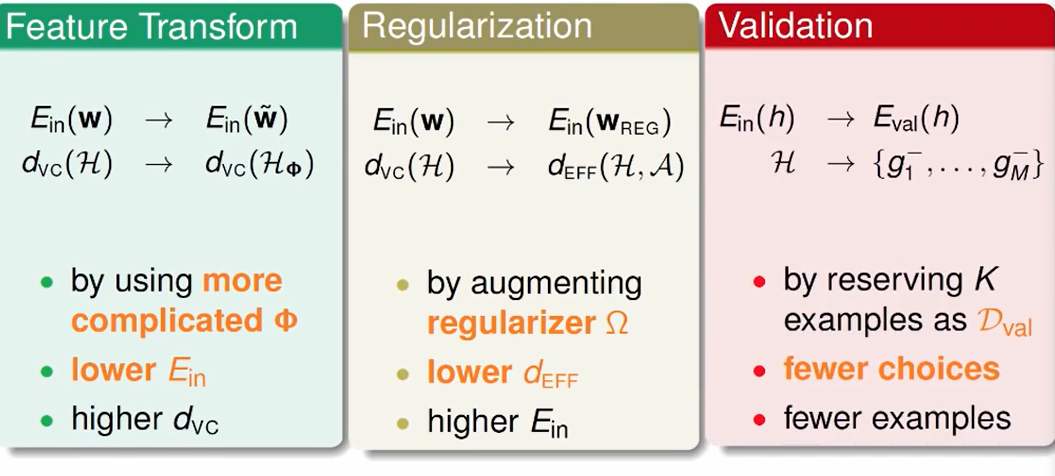
三个机器学习原则:

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!