CS231n-CH1-图像分类
CS231n:Computer Science
图像分类
数据驱动方法
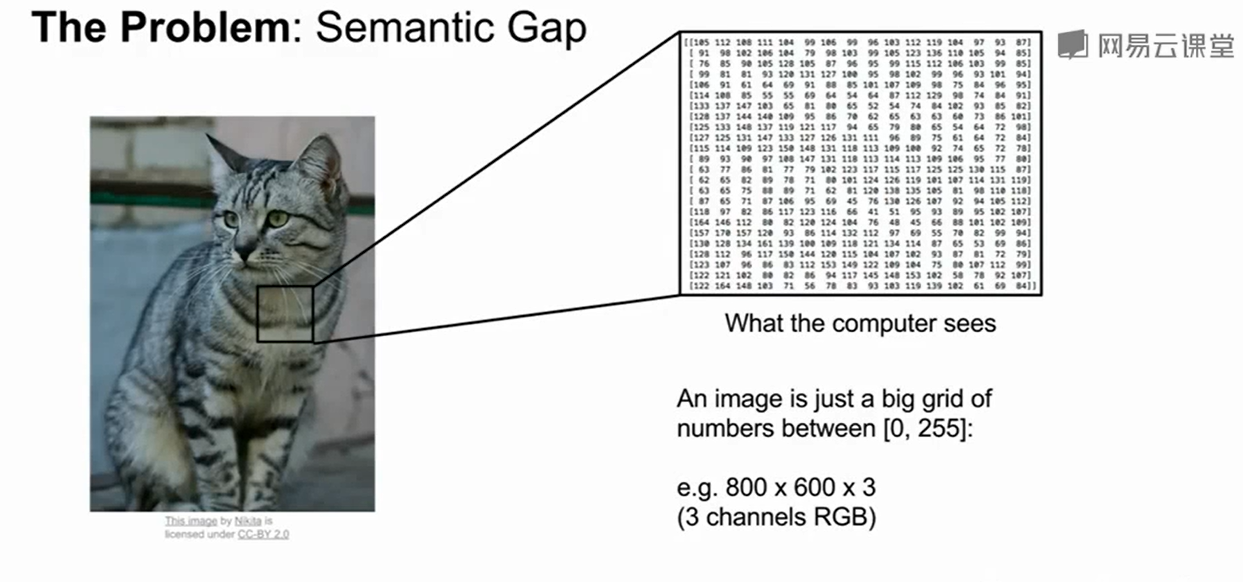
800*600*3, 其中3代表三个channels(R,G,B)。
我们可以把图像分类想成这两个大的部分:
- 第一个是训练部分:放进去(图像,label),训练得到模型
1 | |
- 第二个是预策部分:有了模型后,放进去测试图像,预测得到测试label
1 | |
这一节我们主要讲的是数据驱动的方法。
第一种分类器叫做Nearest Neighbor,用的是K-邻近算法:
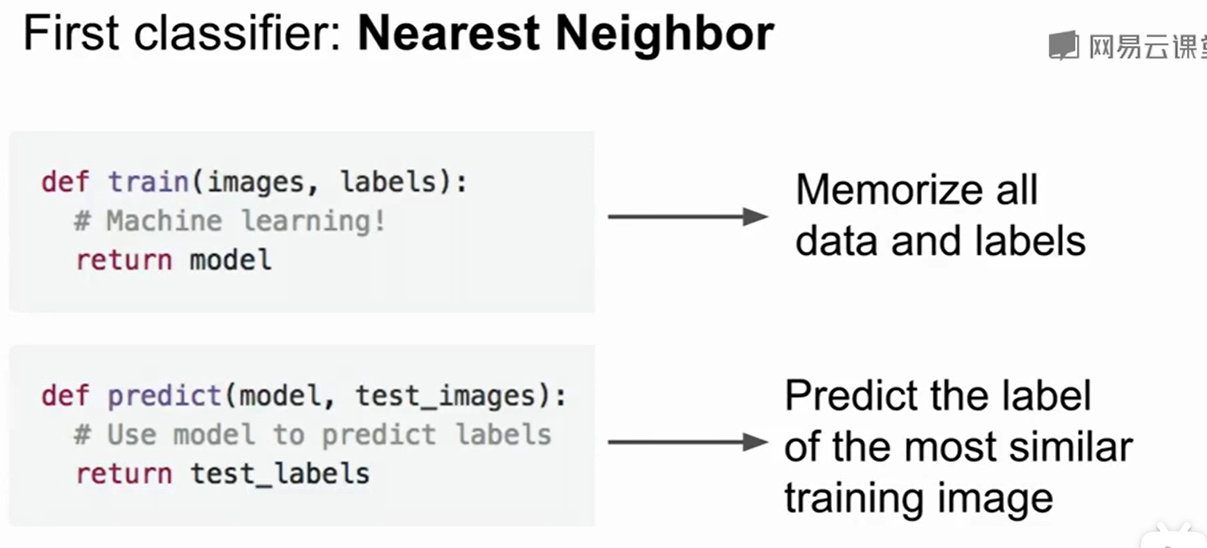
思路很简单,首先给出img和label,他会记住所有的img和label,然后test_img输入后就寻找test_img周围的图片,那么周围图片的类别可以大致的估计出这个测试图片的类别。
但是我们是怎么比较两个图片的距离呢:
这里采用了L1 distance:
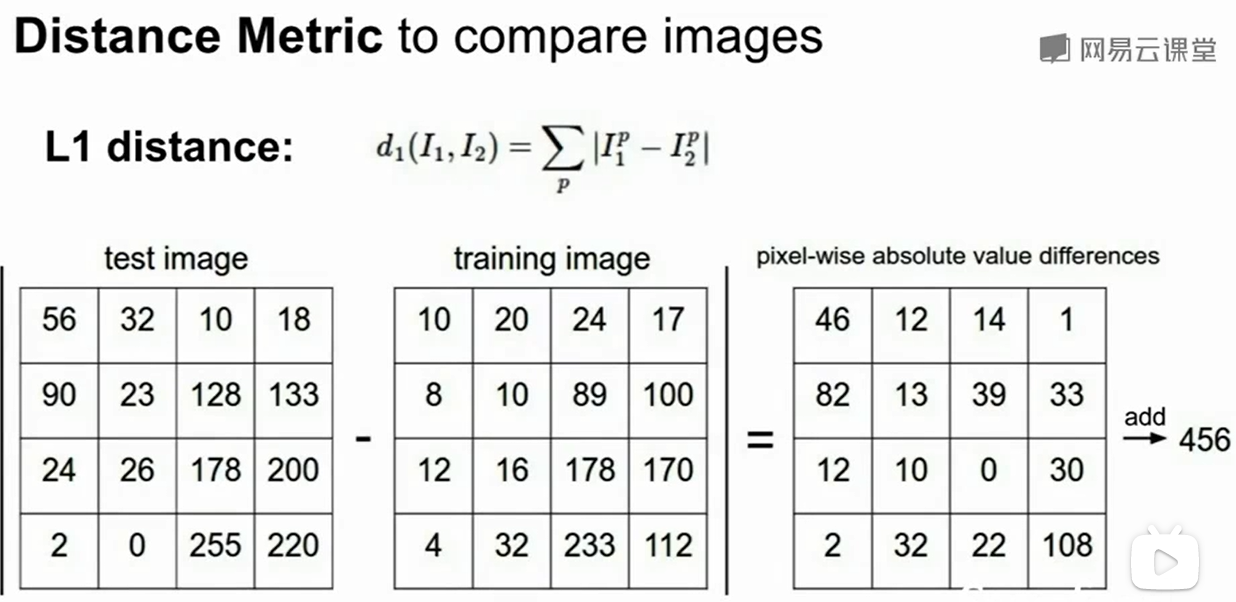
对于一张图片,Nearest Neighbour这个classifier训练是$O(1)$的,即把图片记住即可,但是预策一张图片却是$O(N)$的,因为我们需要算每个图片和这个图片的L1 Distance。
直观上来看:
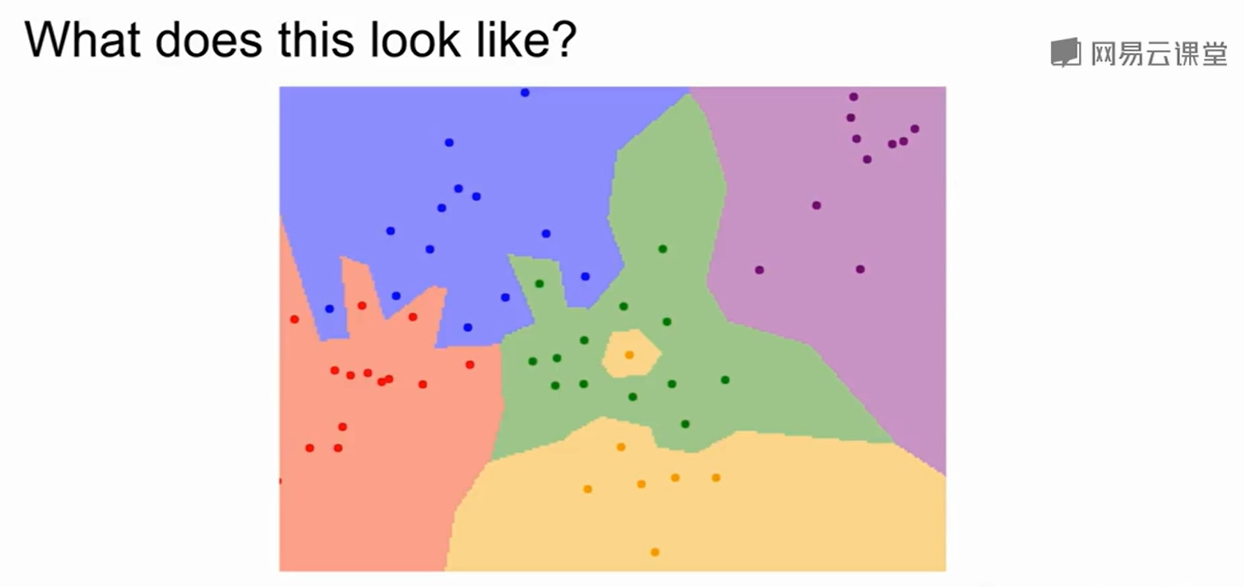
我们寻找最近的1个点(K=1)就会被上图中的中心点的黄色影响。
改变K的大小可以得到不同的效果

K-最近邻算法(KNN)
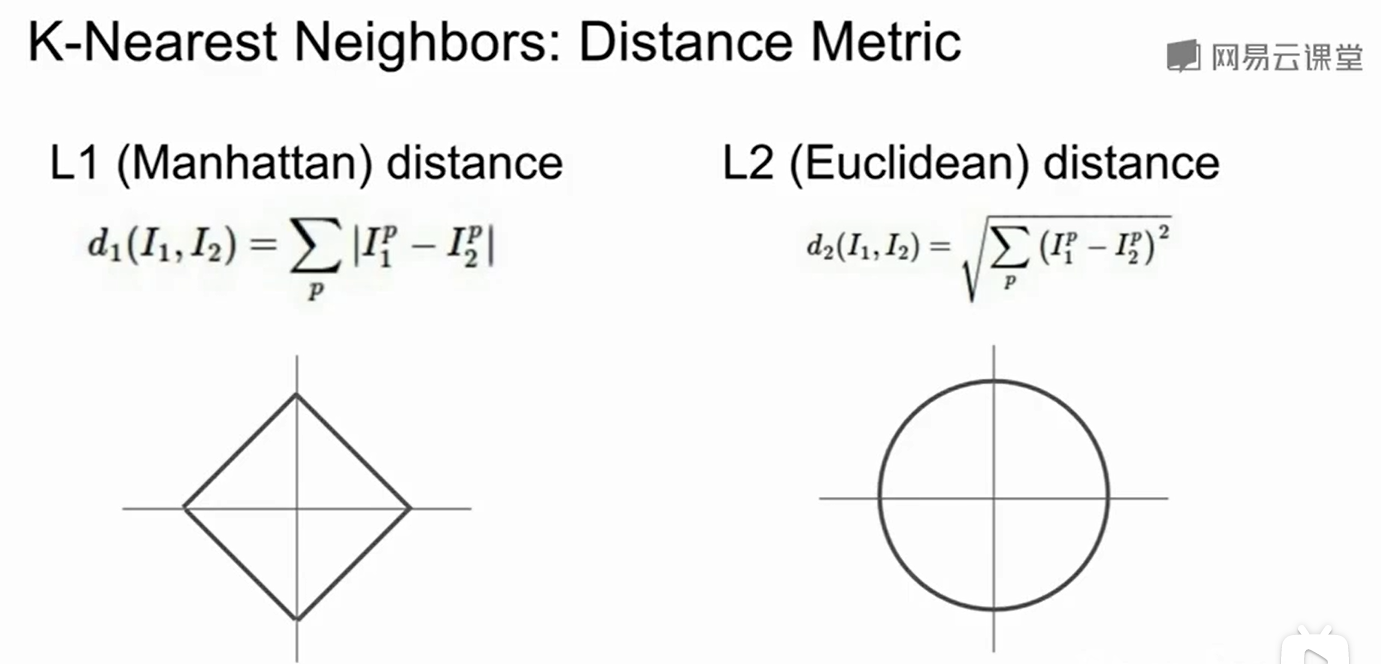
如果旋转坐标系,那么L1这种测距方式就会改变距离大小,但是L2不会。
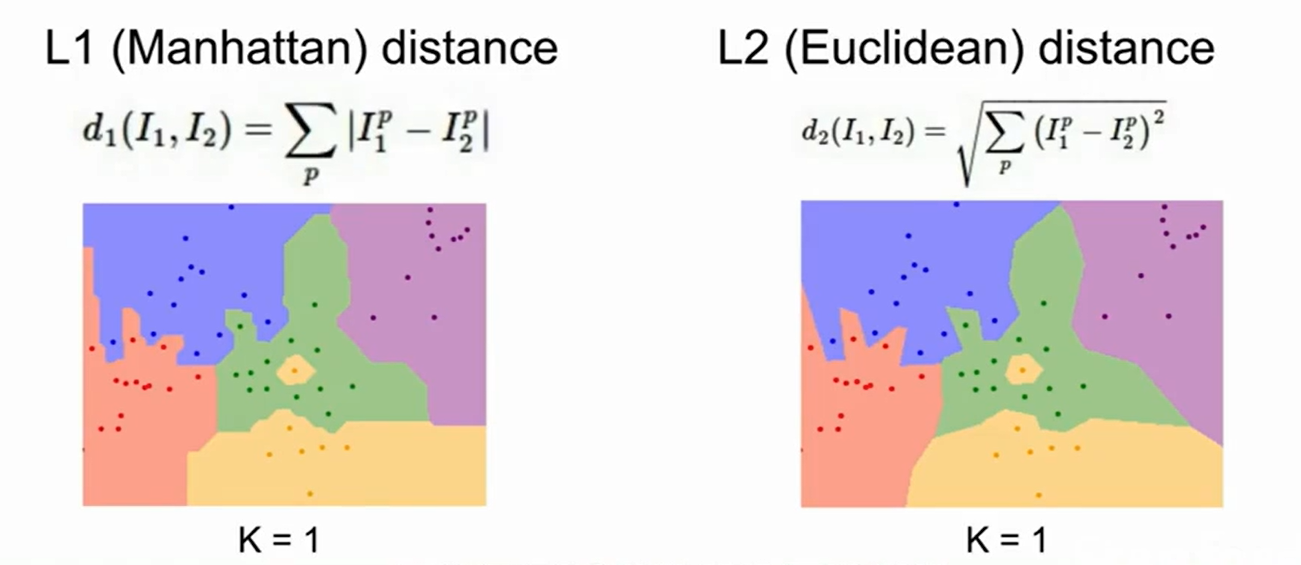
L1的决策边界趋于跟随坐标轴,这是因为L1取决于坐标轴的选取,而L2和坐标轴无关。
超参数(Hyperparameters):

超参数是我们需要自己选择的,而不是算法学到的,比如K值的选择。
超参数的设置:

总是选择对训练集最好这是一种很不好的想法,比如KNN中你就总会选择K=1,而这样会造成过拟合。因为这在测试集上会表现得很差。因此我们更应该关心在测试集上的表现。

那么我们既然不可以再训练集上测试,那我们就在测试集上测试。这其实也是欠妥的,那我们就不知道在新的数据上的表现如何了(因为没数据了)。

最好的方法应该是做validation,把不同的超参数用train set训练,在validation set上测试哪儿个超参数表现得最好,然后把最好的超参数+model 去测试test set。
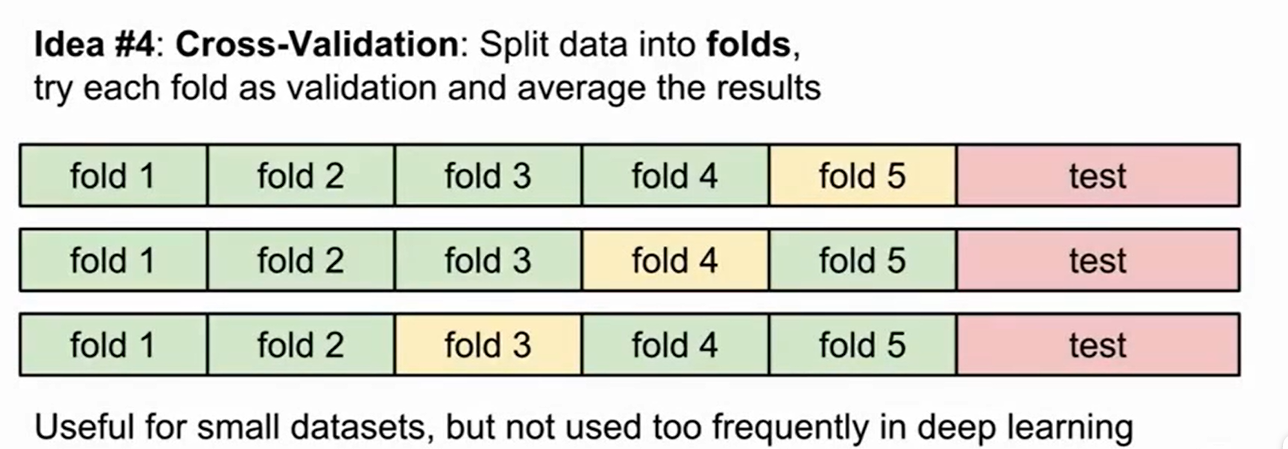
还有一种cross-validation的方法叫做V-Fold Cross Validation,把训练数据集拆成V份,如上图,拆成了5份,绿色部分代表训练的数据,黄色的用不同的超参数来测试的数据。下面同理,找出平均表现最好的超参数。最后用这个最好的超参数+model 去测试test得到真正的表现。值得注意的是,这种方法同样有缺点,那就是在深度学习中数据往往非常大,因此这种多次检验的方法十分耗时。
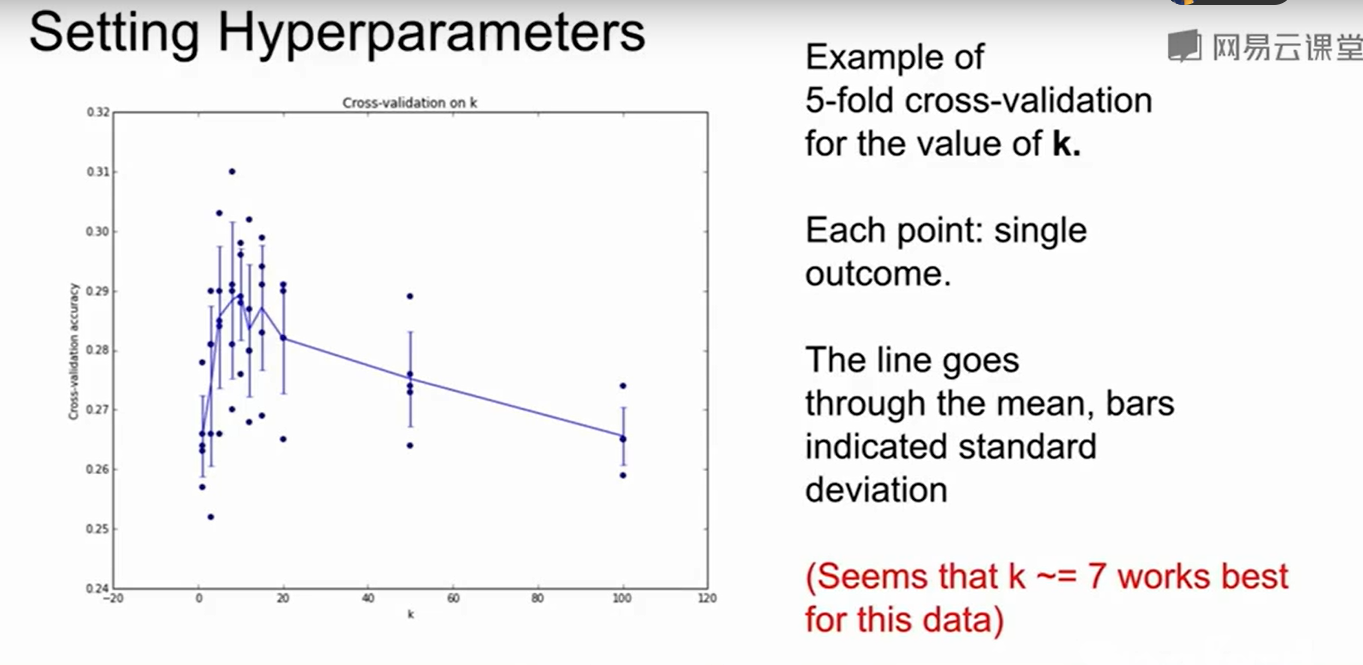
如上图,cross-validation告诉我们K=7时表现较好,此时validation很好的帮我们选择了超参数。

KNN在图像上是几乎不会用的,原因有:
- 非常慢,需要和每一个训练样本比较
- 我们对同一张图片做遮挡/平移/染色 仍然会被认为一类,L2不太适合作为视觉差异。

线性分类(Linear Classification)

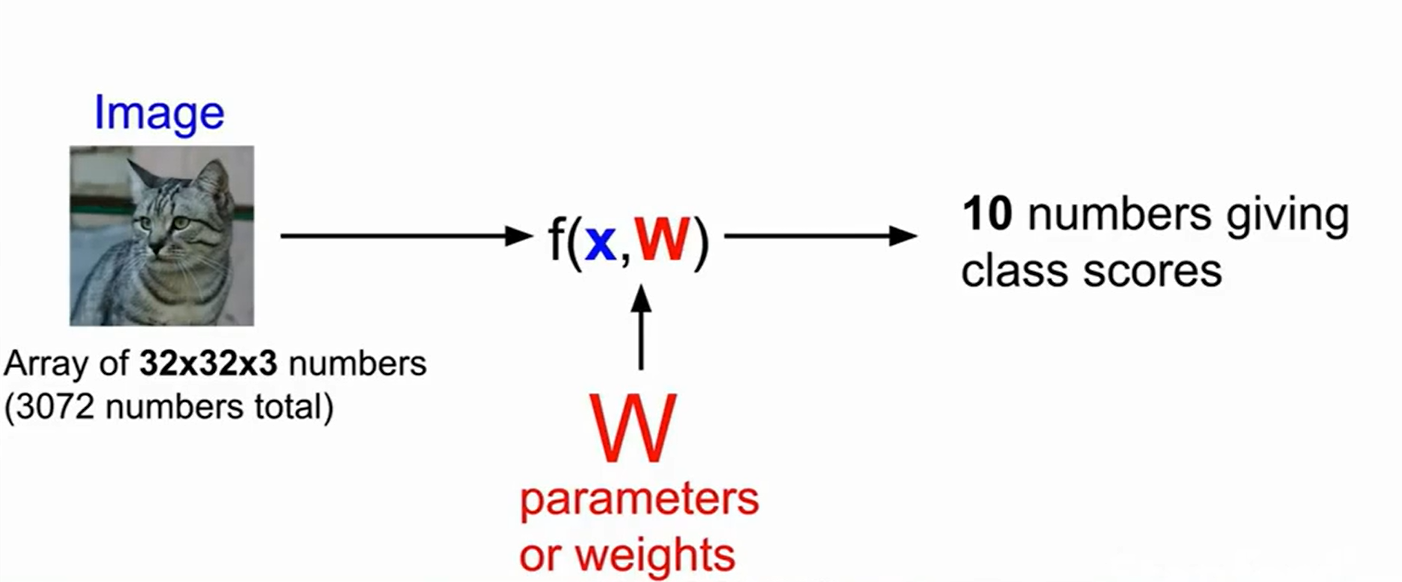
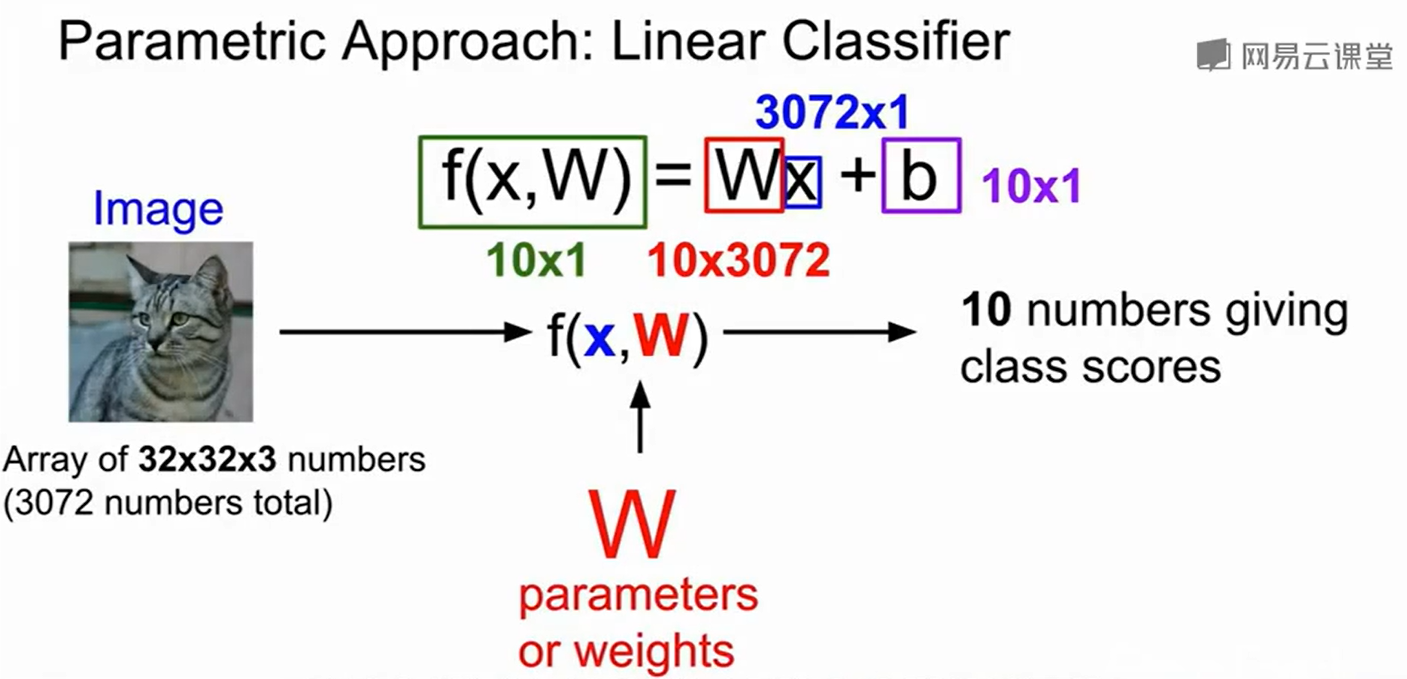
最简单的一个线性分类器就是$f(x,W)=Wx+b$,我们可以得到十个维度的分数(即十个物种的分数),分数最高的就可以把他归属到那一类。
举个例子:
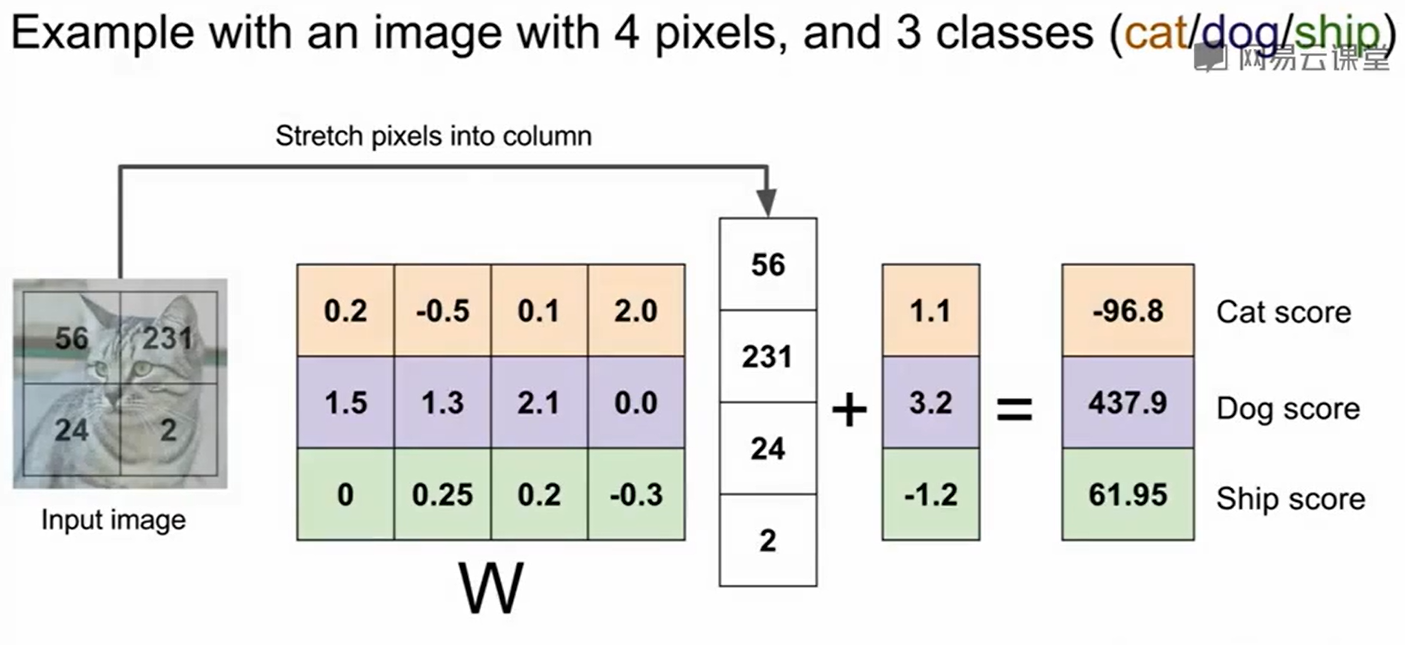
但这样的方法局限性也很明显,下图给出了线性分类学到的W在图像上到底长什么样:

比如第一个plane是蓝色的,这会让图像识别认为蓝色多的就是飞机,第二个car红色车身上方有蓝色挡风玻璃,然而这种判断太过于没有说服力。
所以linear classification只是对每一个类别学了一个模板,如果一个类别的东西有多种类型,那么一个模板似乎并不能很好的预测。
现实中的许多数据可能不能做到线性可分,即使他是从同一个分布取出来的数据。
下一次我们会讨论:

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!