CS231n-CH8-循环神经网络
循环神经网络
后面补一个专题梳理一下这一节:to do..
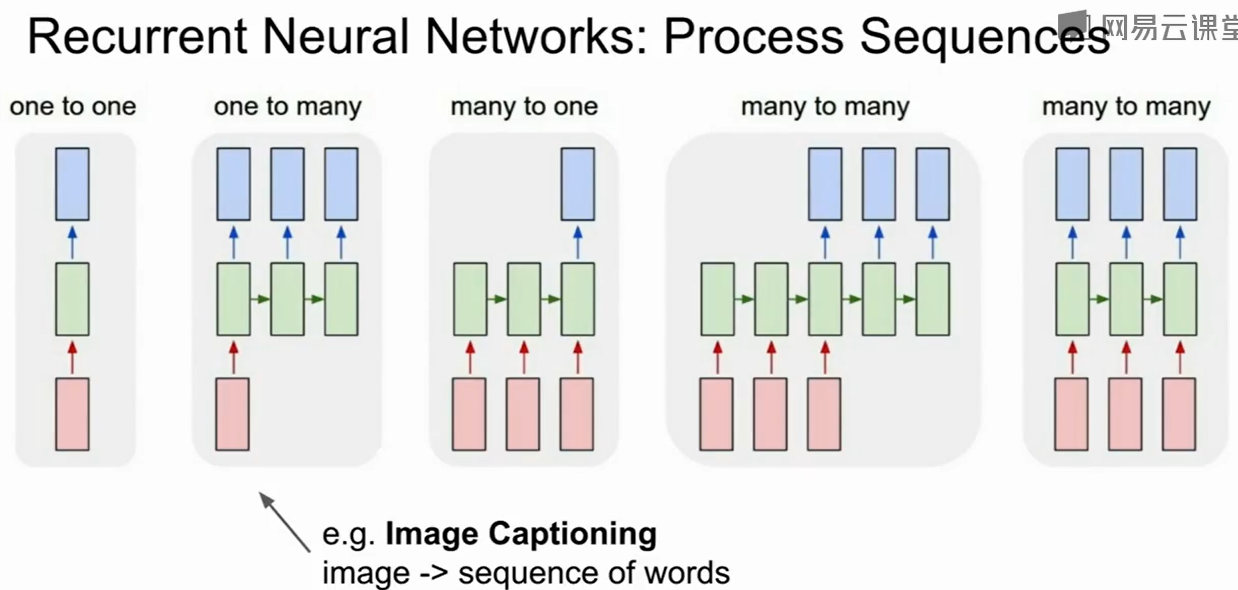
原来的CNN是1对1的模型,即输入是固定的大小,输出也是固定的大小。
而RNN可以是:
1对多:输入一张图片,输出对图片的理解。
多对1:输入一段文字,输出情感。或者输入一段视频,输出视频中所作的决策。
多对多:翻译中输入可变,输出可变。
RNN主要用于处理大小可变的有序数据。
但实际上RNN也可以处理一些输入大小固定,输出大小固定的问题。

比如手写数字识别,他不是单纯的做一个前向传递然后把识别结果返回出来。而是观察一组图片,看看这些图片的各种不同部分,在完成这样的一组观察后再得出识别结果。
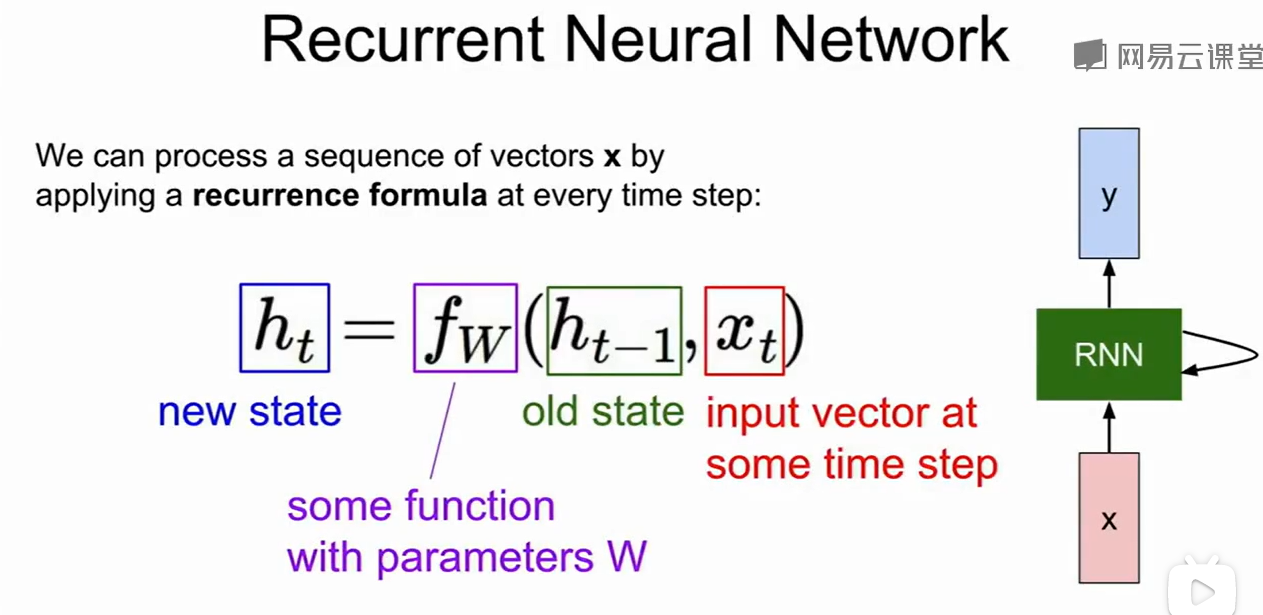
这个$fW$相当于途中的绿色模块,他对old state$h{t-1}$和当前输入的状态$x_t$做运算得到下一个隐藏态$h_t$

比如:上例就是$h_t$首先不断更新,最后得到$h_t$,然后做一个全连接层得到的$y_t$
我们把这个计算过程展开会更好的理解RNN是如何处理序列的:
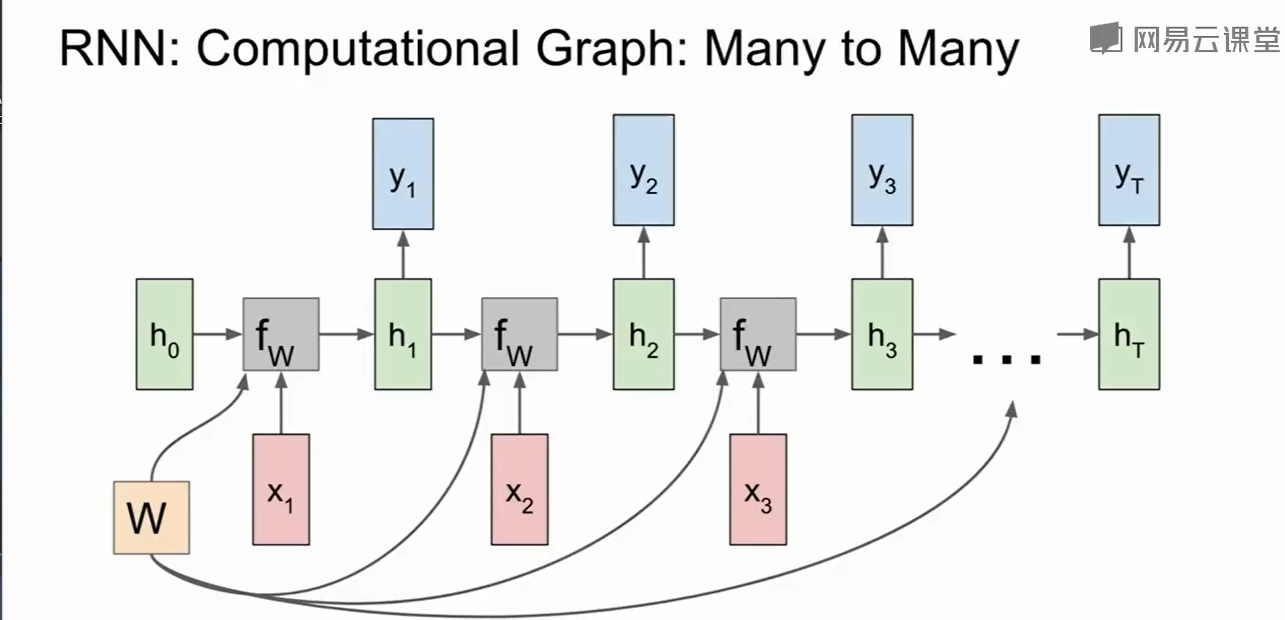
这样我们就可以预策每个时刻的$y$了。
同时我们可以把每个时刻的loss和总共的loss加上去:
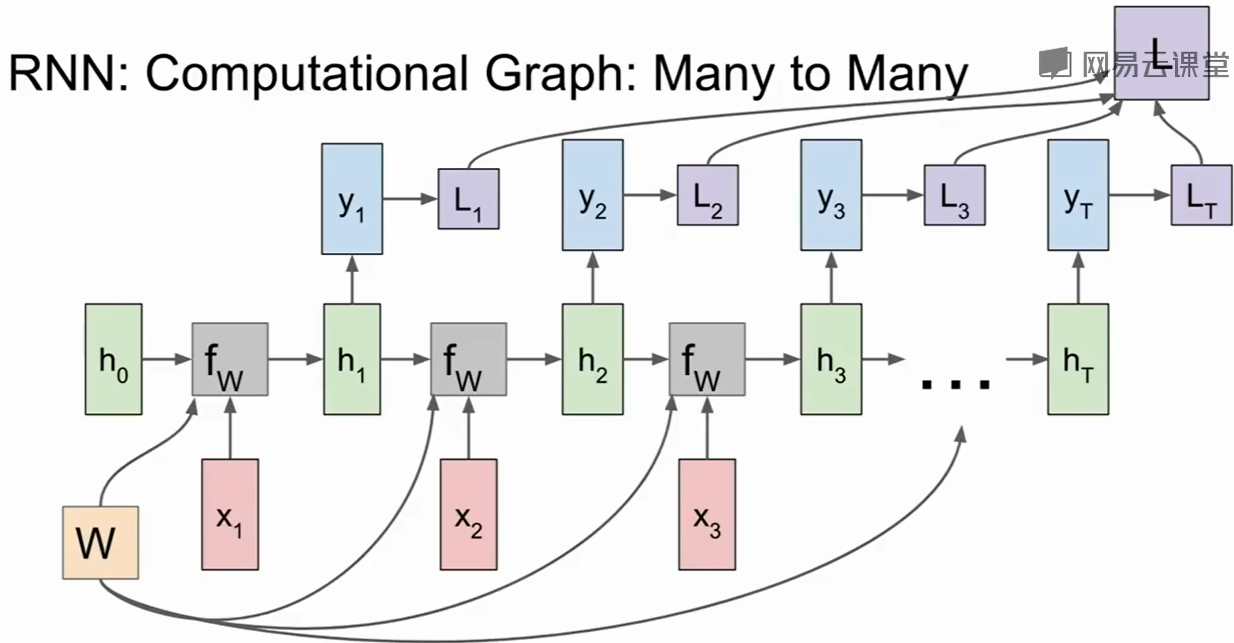
当然如果哦我们在做多对一的任务,比如给出一段文字/视频,输出表达的情感,那么只需要最后的输出即可:
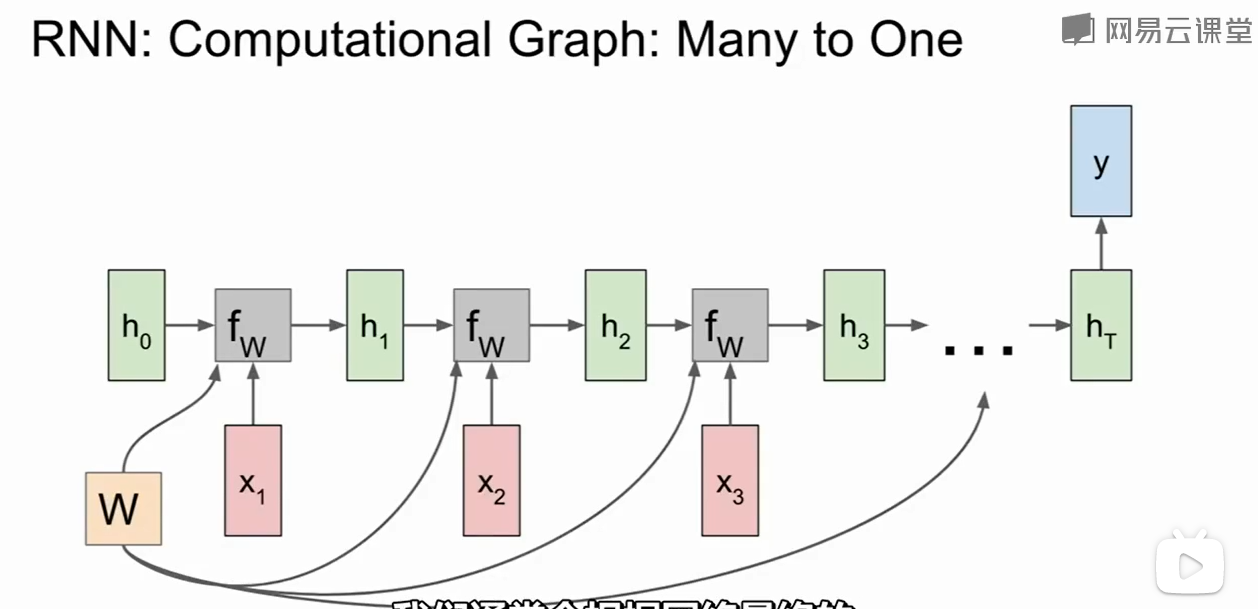
当然还有1对多问题的结构:
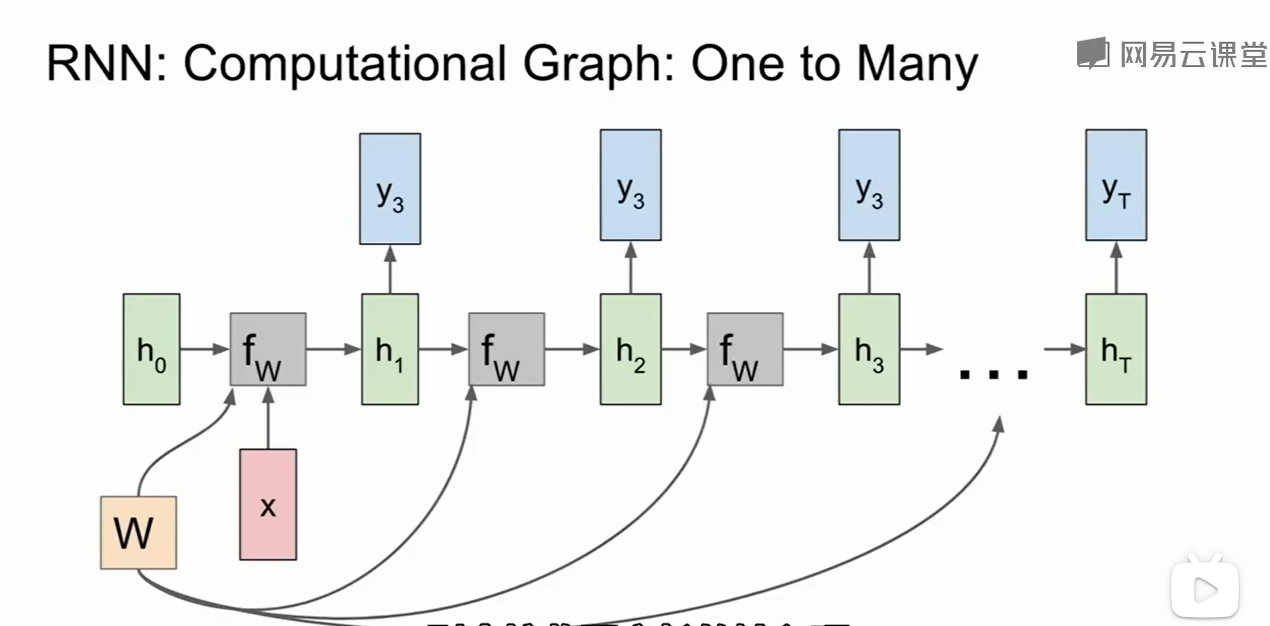
Sequence to Sequence结构是一个多对一 和 一对多组合的情况:
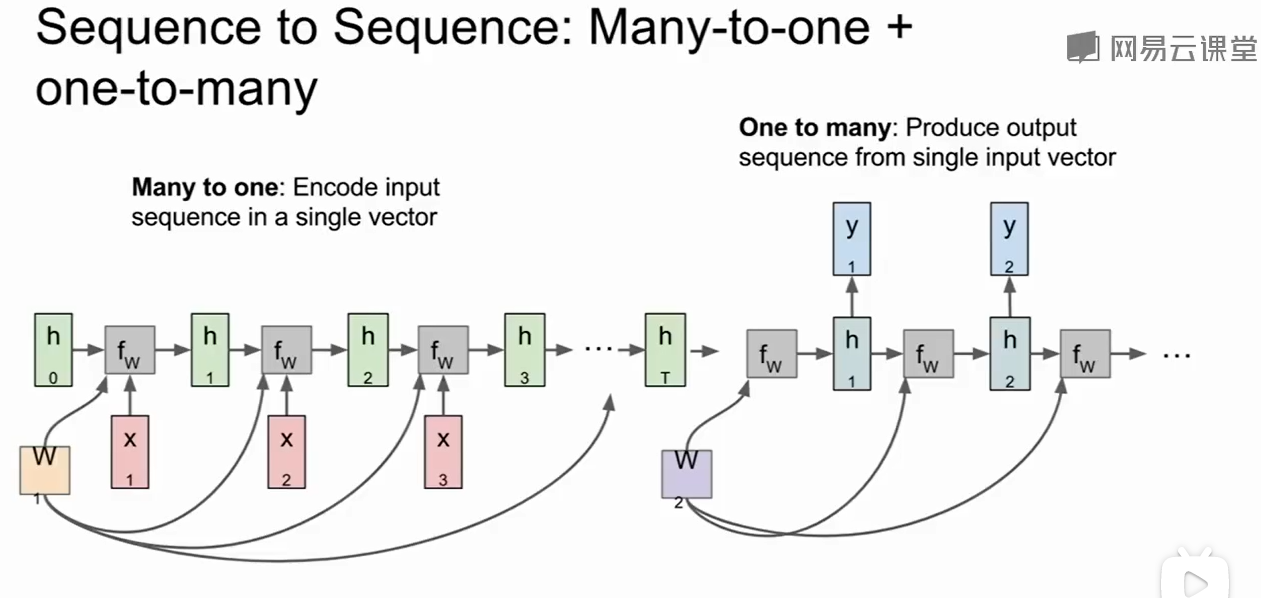
可以理解为输入一段文字得到一个表达,然后表达在转化为一段文字,多用于翻译中。
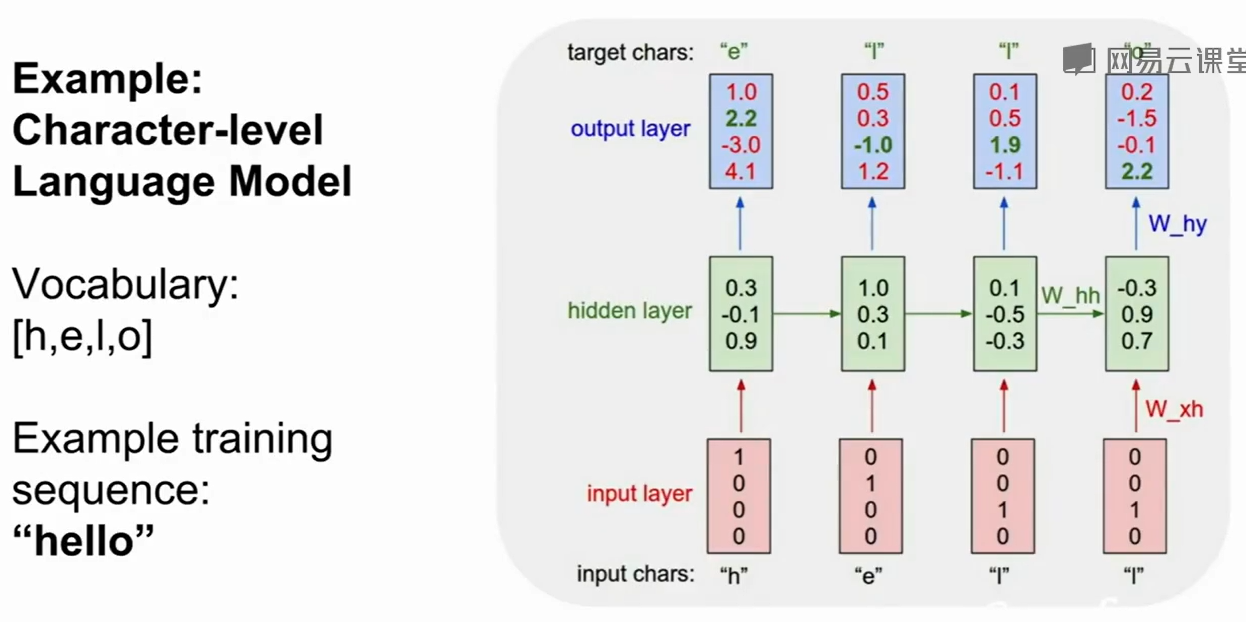
一个预策hello的例子,上图是训练阶段:
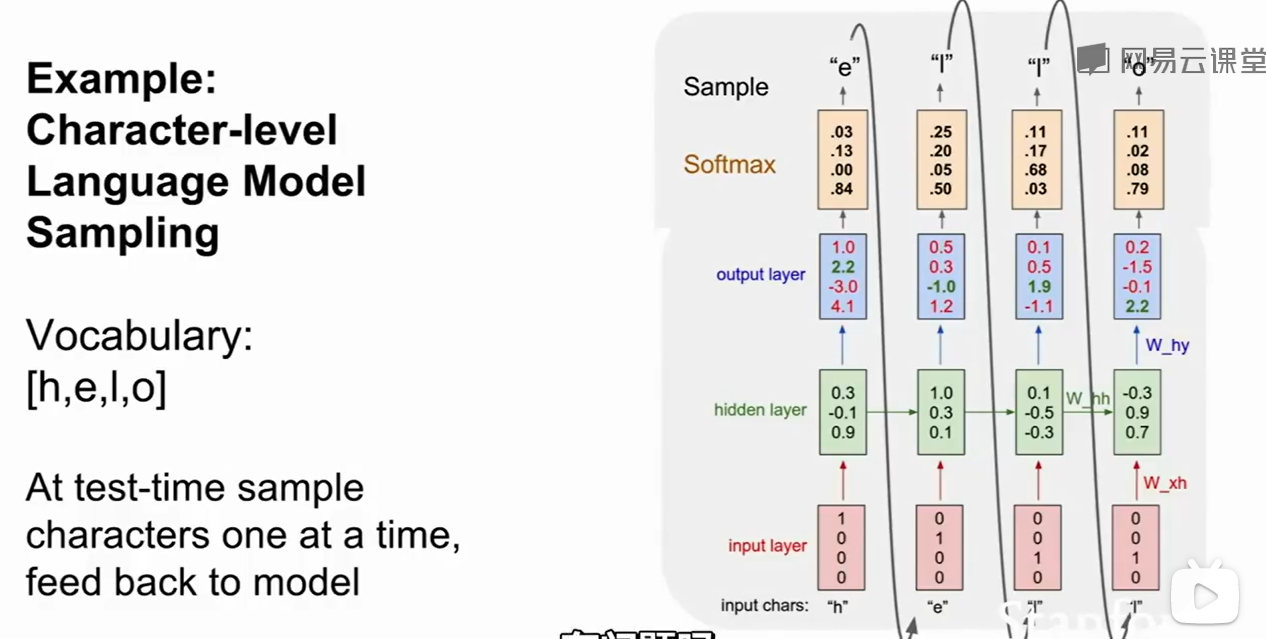
测试阶段,我们需要把softmax的得分变成一个概率分布,然后再抽取字母。
这样做的好处是,想象prepare,prescent这两个单词的前缀 都是pre,如果我们只选择得分最多的作为结果,那么结果就会过于单一,如果采用概率来抽样,那么prepare和prescent都有机会被学习到。这使得我们的输出结果更加多样化。
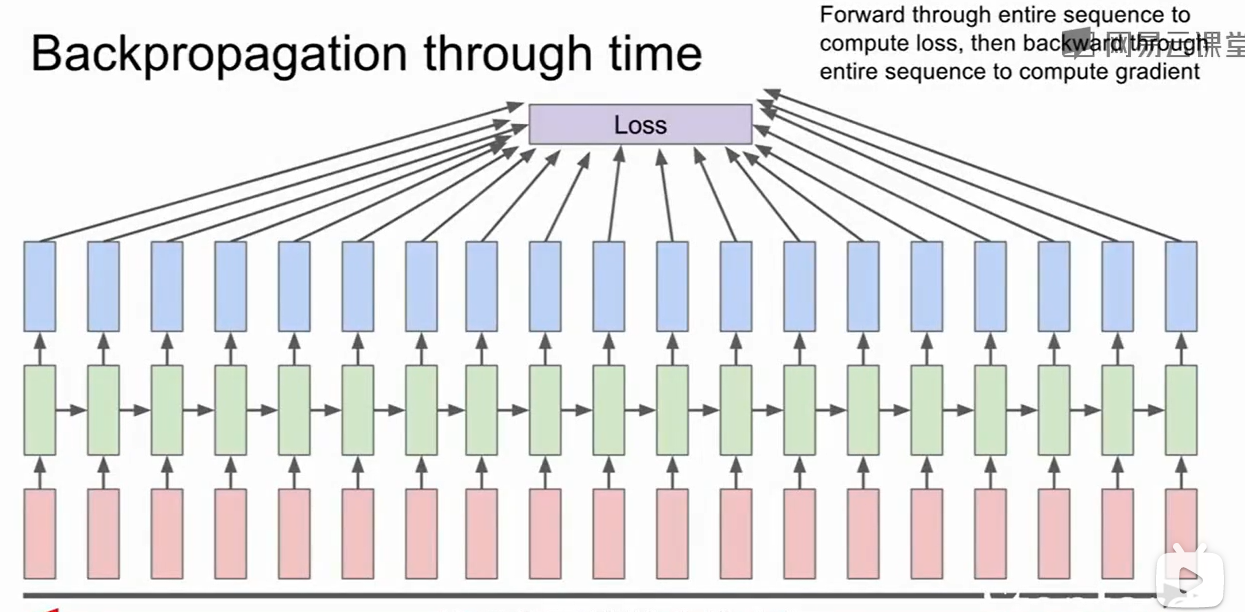
上图这种训练方法是很难训练的,因为我们需要把所有的loss算一遍返回总的loss,然后算梯度再更新,这样迭代一次却需要把整个全部计算一次,同时这也会导致内存不够。
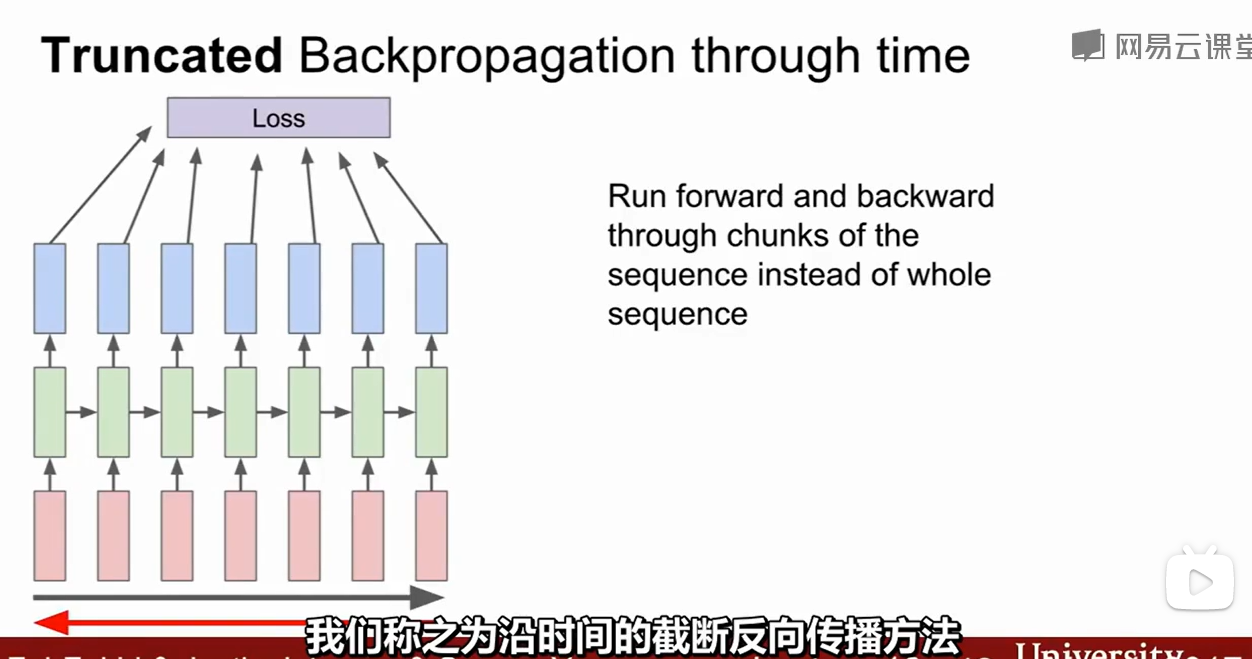
一种Truncated Backpropagation through time(TBPTT)的方法把很长的序列分解为每几十个一组。
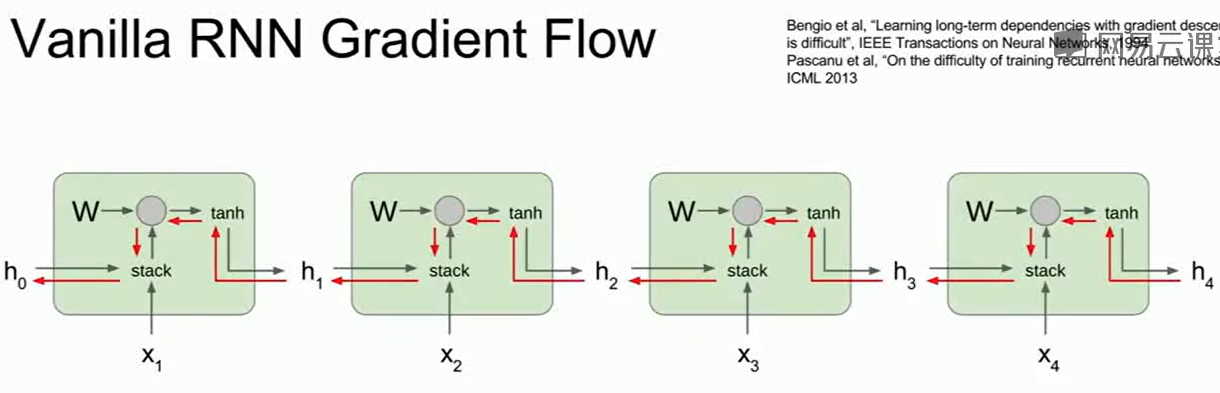
对于RNN这样的网络,是很容易出现梯度爆炸/梯度弥散的:
对于梯度爆炸可以用梯度阶段(Gradient clipping)来解绝:
如果梯度的L2范数大于某一个阈值,就把他截断并做一个缩小的除法。

而对于梯度消失,一般我们会选择一个换一个更好的RNN结构来做,这也是LSTM出现的原因。

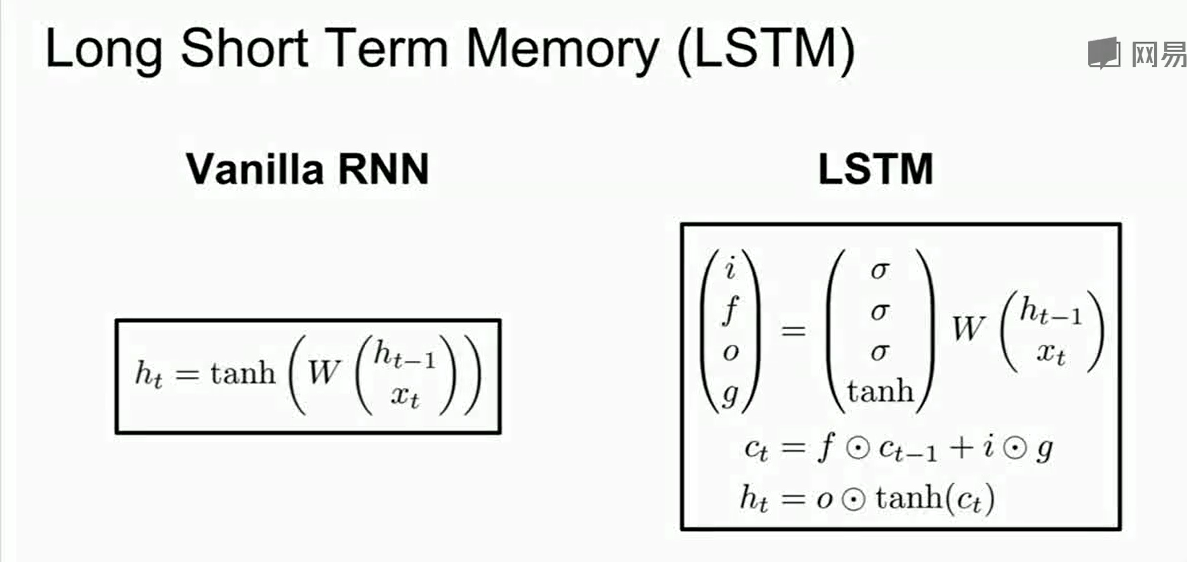
LSTM中有两个hidden state(隐藏状态),一个是和vanilla RNN一样的$h_{t-1}$,另一个是$c_t$称为cell state。这个cell state类似于保留在LSTM内部的隐藏状态。
计算时首先我们可以计算出$i,f,o,g$ 的值,然后用这些值去更新$c_t$, 然后再用$c_t$计算处next step的$h_t$.
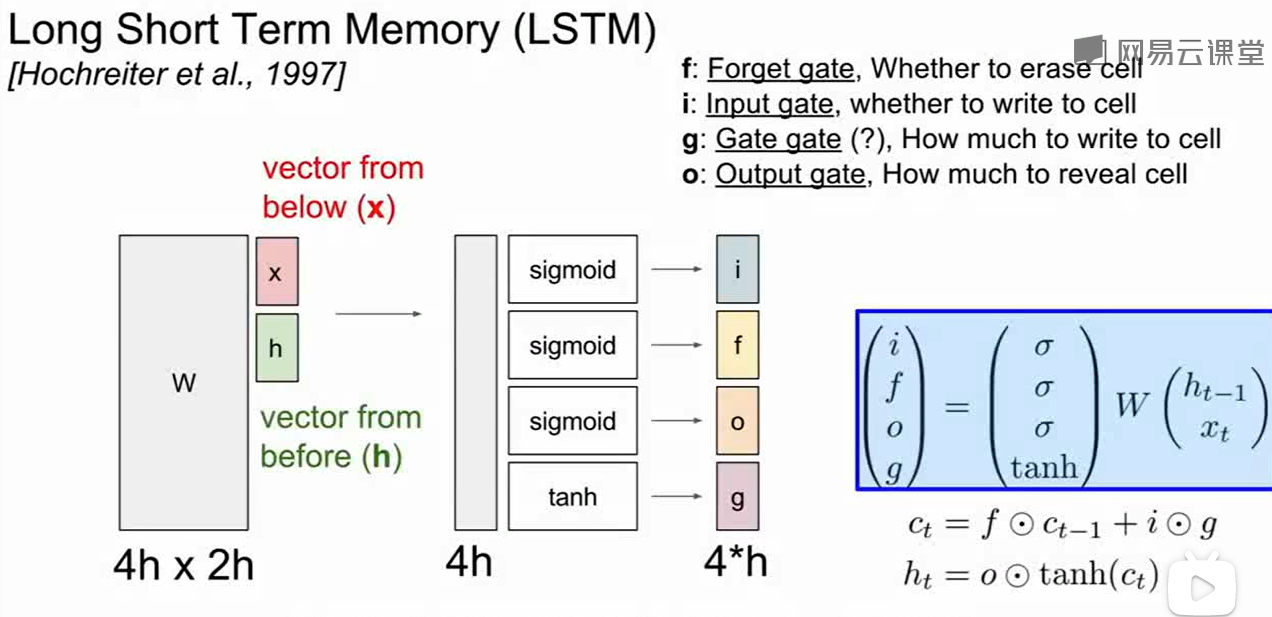
$i$:input gate,输入门,表示神经元要接受多少新的输入信息
$f$:forget gate,遗忘门,我们要以往多少之前的神经元记忆
$o$:output gate,输出门,表示我们要输出多少信息给外部
$g$: Gate gate,表示我们想让input神经元有多少信息
$i,f,o$的范围由于sigmoid导致范围是0-1,而$g$的范围由于tanh的作用是-1到1.
其中$f$ 为0说明我们想要忘记上一个cell state的值,是1说明要记住。
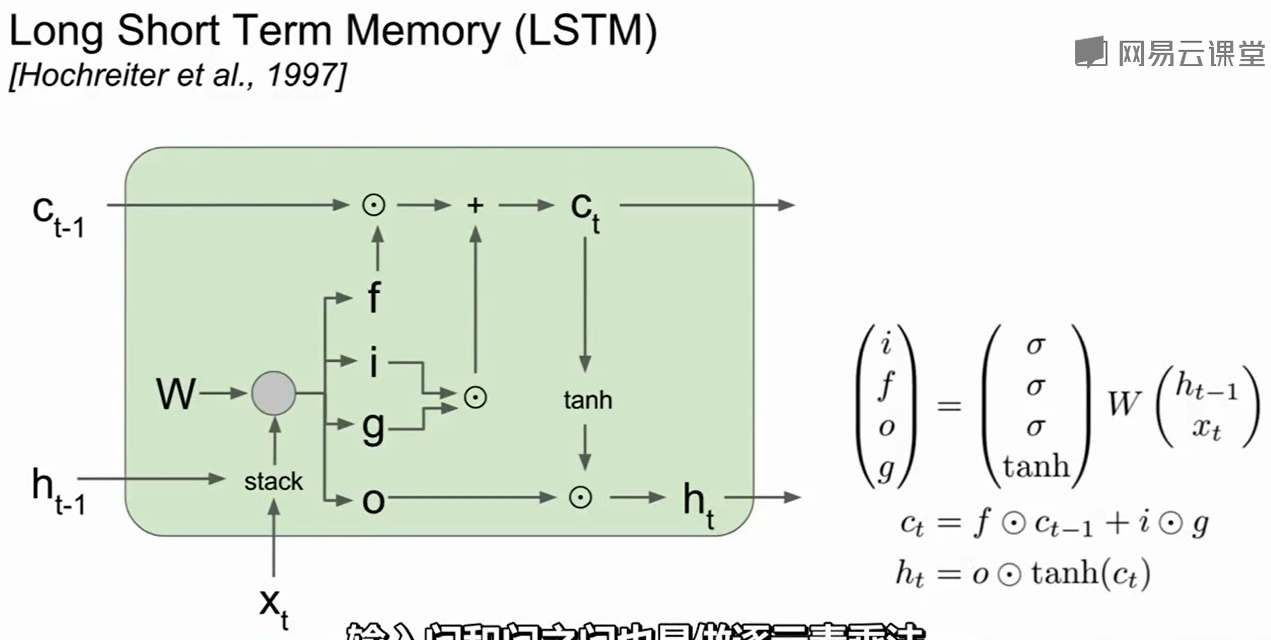
一个具体的结构图:
LSTM有两个好处:
LSTM做bp时通过forget gate时是逐元素相乘,这比矩阵乘法快很多
LSTM会在不同的时间乘以不同的forget gate,而在vanilla RNN我们只会不断乘一个不变的$W$,这就很容易导致梯度爆炸/弥散。
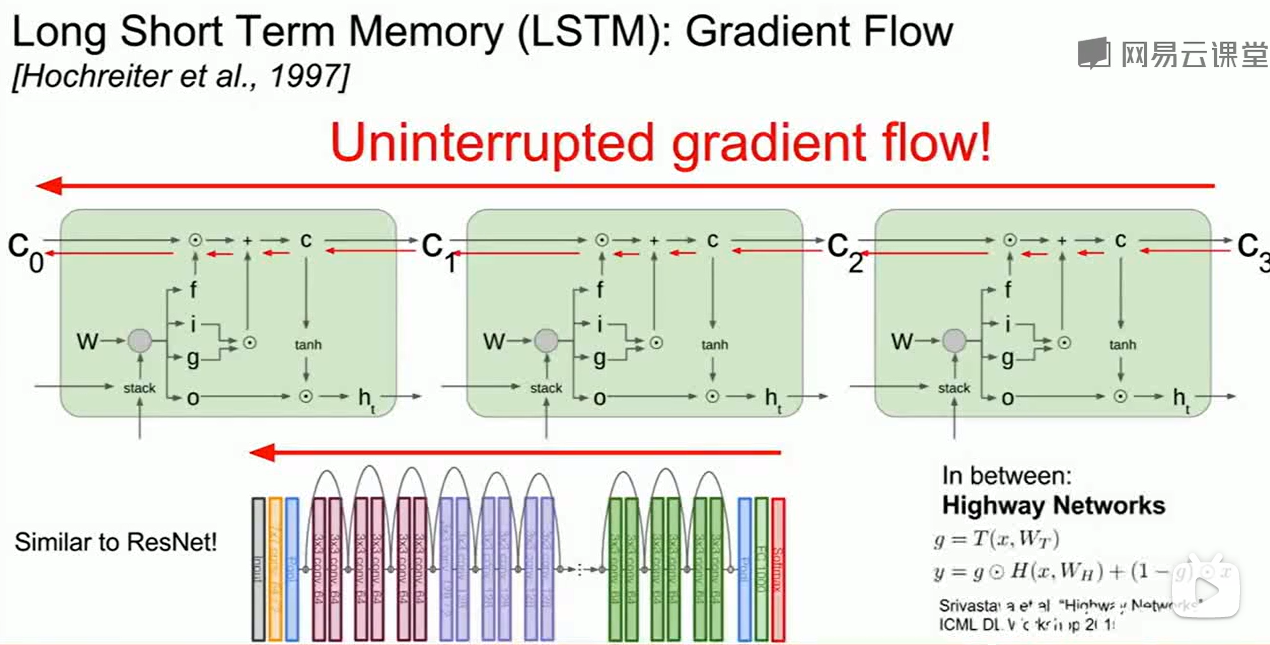
和ResNet类似,LSTM也为网络提供了一个快速进行反向传播的通道。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!