强化学习纲要Ch7-价值函数近似-下
价值函数近似—下

- 线性组合的前提是需要我们设计出很好的feature
- 我们可以用非线性的函数拟合,常用的方法就是:DNN(Deep Neural Network)
现在DRL的一个大致情况:

DNN用来拟合价值函数,策略函数和环境模型
Loss function可以通过SGD来做梯度下降
- 目前的挑战:1.效率问题,参数太多 2.deadly triad
Deep Q-Networks(DQN):
DQN通过神经网络拟合了action-value function(q函数),同时在Atari游戏上表现出色。
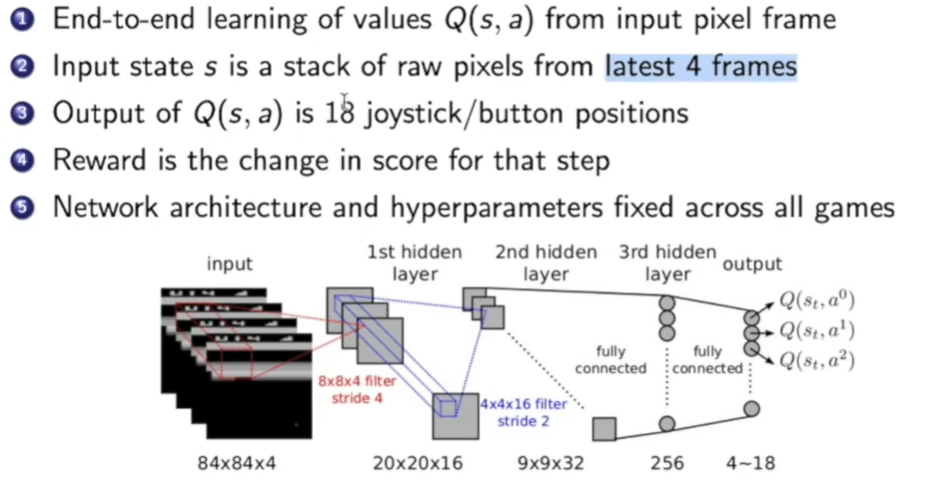
- 端到端学习
- 输入是四帧图像
- 输出是18个操作
- 对游戏直接增减的分数作为奖励
之前Q-Learning学习中很难克服两个问题:
我们用的是监督学习 ,需要i.i.d的数据,而因为输入是相邻帧,关联性很高
网络学习q或者v需要bootstraping迭代,每次都把td target作为标签通过监督学习拟合,td target是变的,导致了
那么DQN是如何解决上面这两个问题的呢?
- Experience replay
Experience replay这种方法用了一个容器replay memory $D$来存储$(st,a_t,r_t.s{t+1})$.
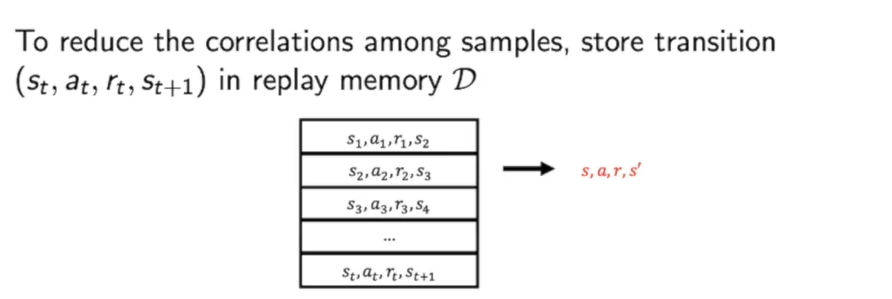
然后在对$D$进行采样,利用采样得到的来构建TD target,进一步就可以得到所拟合的Q函数的梯度。

因此这种方法把不同轨迹的数据集合在一起,抽样训练,降低了相关性。
- Fixed Q targets
解决的方法是通过一个$w^-$ 来替代TD target中的$w^-$。这个$w^-$是几轮迭代前的$w$,这样我们就可以求梯度时忽略原来TD Target第二项w不求导造成的问题。

更新方法如下:

这里周博磊老师给出了一个直观的解释:

老鼠相当于我们的target function,老鼠每动几步,猫才会行动一步,这样就可以更好的看准target来优化。原来TD Target每次都会变化,这会导致目标一致变化导致拟合困难。
DQN近些年的一些进步工作:

Double DQN Paper Link
Dueling DQN Paper Link
Prioritized Replay Paper Link
还有一个非常有趣的是Agent57,是去年五月刚发的一篇文章,可以理解为把许多改进融合了起来 。 Blog Link
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!