RPN(Region Proposal Network)介绍
RPN(Region Proposal Network)
RPN简单来说就是输入一张图片可以得到很多待选框的一个网络,再详细一点就是:
RPN的本质是对所有候选框进行判定,前景概率为多少,如果是前景那么其候选框所需要的修正因子应该是多少。
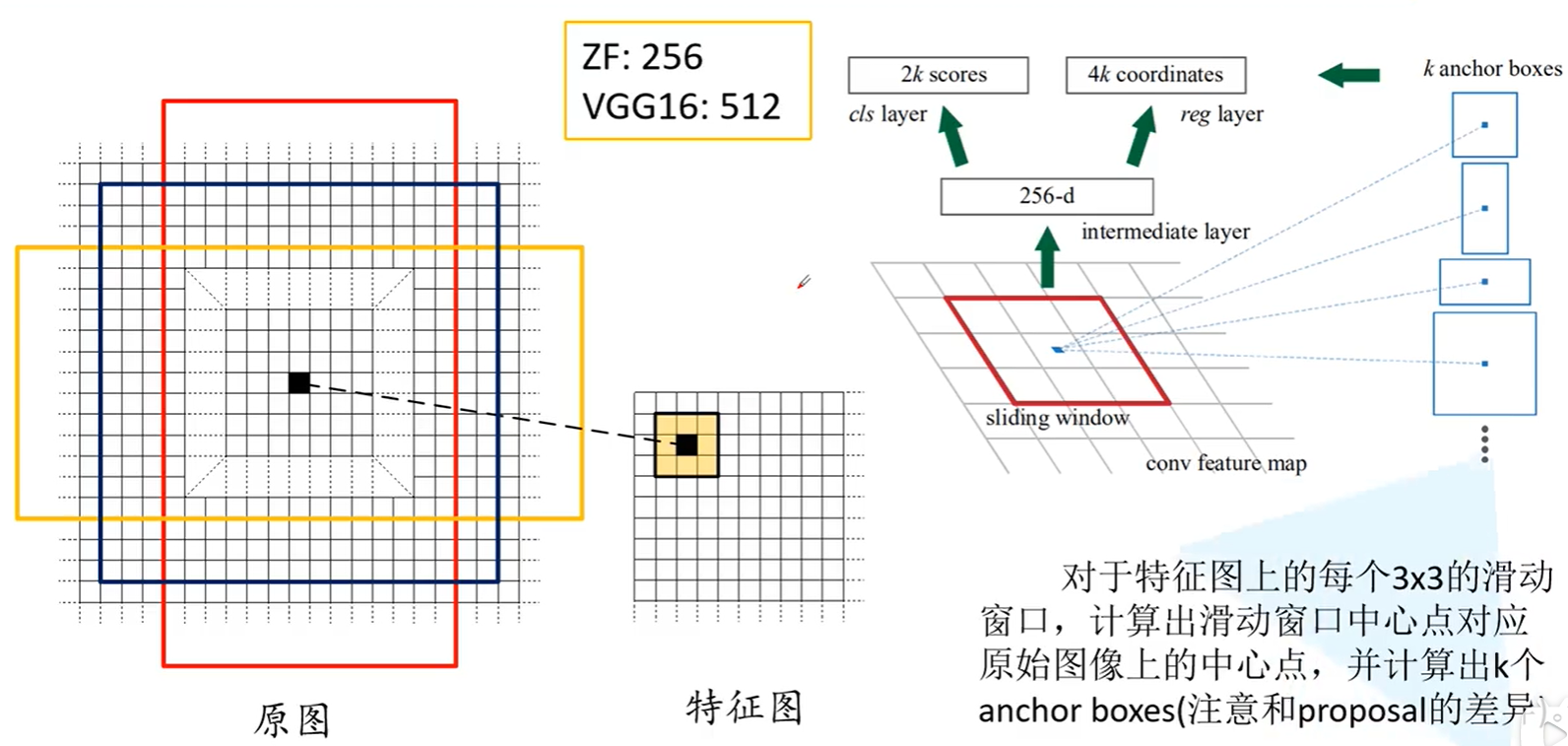
首先经过backbone提取特征:
首先拿到一张原图时,我们要先利用backbone获得feature map,可以看到上图中右部从feature map中获得了一个256维的向量,这个256来自于哪儿里呢?其实就是feature map的深度,而我们的backbone是ZF时,提取出的feature map深度就是256的。官方也提到可以用VGG16来当作backbone,这样得到的feature map深度就是512的了。当然上图举的例子是ZF做backbone时的情况。
同时也要注意获得256维向量是通过滑动窗口获得的,即3*3的滑动窗口扫面feature map的每一处,padding 1个,步长也是1, 就正好覆盖了feature map。
找出anchor box:
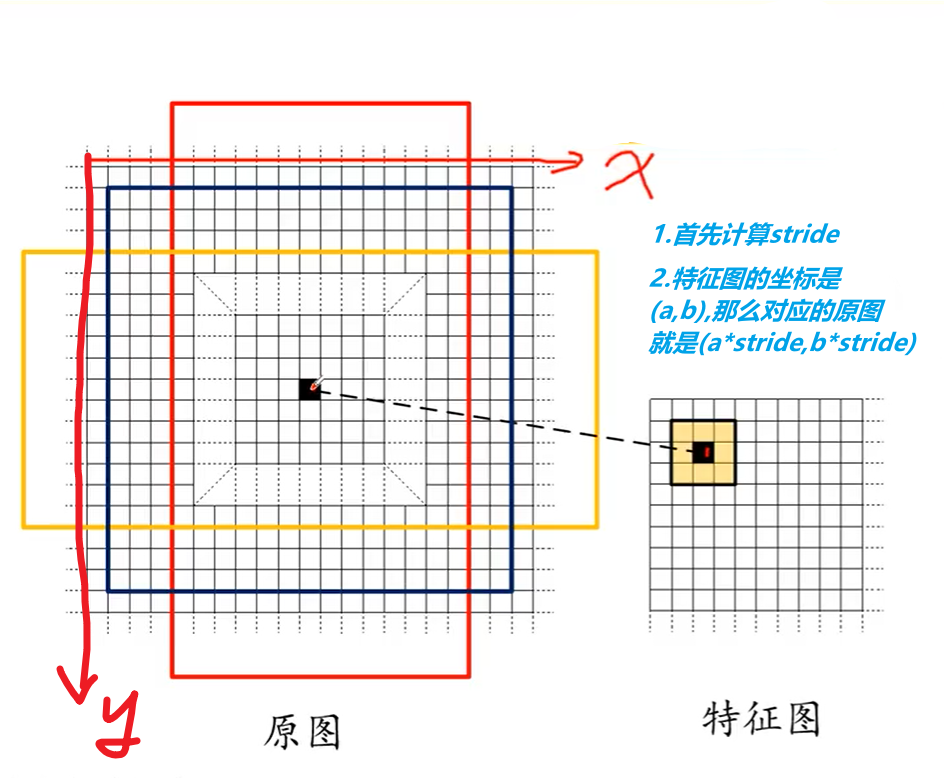
feature map上的每一个点都可以映射回原图,映射方法如下图,首先计算$x$方向上的$stride_x$,$y$方向上的$stride_y$,这两个是怎么计算的呢? 举个例子,比如输入的图像是500*600的,经过backbone得到的feature map大小是100*150,那么$stride_x = 500/100 = 5,stride_y =600/150=4$。 此时我们查看feature map上每个点$(a,b)$映射回原图的坐标就是$(astride_x,bstride_y)$。
找到原图坐标后,在原图出画出k个anchor box:
作者给出了九种的anchor box:
1 | |
其中每行的4个值 $(x_1,y_1,x_2,y_2) $表矩形左上和右下角点坐标。9个矩形共有3种形状,长宽比为大约为$1:2, 1:1, 2:1$三种,实际上通过anchors就引入了检测中常用到的多尺度方法。在代码中,作者把任意大小的输入图像reshape成800x600。然后再用九个anchor box来包围,其实就几乎覆盖到了各种各样尺度的目标。
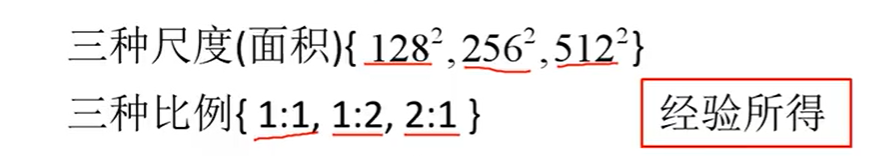
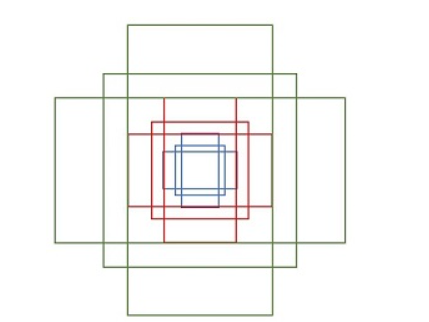
到此Anchor box就找到了
调整anchor box:
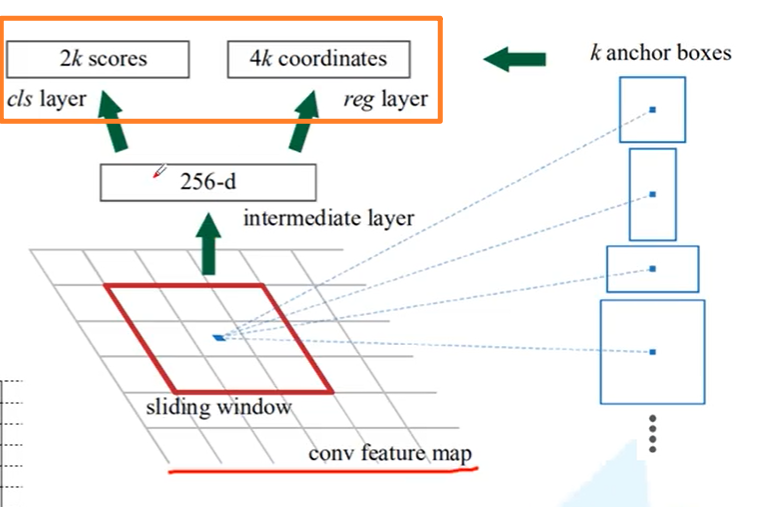
除了刚才介绍的结构,这里还一个$2k\ score$和$4k\ coordinates$。 这两个就是对anchor box进行调整的。对于feature map的每一个点都会在原图生成$k$个anchor box。
- 每个anchor box都有2个概率,即是背景(无目标物)的概率和是前景(有目标物)的概率, 所以每个点有$2k$个score
- 每个anchor box都有4个回归参数,即是包围框的左上角点和包围框的长宽,所以每个点有$4k$个coordinates,帮助我们调整anchor box的位置与大小。
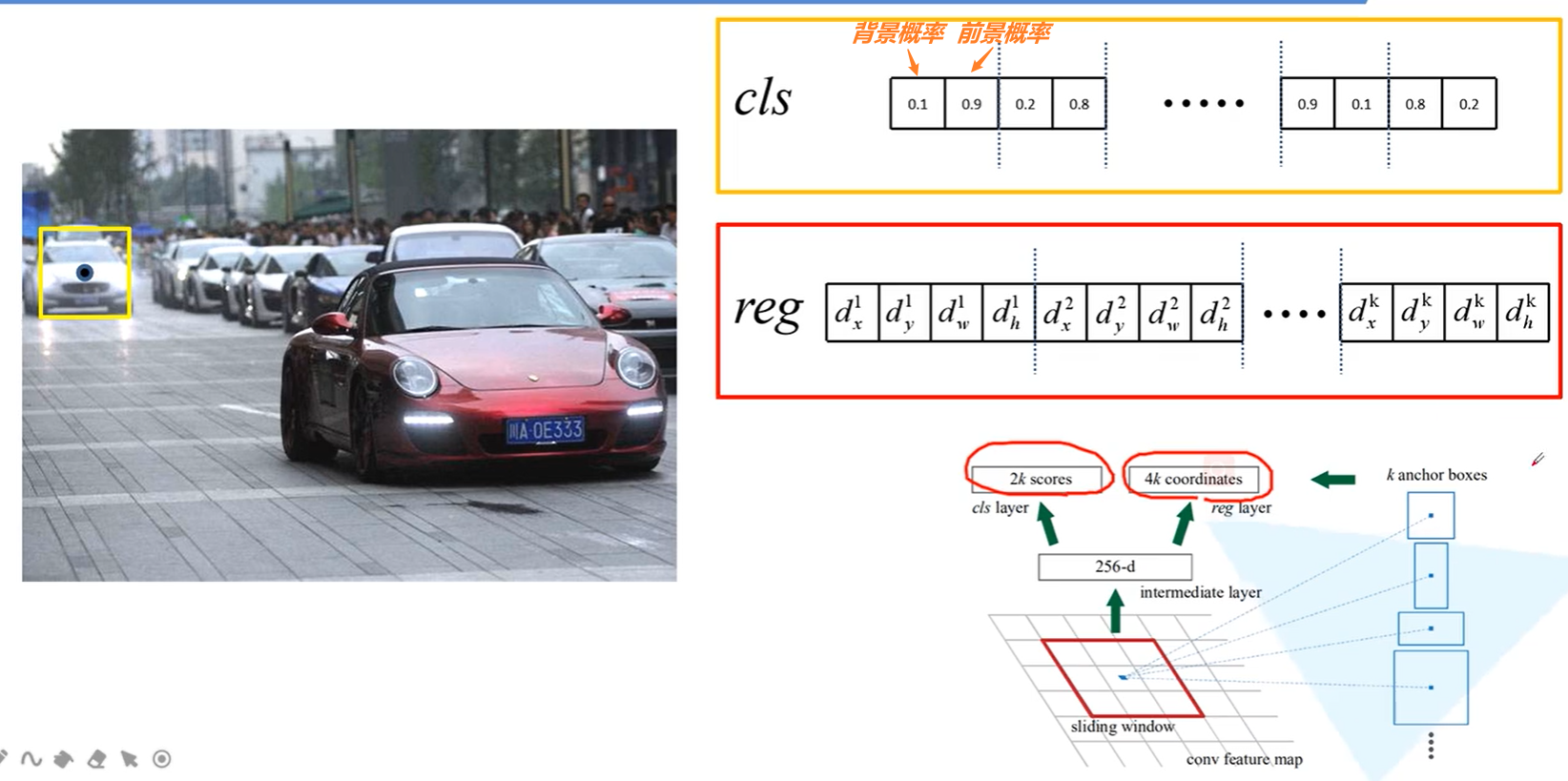
请注意RPN网络找的目标可以有多个,因此我们只区分是前景概率和是背景概率,我们在RPN中并不关心这个到底是前景中的哪儿一个目标。举个例子,想获得人和车的预选包围框,车和人都算是前景。
感受野问题:
- 对于ZF网络作为Backbone,他的感受野是171。
- 对于VGG网络作为Backbone,他的感受野是228。
那么这就有一个问题,我们在feature map中的每一个点要映射回原图,而你的感受野只有171*171这么大, 为什么anchor box要有256*256,甚至是512*512这么大的?
作者给出的看法是:

即感受野小于实际物体的包围框是有可能的,因为我们人也可以看到物体的一部分就大概猜出物体的整体大小。实际中,这个方法也确实是work的。
减少候选框:
- 对于1张1000*600*3的图像,大约有60*40*9个anchor
- 忽略跨越边界的anchor,大约剩下6k个anchor
- RPN生成的候选框存在大量的重叠,基于候选框的得分,采用非极大值抑制,IoU设置尾0.7,最后只剩2k个候选框。
请注意上面的anchor和候选框不是同一个东西,anchor经过4k个回归参数的调整后才叫候选框。
RPN训练方式:
RPN每次从待选anchor中抽取256个anchors,每次让正负样本比为1:1。如果正样本少于128,假设为x,那么我们就让负样本为256-x。
这里是怎么定义正负样本的呢?
正样本: 我们的anchor与ground-truth box最大的IoU>0.7,那么就可以认为是正样本,如果最大的都不大于0.7,那么我们就把IoU最大的Anchor作为正样本即可。
负样本: 我们的anchor与所有的ground-truth box的IoU<0.3,那么就可以认为是负样本。
正负样本之外的我们就会丢弃掉。
loss函数:
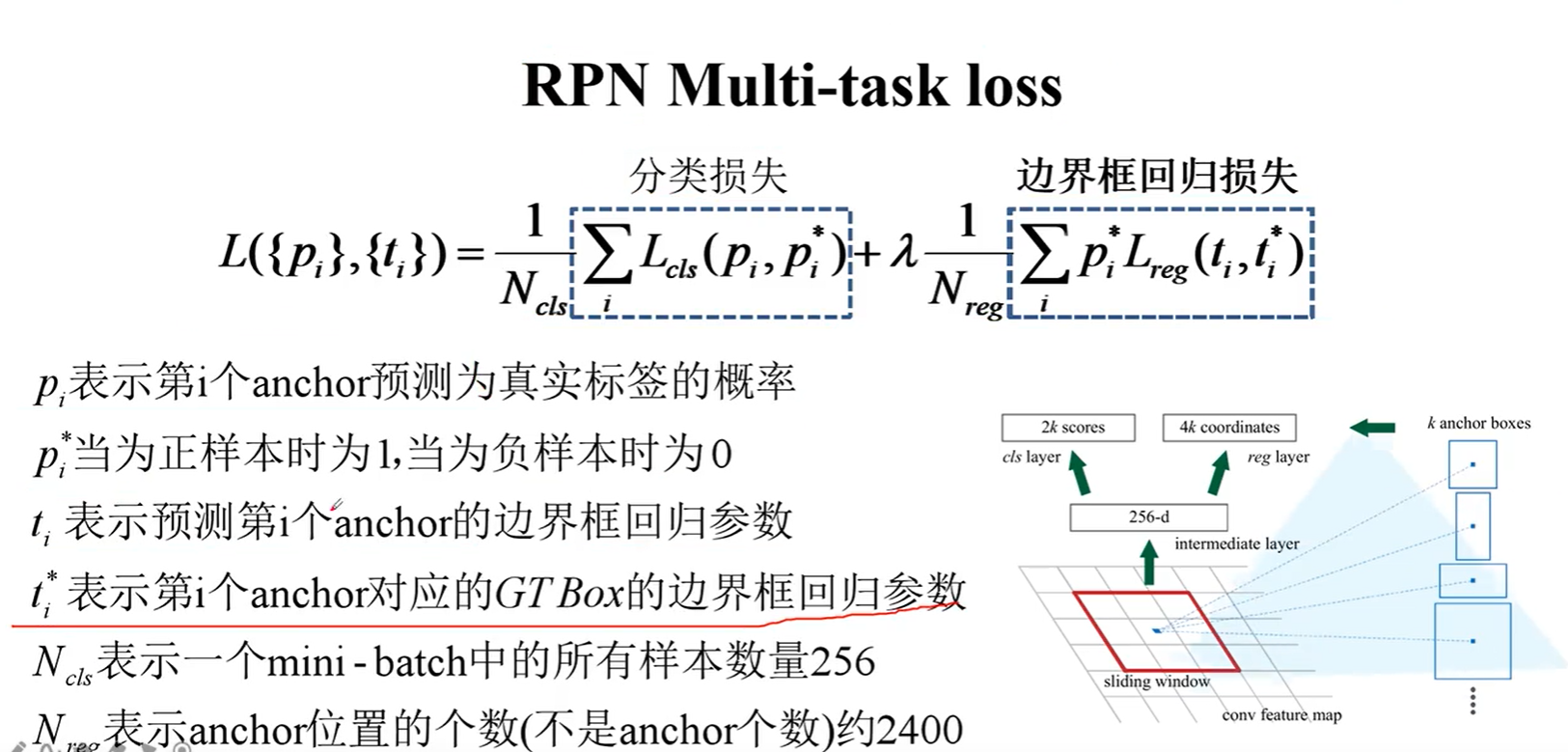
分类损失函数:
首先说分类损失,原文给的是Softmax Cross Entorpy Loss来计算的:
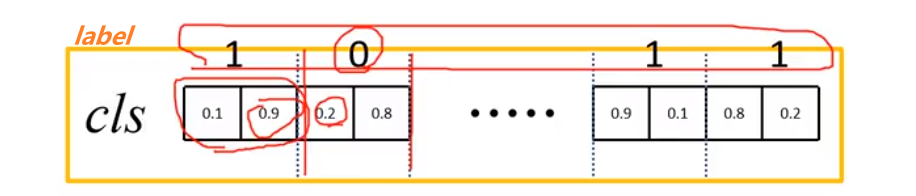
1代表是前景,0代表是背景,那么:
比如第一个anchor实际是前景,而预测前景概率是0.9,那么$L = -log(0.9)$,第二个是背景,而背景概率是0.2,那么$L = -log(0.2)$。
在pytorch官方实现的方式是用二分类的交叉熵损失Binart Cross Entropy:
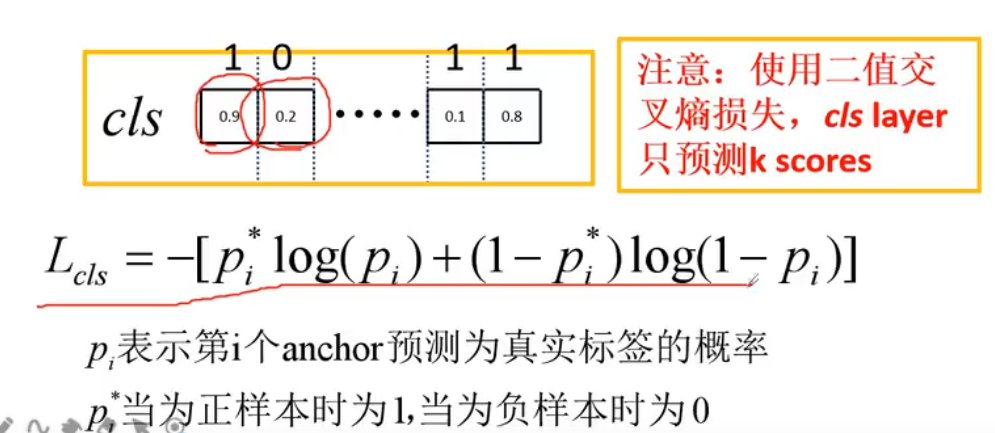
也就是说这里只需要预测K个值即可。
边界框损失函数:

Faster-RCNN整体是怎么训练的?
我们知道RPN的提出让Faster R-CNN真正做到了end-to-end,使得网络之间关系更加密切,效果更好。
现在的Faster R-CNN直接采用RPN Loss+Fast R-CNN Loss来做。
但是原文中采用分别训练RPN和Fast R-CNN Loss:

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!