MTCNN(Multi-task Cascaded Convolutional Networks)介绍
MTCNN-Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
创新点
- MTCNN框架利用级联架构,通过精心设计的深度卷积网络的三个阶段,以从粗略到细致的方式预测人脸和landmark位置。
- 提出 a new online hard sample mining strategy,即一种新的困难样本挖掘策略,这种策略帮助MTCNN在实际中获得更好的效果。
Introduction
级联的人脸检测最早由Viola和Jones两人提出,他们利用Harr特征和AdaBoost训练出了级联分类器,然而,相当多的研究[1,3,4]表明,即使使用更高级的特征和分类器,这种检测器在真实世界的人脸变化更大的场景中应用,效果仍然可能会显著退化。
深度学习方法中利用CNN来检测人脸后来也源源不断的出现,其中Yang[4]的方法由于CNN过于复杂导致训练花费太大,同时它的模型没有考虑到人脸landmark位置和包围盒回归的内在关系。
人脸对齐也引起了广泛的研究兴趣。该领域的研究大致可分为两类,即基于回归的方法和模板拟合方法。也有人提出了利用深度卷积神经网络将人脸属性识别作为辅助任务来提高人脸对齐性能。
但是正如上面所说的,无论是人脸检测还是人脸对齐,都没有很好的注意到他们两者的内在关系。Zhang et al[20]利用多任务CNN来提高多视角人脸检测
的准确率,但检测召回率受到弱人脸检测器产生的初始检测窗口的限制。
这里我们总结一下上述的缺点:
- CNN过于复杂导致训练花费太大
- 没有考虑到人脸landmark位置和包围盒回归的内在关系(人脸检测和人脸对齐内在关系没有考虑)
- Multi-task CNN来提高了多视角人脸检测的准确率,但检测召回率受到弱人脸检测器产生的初始检测窗口的限制。
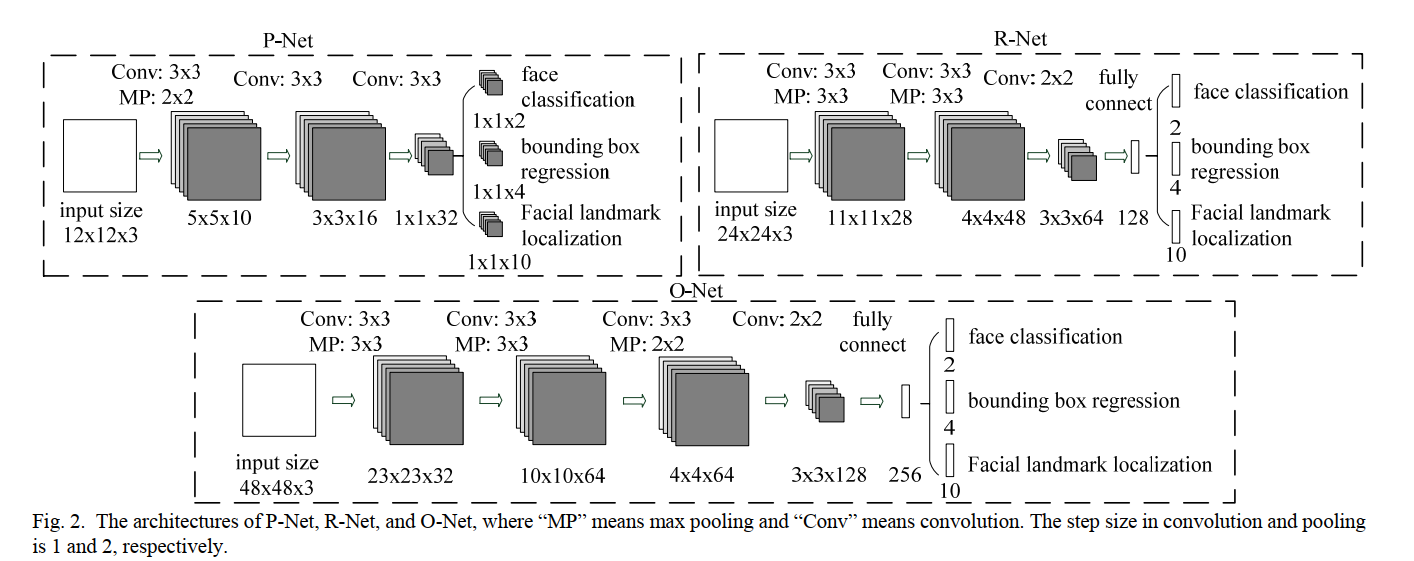
本文提出的CNN分三个阶段:
- P-Net:在第一阶段,它通过一个浅层CNN快速生成候选窗口
- R-Net:它通过一个更复杂的CNN来拒绝大量的非人脸窗口来优化窗口
- O-Net:使用更强大的CNN再次细化结果,并输出5个面部landmark位置(两个眼,一个鼻子,嘴巴的两角)。
大概流程如下:
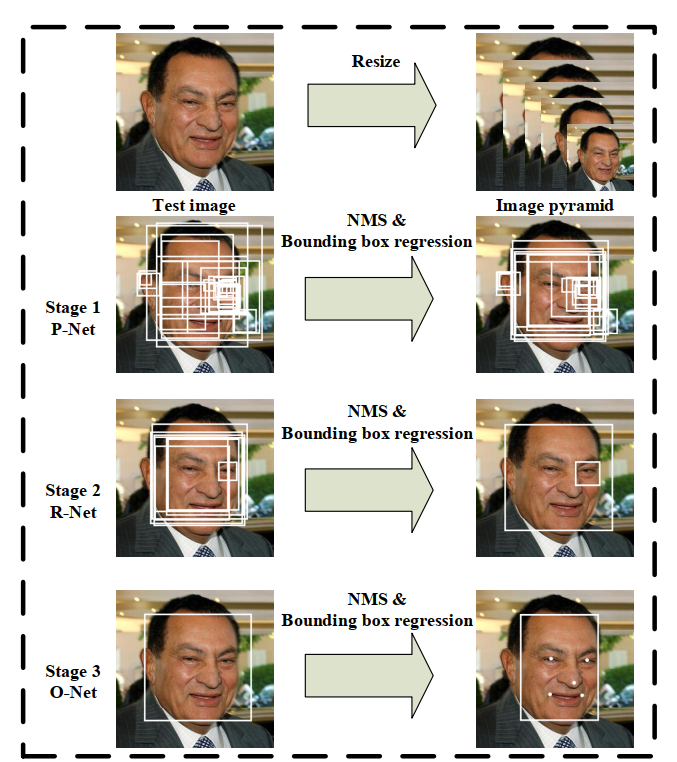
文章的贡献:
(1)提出了一种新的基于级联CNN的联合人脸检测和对齐框架,并精心设计了轻量级CNN架构以实现实时性能。
(2)提出了一种有效的硬样在线开采方法来提高性能。
(3)在具有挑战性的基准上进行了大量实验,结果表明,与目前最先进的技术相比,该方法在人脸检测和人脸对齐任务中的性能有显著提高。(当然这篇文章发表于16年,现在的效果排名可以看下图)
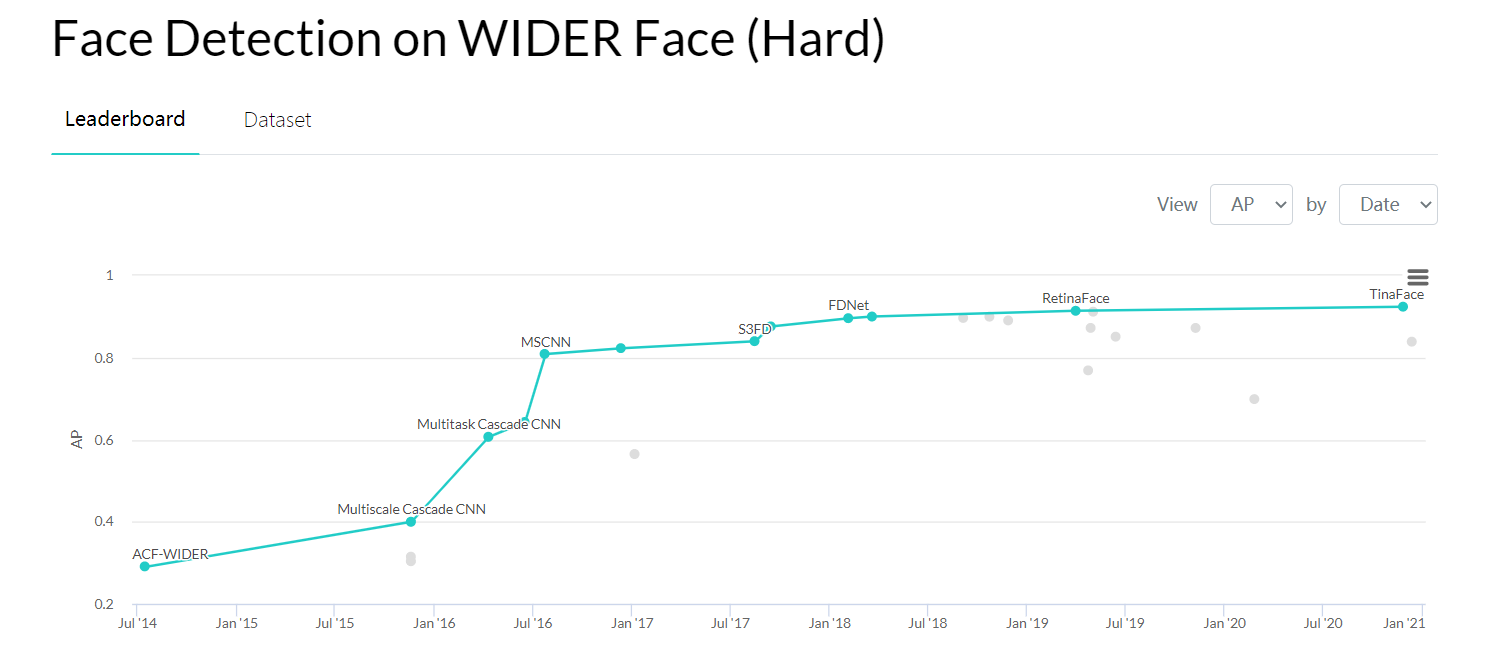
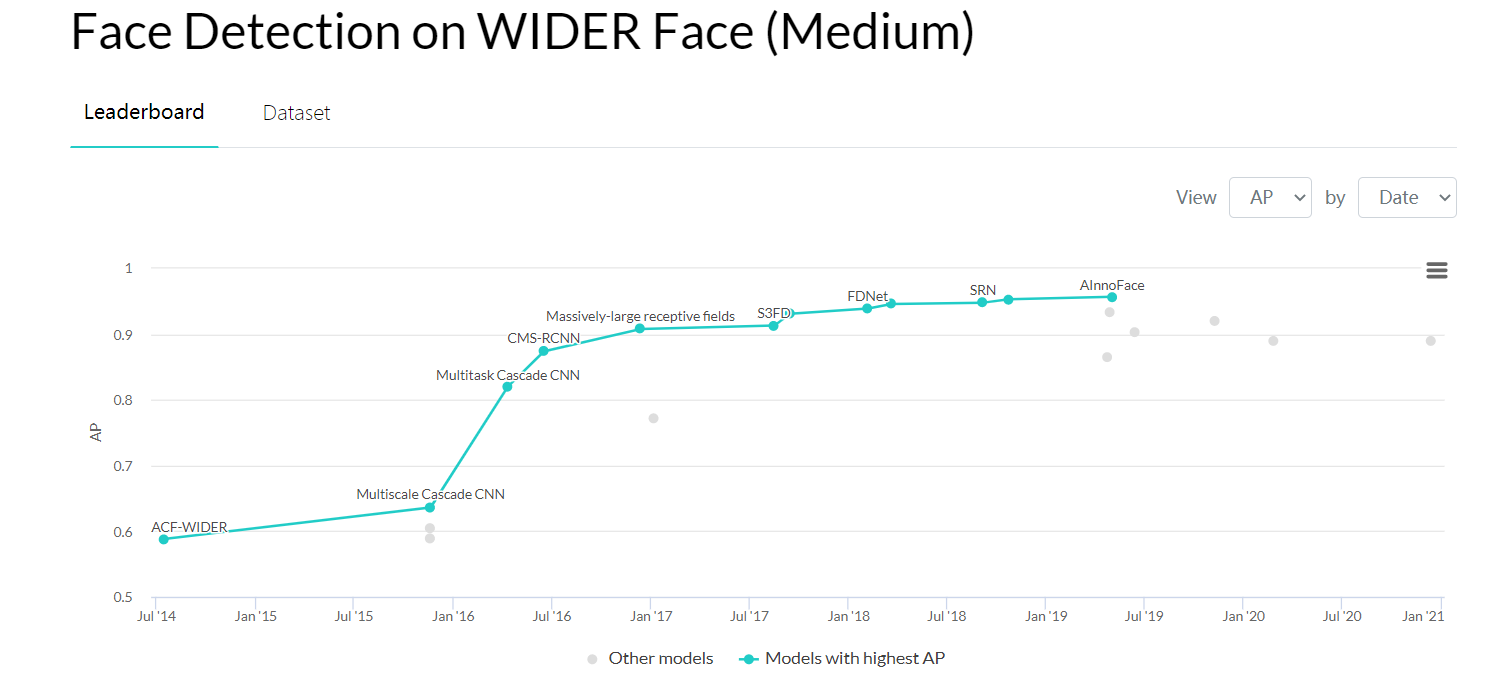
(上面两图均来自paper with code)
Approach Details
整体框架
在进入网络前,先对图片构造图像金字塔,获得不同尺度大小的图片。
首先利用一个全卷积网络(Proposal Net,P-Net)获得待选人脸窗口和包围框的回归向量,使用包围盒回归进行校准,然后通过NMS获得预选框。
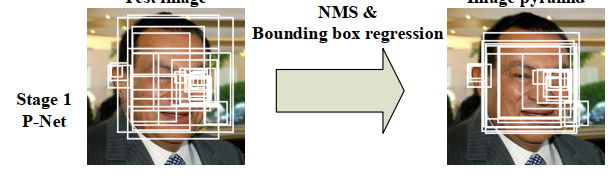
所有的候选框被送入另一个CNN,称为Refine Network (R-Net),该网络进一步拒绝大量的假候选框,使用包围盒回归进行校准,并进行NMS。

这一阶段与第二阶段相似,但在这一阶段,我们的目标是在更多的监督下识别面部区域。特别是,该网络将输出五个面部landmark的位置。

CNN架构
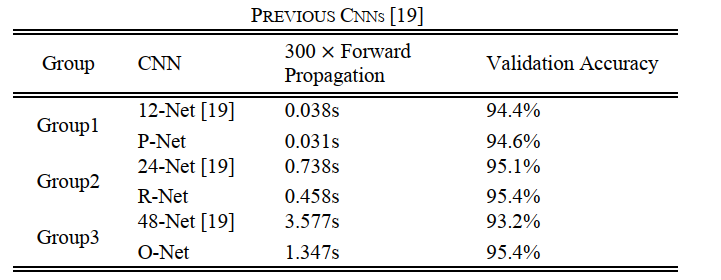
作者认为之前也出现过多个CNN框架用于人脸检测,但是都被以下几点所影响了性能和效果:
- 卷积中的滤波器缺少多样性,这可能限制了分辨人脸的能力
- 与其他多分类目标检测和分类任务相比,人脸检测是一项具有挑战性的二分类任务,因此每层需要的过滤器数量较少,但需要加深网络的深度。
更改后的效果如下:
将PReLU(Parametric Rectified Linear Unit),作为卷积和全连接层后的非线性激活函数。
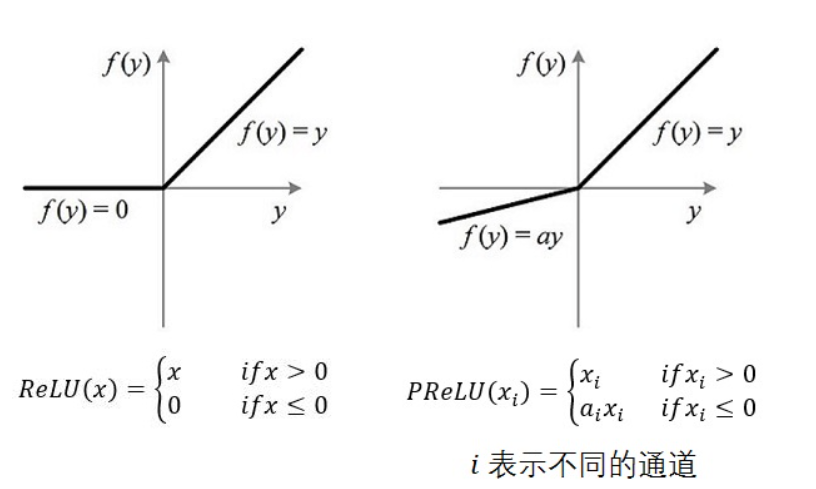
如果ai=0,那么PReLU退化为ReLU;如果ai是一个很小的固定值(如ai=0.01),则PReLU退化为Leaky ReLU(LReLU)。 有实验证明,与ReLU相比,LReLU对最终的结果几乎没什么影响。
Training
作者利用三个任务来训练我们的CNN检测器:人脸/非人脸分类、边界框回归和面部landmark定位。
- 人脸/非人脸识别
$p_i$是网络认为$x_i$为人脸的概率,$y_i^{det}$代表ground-trurh标签,表明$x_i$到底是不是人脸。
- 包围盒回归
对于每个候选窗口,我们预测它与最近的ground-truth(即边界框的左、顶、高度和宽度)之间的偏移量。学习目标被表述为一个回归问题,我们对每个样本使用欧几里德损失。
- 面部landmark定位
作者使用的训练方式是Multi-source training训练,同时不是对于所有样本都要用三种loss一起计算,几个例子,比如一个候选框里没有人脸,那么我们只用是否人脸的检测损失(即式子(1))即可。包围框损失和landmark损失根本不用算,因为此时的问题还是怎么找到人脸,而不是准确的找到人脸并找到landmark位。
总之来说,将上述三个loss合并在一起后,我们的损失函数就是:
$N$是训练样本的数量
在P-Net,R-Net中,$\alpha{det}=1,\alpha{box}=0.5,\alpha_{landmark}=0.5$,也就是此时我们更注重detection,更在意检测到人脸。
在O-Net中,$\alpha{det}=1,\alpha{box}=0.5,\alpha_{landmark}=1$,也就是此时我们更注重detection,更在意检测到人脸的landmark。
$\beta$是采样类型指示,当判定为非人脸时,$\beta{box}=0,\beta{landmark}=0,\beta{det}=1$,判定为人脸时全部取1,即$\beta{box}=1,\beta{landmark}=1,\beta{det}=1$.
L就代表不同的loss值。
online hard sample minning
不同于传统的困难样本挖掘是在原始分类器经过训练后进行的,本文是在face/non-face分类任务中进行在线硬样本挖掘,这是适应训练过程的。
具体是在一个batch里面的图片数据,只取分类损失(det loss)的前70%的训练数据backprop回去。
注意:其余两类损失不做这样的hard sample mining,原因在于回归问题再微小的nudge修正都是有用的,但是二分类就未必了。
Trainning Data
MTCNN的训练集来源于 WILDER FACE 和 CelebA,用前者产生人脸分类任务的图像,后者产生人脸关键位置标注的图像。
生成的方式是随机取样,根据取样框框与 Ground Truth 人脸框的 IoU 值将其分为4类:
Negative:IoU<0.3
Positive:IoU>0.65
Part:0.4<IoU<0.65
Landmark:标注了左右眼、鼻、两嘴角共5个位置的横纵坐标的人脸图
训练集的数据比为 3:1:1:2 (negatives/ positives/ part face/ landmark face) data.
Reference
[1] B. Yang, J. Yan, Z. Lei, and S. Z. Li, “Aggregate channel features for multi-view face detection,” in IEEE International Joint Conference on Biometrics, 2014, pp. 1-8.
[2] P. Viola and M. J. Jones, “Robust real-time face detection. International journal of computer vision,” vol. 57, no. 2, pp. 137-154, 2004
[3] M. T. Pham, Y. Gao, V. D. D. Hoang, and T. J. Cham, “Fast polygonal integration and its application in extending haar-like features to improve object detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2010, pp. 942-949.
[4]S. Yang, P. Luo, C. C. Loy, and X. Tang, “From facial parts responses to
face detection: A deep learning approach,” in IEEE International Conference on Computer Vision, 2015, pp. 3676-3684.
[5]人脸检测—MTCNN从头到尾的详解 - 丘学文的文章 - 知乎 https://zhuanlan.zhihu.com/p/58825924
[6]MTCNN人脸检测:三个臭皮匠,顶个诸葛亮 || 5分钟看懂CV顶刊论文 - Uno Whoiam的文章 - 知乎 https://zhuanlan.zhihu.com/p/59262113
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!