C++面向对象高级编程-下
C++面向对象高级编程(下)
Conversion function转换函数

1 | |
对于double d = 4 + f;这一条语句编译器的动作是:
1.对于上面的操作4+f有没有一个operator+可以使得 double + fraction的函数(不存在,那么下一种方法)
2.是否存在可以让4转换为double的函数(默认存在)和让fraction转换为double的函数(存在),因此没有问题通过。
以上的动作不存在谁比较好/谁先谁后,超过一个可行都会被认为是ambiguous的。
隐式转换构造函数non-explicit-one-argument ctor

1 | |
Fraction d = f + 4; 这个函数的意义是 f调用operator+ 参数为4 ,而接受端会发现4被隐式转换成 Fraction。这个隐式转换是non-explicit ctor做得,他将4转换为了Fraction类型。
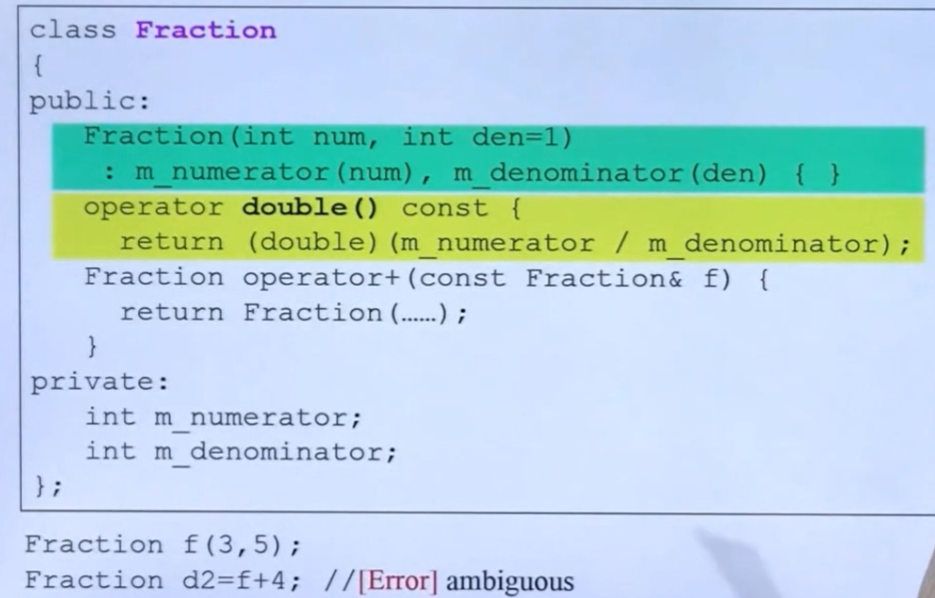
上述代码会造成的歧义:
1.f + 4 先调用operator+ ,由于加法的参数需要fraction,因此将4隐式转换为Fraction类型,执行完成加法操作。
2.f首先变成double类型,随后再和4相加,最后整体作为一个数字通过隐式转换转换为Fraction类型
以上两种都可以发生且合理。
如果你不希望那种隐式转换(non-explicit)出现,那么可以加上explict关键字,防止通过构造函数进行隐式转换:


虽然此时还是会出现错误的,因为上面我们所提到两种歧义的方法都会用到隐式转换:一种是4隐式转换为Fraction类型,另一种是答案通过通过隐式转换转换为Fraction类型。但由于此时我们加上了explicit关键字,这里不允许通过他的构造函数发生这种的隐式转换。
标准库中的一个利用转换函数的例子
这是一个模板偏特化的例子,也是标准库中的一段代码:

这里用reference来代替了返回的类型,那么就一定要利用转换函数将返回结果的类型(bool)转换为reference的类型,而这类的reference通过就是__bit_reference类型,那么也就是说__bit_reference这个类里一定有一个转换为bool类型的转换函数:

发现确实如此。
pointer-like classes,关于智能指针
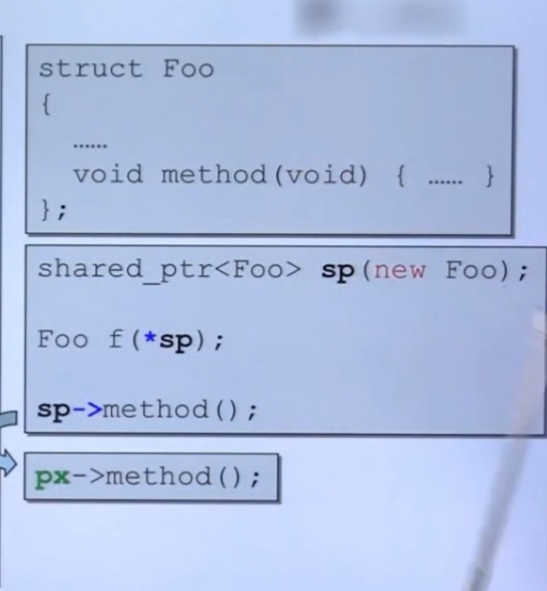
这是一个类似指针,但比普通指针更智能的写法,是c++写的一个类。

1 | |
首先new一个Foo类型的指针当成初值赋值给shared_ptr的对象sp,这个赋初值的过程毫无疑问调用的是shared_ptr的构造函数。
1 | |
这一步由于重载运算符operator*(),把sp指针中的px指针所指的值取出来。
以上两部都很符合直觉,但是当我们调用sp这个智能指针所指对象的method方法时,我们理希望 调用方法肯定和普通指针一样:
1 | |
我们所希望的操作是:sp->method() 转换为 px->method() 然后再得到结果,但是->被重载过了,因此sp-> 会转换为 px ,此时因为重载运算符已经消耗了一个箭头,那么问题就来了,好像少了一个箭头?
其实不然,这属于c++的特性,语言设计者唯独对这种操作符加了一些不同于其他操作符的东西,即:重载后依然会保留->的操作符。
pointer-like classes,关于迭代器
迭代器多了++,—这一类操作,因为迭代器可以用来遍历容器。
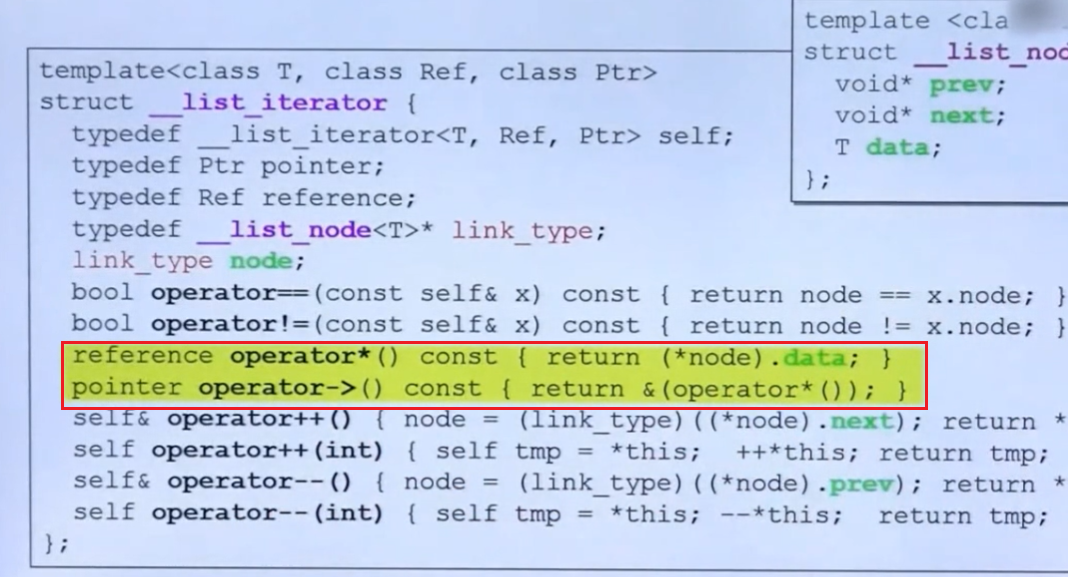
我们单独讨论一下 dereference和->两个重载运算符函数:
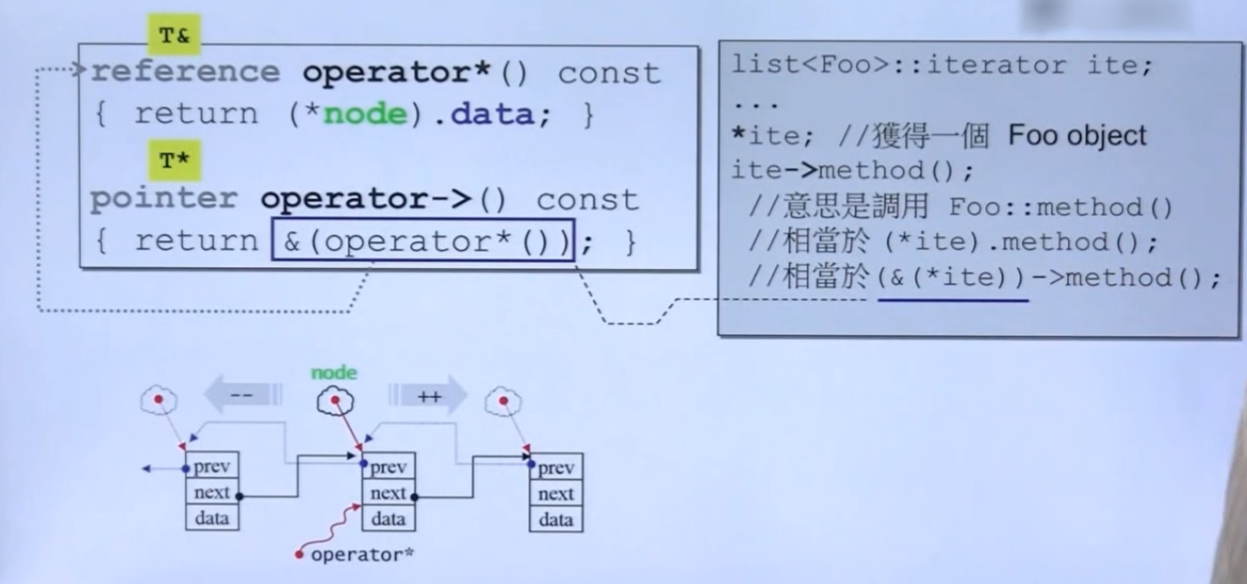
我们希望迭代器like 指针,那么也就是希望支持这两种操作:
1.*取值操作符
1 | |
这个完全可以通过 operator*完成,即return (*node).data
2.->操作符
1 | |
如何实现ite类型->操作符重载?
这个操作可以先通过 operator*获得一个对象(注意 这里的operator *可不是普通的,而是我们已经重写后的了,它可以对迭代器这种pointer-like-class直接获取对象),然后再通过&获得这个对象的指针,然后再通过这个指针完成调用Foo的method()函数。
还记的上面所说的关于->一个语言特性吗? 重载运算符已经消耗了一个箭头,但箭头还会存在,这属于c++的特性,语言设计者唯独对这种操作符加了一些不同于其他操作符的东西,即:重载后依然会保留->的操作符。
因此重载后,ite->method() 变成了&(*ite) -> method() ,

function-like classed,仿函数/通过重载operator ()实现仿函数

这里面的重载()就是仿函数的主要特点,希望类像函数一样可以使用。
因此我们可以通过重载operator ()实现仿函数。
一个简单的例子:

再谈namespace
对标准库里的东西全部打开,以后不用写std::cin等 直接写cin即可

也可以部分展开namespace:

namespace简单来说就是防止命名冲突。
function template,函数模板
编译器会对function template进行模板推导:也就是说要进行两次编译,第一次你的函数如果调用了这个模板才能推导出模板的类型stone,第二次找<操作符的重载函数:如下
1 | |
如果你把<操作符重载删除是无法通过编译,因为调用minn时首先推导出了stone类型,第二次编译发现没有stone的比较符号,因此会报错.
但是如果你并没有调用minn函数,那么就还可以通过编译。因为根本没有模板进行推导,因此编译器也不会发现你没有写重载<运算符函数。
member template,成员模板
成员模板即 class里的成员利用模板编写。

首先外面的T1,T2是允许变化的,在确定后,里面的U1,U2也是允许变换的。
有了这样的技术,我们就可以把 <鲫鱼,麻雀>这一对pair用来初始化 <鱼类,鸟类>这一对pair。

这个在c++有一些实际的应用:
比如智能指针中的shared_ptr:

父类指针可以指向子类的对象,这是我们c++所支持的up-cast,因此我们希望智能指针也可以做到的up-cast,具体怎么做呢?

首先shared_ptr这个智能指针利用模板特性可以完成up-cast操作, 比如:你想完成shared_ptr<Base1>sptr(new Derived1)这个操作:
1.此时__shared_ptr<>就会被绑定为Base1类型,即_Tp推导出类型为Base1,
2.new Derived形成的指针推导出_Tp1的类型为Derived,即_p会被绑定为 Derived*类型
3.因为Derived是Base的子类,因此可以进行初始化父类指针指向子类,这一步的操作是通过explicit shared_ptr(Derived1* __p):__shared_ptr<Base1>(__p){}这个含有初始化列表的构造函数实现的,其中的初始化列表就相当于给shared_ptr中的__shared_ptr<Base1>赋值为__p(Derived类型),这一步就是实现了up-cast。
我们发现通过模板特性,我们可以将这样的up-cast操作完美完成。
specialization,模板特化
模板特化就是指对模板进行特征化,模板是一个泛化的概念,也就是可以接受多种类型变量,但是我们可以特征化 模板的接收各类型变量的动作,也就是说 编译器认为,对于特定的类型,如果你能对某一功能更好的实现,那么你自己写:
如下图,我们在用模板特性写完struct hash后,开始特化三个类型的struct hash,分别是char,int,long。
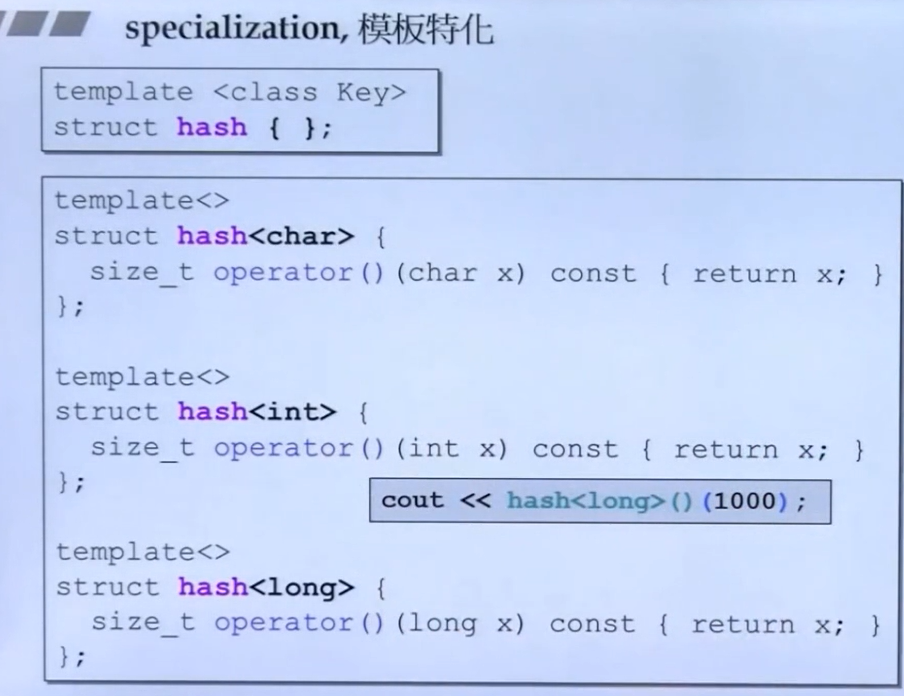
一个完整的例子:https://www.cnblogs.com/xiangtingshen/p/11157198.html
partial specialization,模板偏特化/全特化
通过特化可以对某一种特定类型的进行自定义实现。编译器认为,对于特定的类型,如果你能对某一功能更好的实现或想法,那么你自己实现。
特化可以分为:
全特化就是全部特化,即针对所有的模板参数进行特化。《c++ primer》
偏特化就是部分特化,即针对部分模板参数进行特化。《c++ primer》
可以看出特化无论是全/偏都是对模板参数的解读。
函数模板,却只有全特化,不能偏特化:即函数模板必须提前指定好所有的参数类型
1 | |
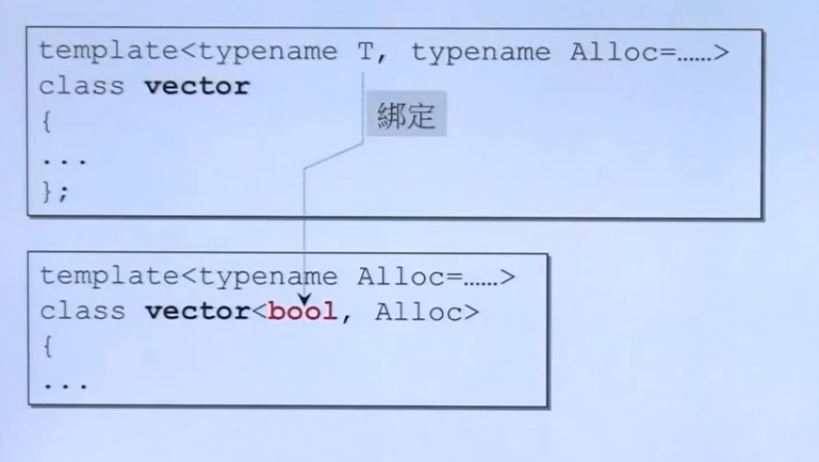
偏特化的偏有两种:
一个是参数个数上的偏,另一个是范围上的偏
1.一个是参数个数上的偏
如下图,绑定第一个参数为bool类型进行偏特化。
2.另一个是范围上的偏
我们有时候会希望对于模板的T在作为指针类型时执行特定的规则,否则按照模板泛化的规则来执行。

范围上偏的简单例子:
1 | |
template template parameter,模板的模板参数
模板的模板参数就是:模板中还存在模板作为的参数。注意:函数模板不支持模板的模板参数,类模板才支持这种操作
这个的应用场景是,比如我们想这么用:
1 | |
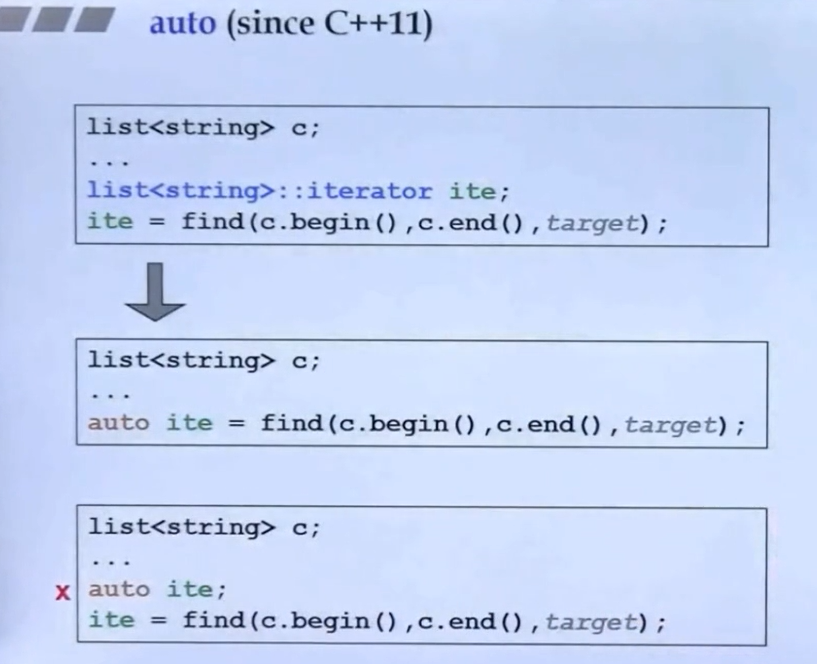
此时希望list自动辨别出来我们要用的是string,并把list自己的容纳元素类型绑定成string。一个简单的方法就是:
1 | |

这样可以达到我们想要的效果吗?
奇怪的是并不可以:这是因为XCLs中的Container<T>c这部分的T填入的是类型T(string),然而我们平时可以这么用list<string>是因为string填入后,其实<>后面还会有一些默认参数,但是如果你用T表示,c++就会认为你没有填入后面的默认参数(语言的规定)。简单来说如果你用了T做容器的参数,那么容器的后面的默认参数会失效,你需要自己补上这些参数。
因此我们可以这么用(c++2.0新特性(c++11/14)),使得第二种是对的:即利用using定义模板别名

1 | |
这个模板推导过程是:T推出string,然后从CONT<T>c推出U是string,然后从U再推到T2是string
下面这并不叫做一个模板模板参数,因为XCLs<string,set<string>>mylist1;中的set<string>就已经绑定好容器的元素类型了,使得class CONT变成set<string>根本没有模板进行推导。
1 | |
C++11: variadic templates数量不定的模板参数
下面是一个数量不定的模板参数的例子,print()函数做得是一个将一堆参数输出的动作。
每次取出第一个参数输出,剩下的参数包递归下去每次输出参数的第一个。但请不要忘记写void print(){ },因为当参数空的时候,你需要一个无参的print来结束print的递归。
如果你想知道 后面那一部分参数包有几个,你可以使用sizeof...(args)。

1 | |
C++11: auto关键字
这是一个语法糖。
算法竞赛里天天用,就不细说了。
C++11: ranged-base for

再谈reference引用

引用必须设初值,即必须定义时标明你引用的是谁。并且以后不可以修改这种绑定关系(但指针可以)。
对引用的修改就是对和他初始绑定的变量的修改
指针的大小是固定的8字节(64位系统,32位系统为4字节),引用的大小取决于和他绑定的变量,变量多大引用多大,即
sizeof(reference) = sizeof(绑定的变量)绑定的变量。但这是假象,引用就是指针实现的(而且还是一个指针常量),所以其实实际只占用了指针的大小。同时,&reference = &绑定的变量也是假象,其实他们并不相同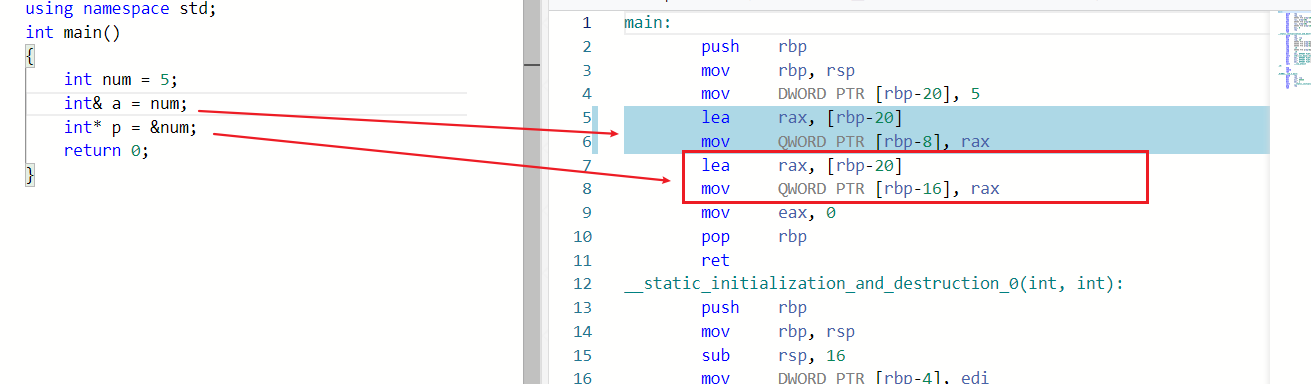
拓扑结构的递归引用相当于最开始的绑定的变量: 即
int& r = x;int& r2=r;r2修改其实就是对x修改

- reference具有天生自然的优势在参数中使用,因为保证了调用和被调用端口的一致(上图)。
- 函数重载中,参数仅有是否引用的区别会被认为是同一函数,因此不能同时出现

再谈重载(overloading)函数
上面一节最后谈到了,const是不是函数签名的一部分,这次我们来测试下:
函数重载中,参数仅有是否加const的区别会被认为是不同同一函数,因此可以同时出现:
1 | |
函数重载中,函数仅有是否加const的区别会被认为是不同函数,因此可以同时出现:
1 | |
因此我们可以 认为const是判别是否为相同函数的函数签名 的一部分
虚指针(vptr)和虚表(vtbl)
带x个虚函数的class的大小也只会多 8 字节(64位下),这是因为含有虚函数的对象/类有一个虚表指针,他的大小是8字节,这个虚表指针会指向虚表。
那么编译器是如何处理虚函数的呢?
1.如果类中有虚函数,就将虚函数的地址记录在类的虚函数表中。
2.派生类在继承基类的时候,如果有重写基类的虚函数,就将虚函数表中相应的函数指针设置为派生类的函数地址,否则指向基类的函数地址。
3.为每个类的实例添加一个虚表指针(vptr),虚表指针指向类的虚函数表。
4.实例在调用虚函数的时候,通过这个虚函数表指针找到类中的虚函数表,再找到相应的函数进行调用。
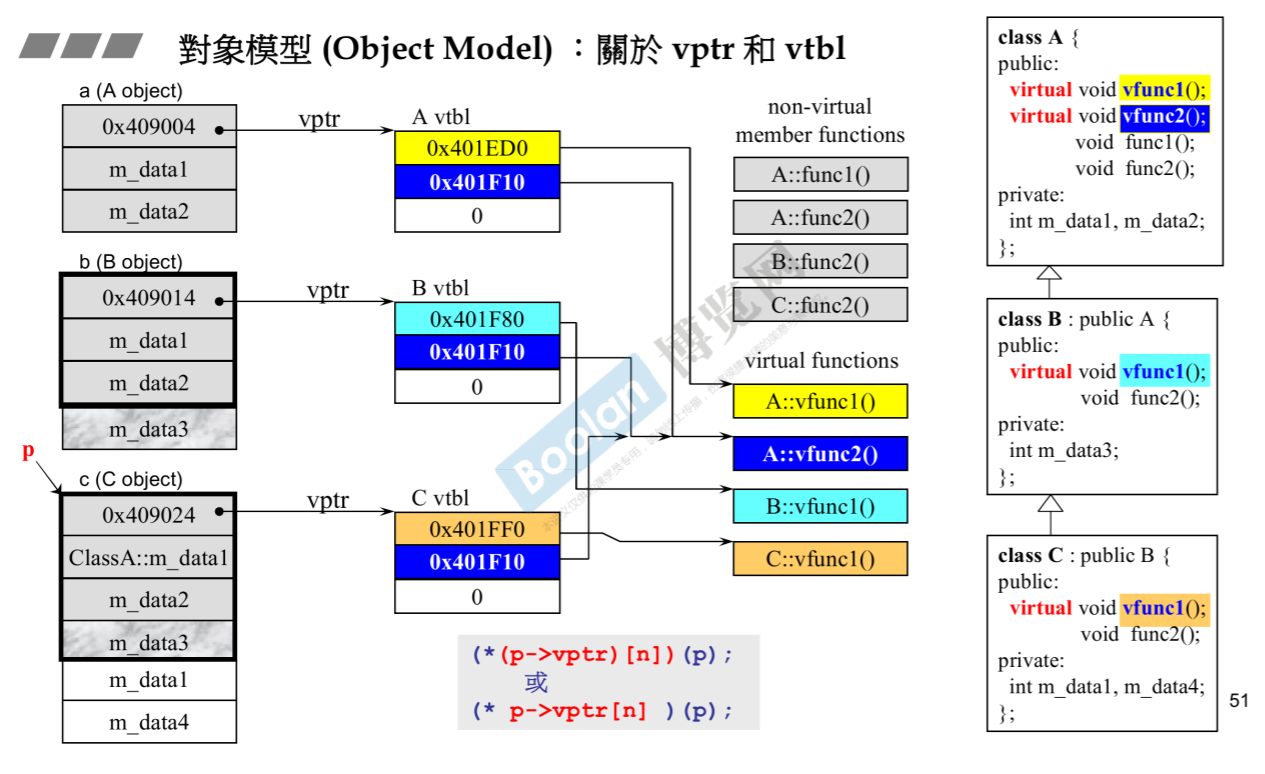
1.首先class A有两个虚函数,因此虚表应该有两个指针指向两个虚函数。如下图标出的红色框。
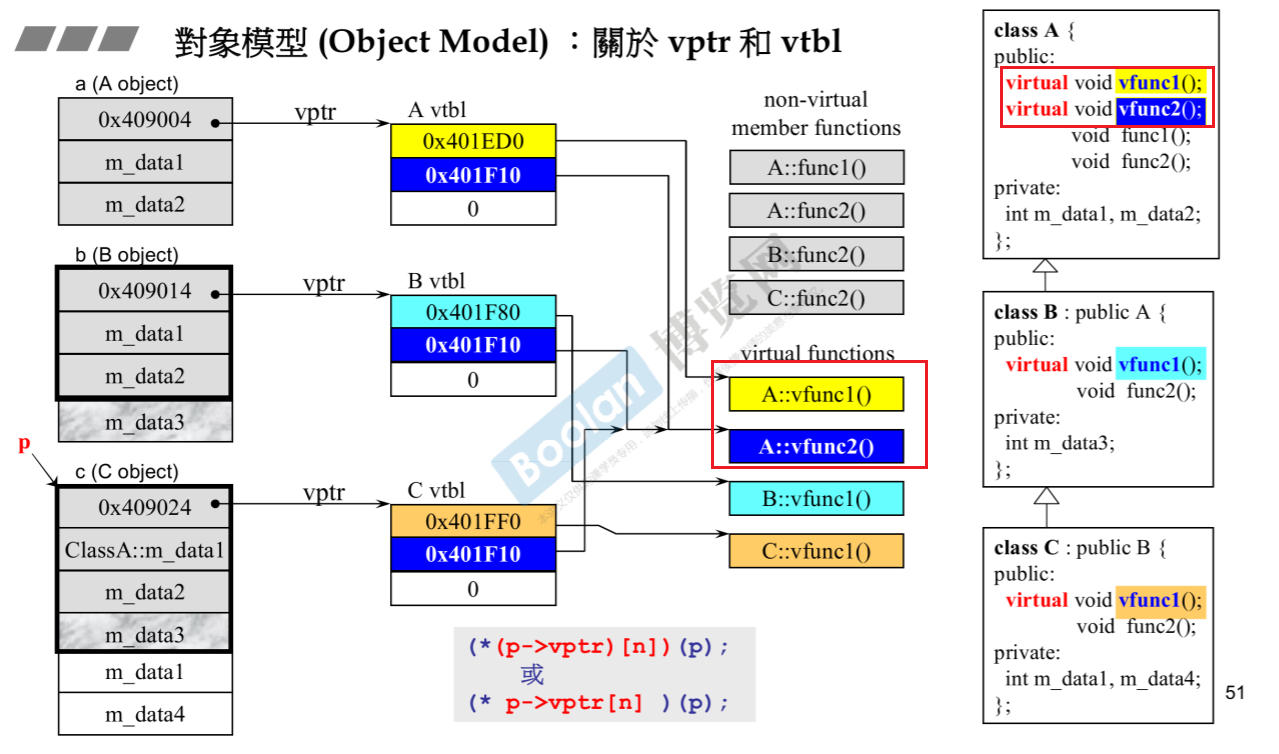
2.class B继承了Class A,但是class B的虚函数也是vfun1(),由于和从A继承的虚函数vfun1()同名,这就会推翻class B从class A所继承来的vfun1(), 因此可以看作是一个全新的函数B::vfun1()。除此之外,还会从class A继承一个vfun2()虚函数。
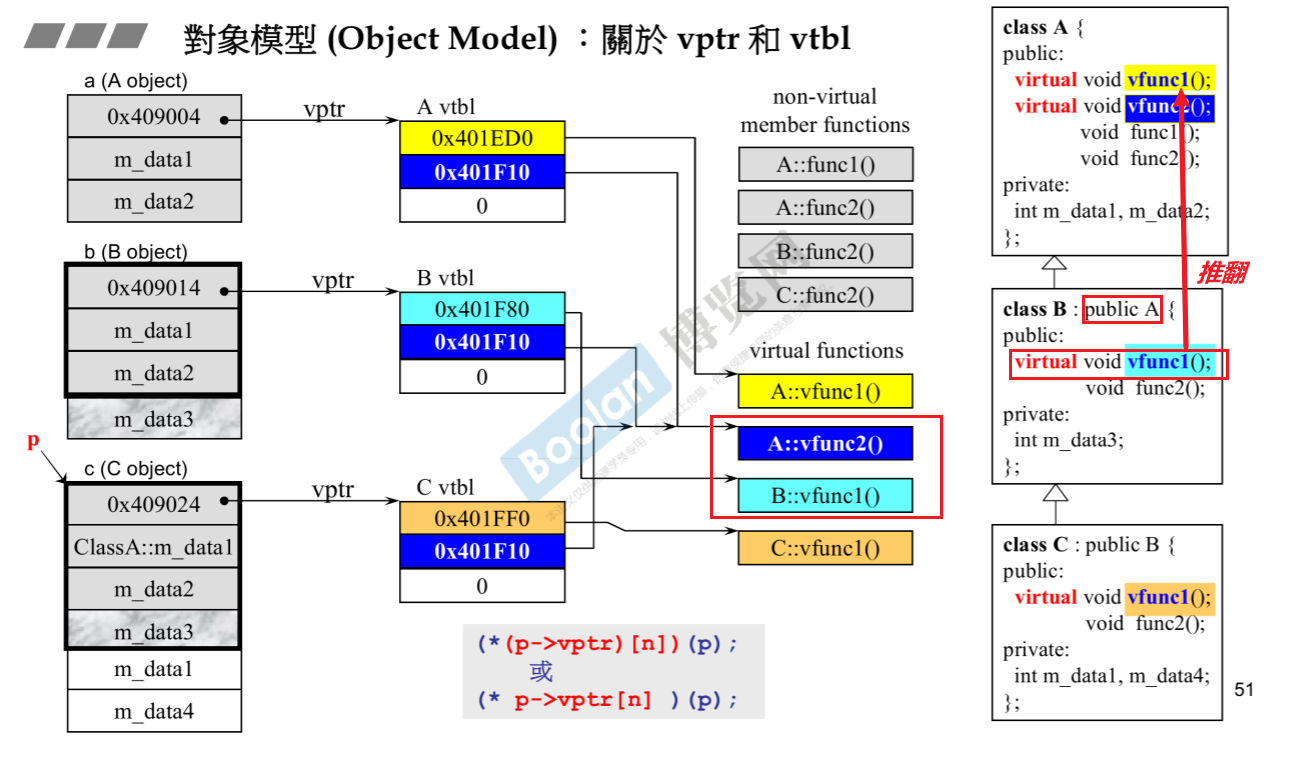
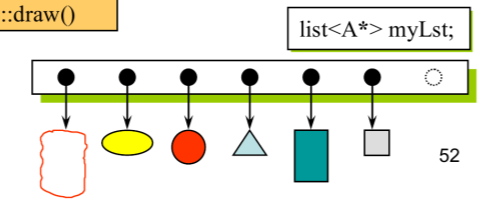
虚函数实现了多态:
A可以看作是shape,里面有纯虚函数draw(),继承他的各个形状自己改写draw()函数,我们的容器可以存不同的形状(通过父类指针作为容器元素),调用draw就会触发不同的效果,实现了多态。
动态绑定和静态绑定
转自: https://www.cnblogs.com/leoncumt/p/10491842.html
1 | |
- 静态绑定:
绑定的是对象的静态类型,某特性(比如函数)依赖于对象的静态类型,发生在编译期。
- 动态绑定:
绑定的是对象的动态类型,某特性(比如函数)依赖于对象的动态类型,发生在运行期。
1 | |
pD->DoSomething()和pB->DoSomething()调用的是同一个函数吗?
答案:不是的,虽然pD和pB指向同一对象,但函数DoSomething()是一个non-virtual函数,它是静态绑定的,也就是编译器会在编译器根据对象的静态类型来选择函数,pD的静态类型是D*,那么编译器在处理pD->DoSomething()的时候会将它指向D::DoSomething()。同理,pB的静态类型是B*,那么pB->DoSomething()调用的就是B::DosSomething()。
pD->vfun()和pB->vfun()调用的是同一函数吗?
答案:是的,这是因为vfun是一个虚函数,他是动态绑定的,即绑定的是对象的动态类型,pB和pD虽然静态类型不同,但他们同时指向一个对象,他们的动态对象是相同的,都是D*,所以,他们调用的是同一个函数:D::vfun()。
指针和引用的动态类型和静态类型可能会不一致,但是对象的动态类型和静态类型是一致的。
例如:D.DoSomething()和D.vfun()永远调用的都是D::DoSomething()和D::vfun()。
综上总结:
只有虚函数才绑定的是对象的动态类型(动态绑定),其他的全部是静态绑定。
再谈this和动态绑定
从汇编来看静态绑定:
下面的a是一个对象,他是静态绑定。因此汇编程序直接用指令call 了一个地址即A::vfun1()的地址。
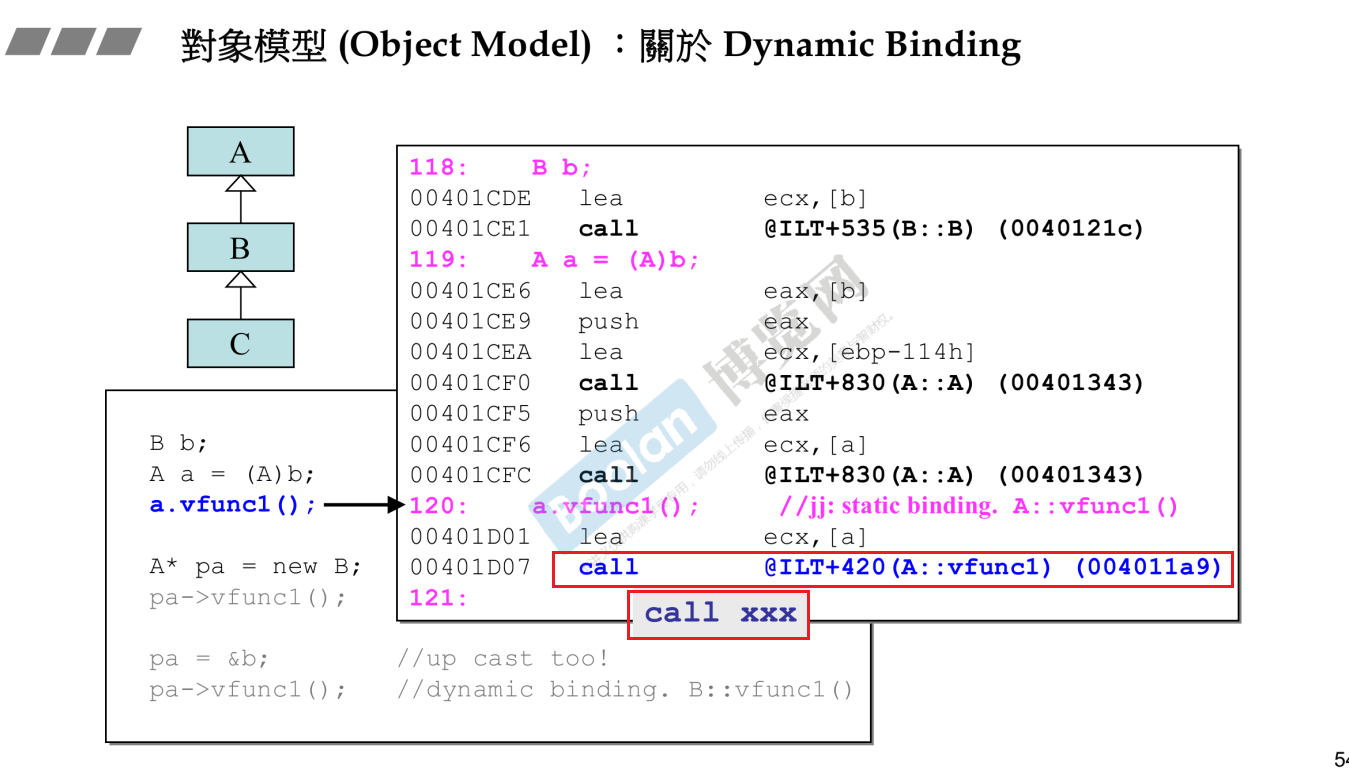

pa的动态类型是B*在运行pa->vfun1时动态绑定为B::vfun1(),因此才能使得pa->vfun1()运行出来是B::vfun1()函数。
在汇编中来看他是怎么实现动态绑定的呢?
1.他是通过p指针指向虚表完成的,p指针也就是this指针。
2.而this指针是干什么用的?在不同的对象调用的时候,编译器会自动将该对象的地址赋予“this”。
3.因此正是this中有对象的动态类型,因此this得以通过虚函数表和虚指针正确的调用出B::vfun1()函数,就像下图一样找到最后需要的函数。
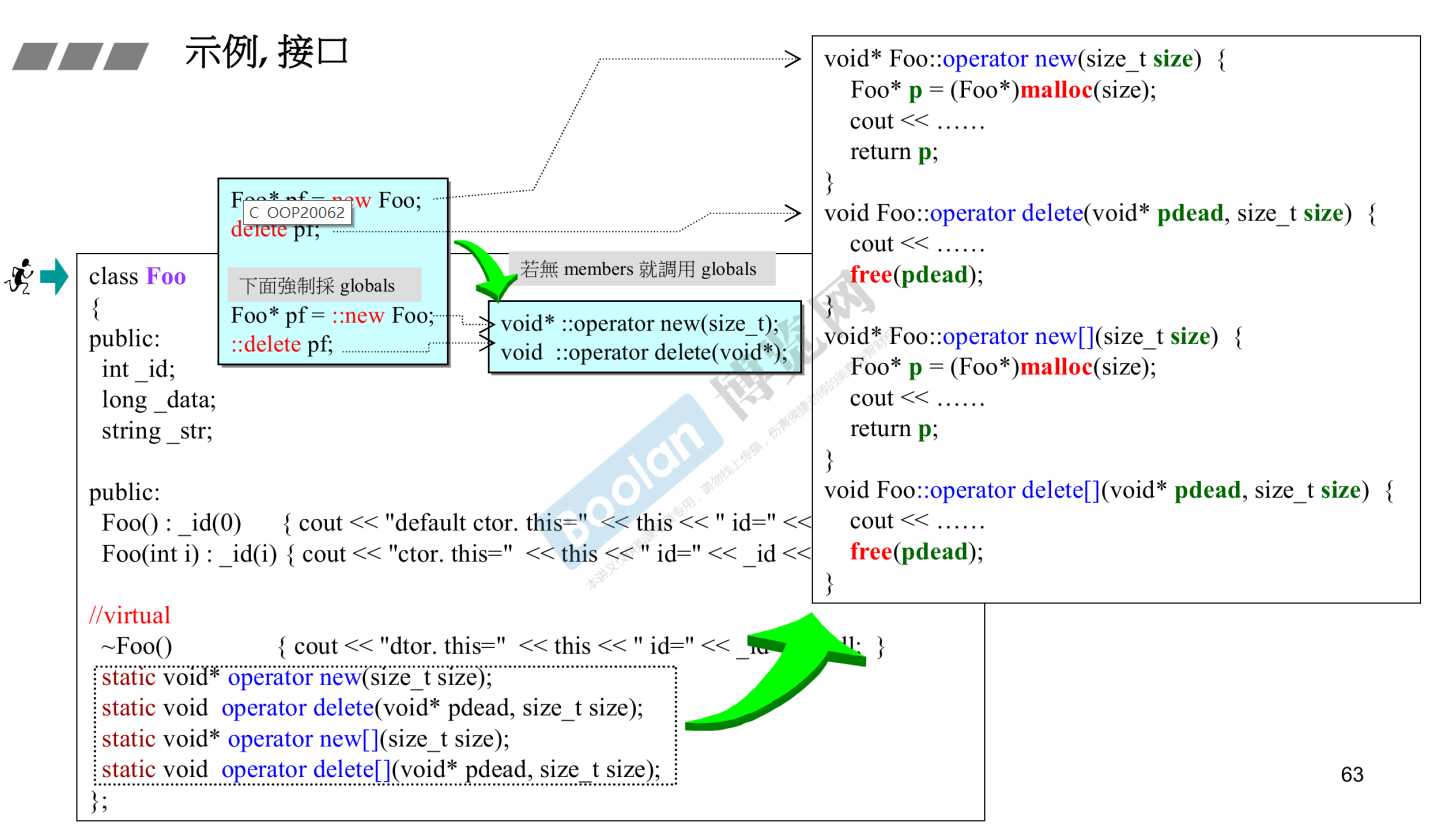
重载operator new/delete/new[]/delete[]
首先我们有必要区分一下 operator new和new operator(delete也是同理)
new operator是c++内建的,无法改变其行为;(delete也是同理)
而operator new 是可以根据自己的内存分配策略去重载的。(delete也是同理)
因此我们重载只可以对operator new进行重载,下面会介绍全局函数重载和成员函数重载
对于全局函数重载,直接如下写即可:
但是这种影响是很宽泛的,我们几乎不会这么用

当然我们更常用的是如何重载一个成员函数中的new/delete:
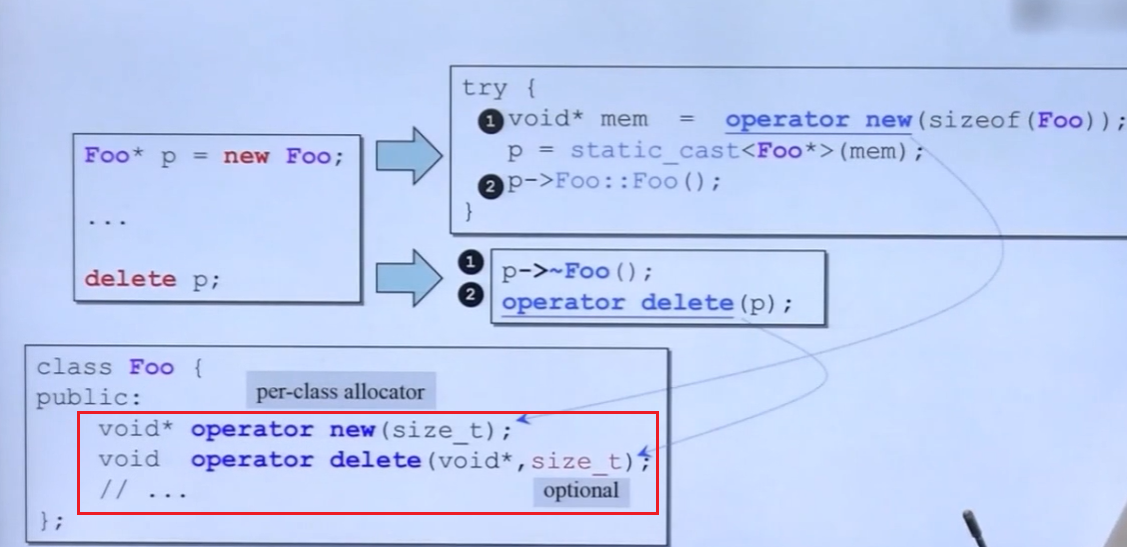
new operator第一步分配空间会使用operator new来做,此时如果你重载了对象的operator new,那么就会调用重载后的。
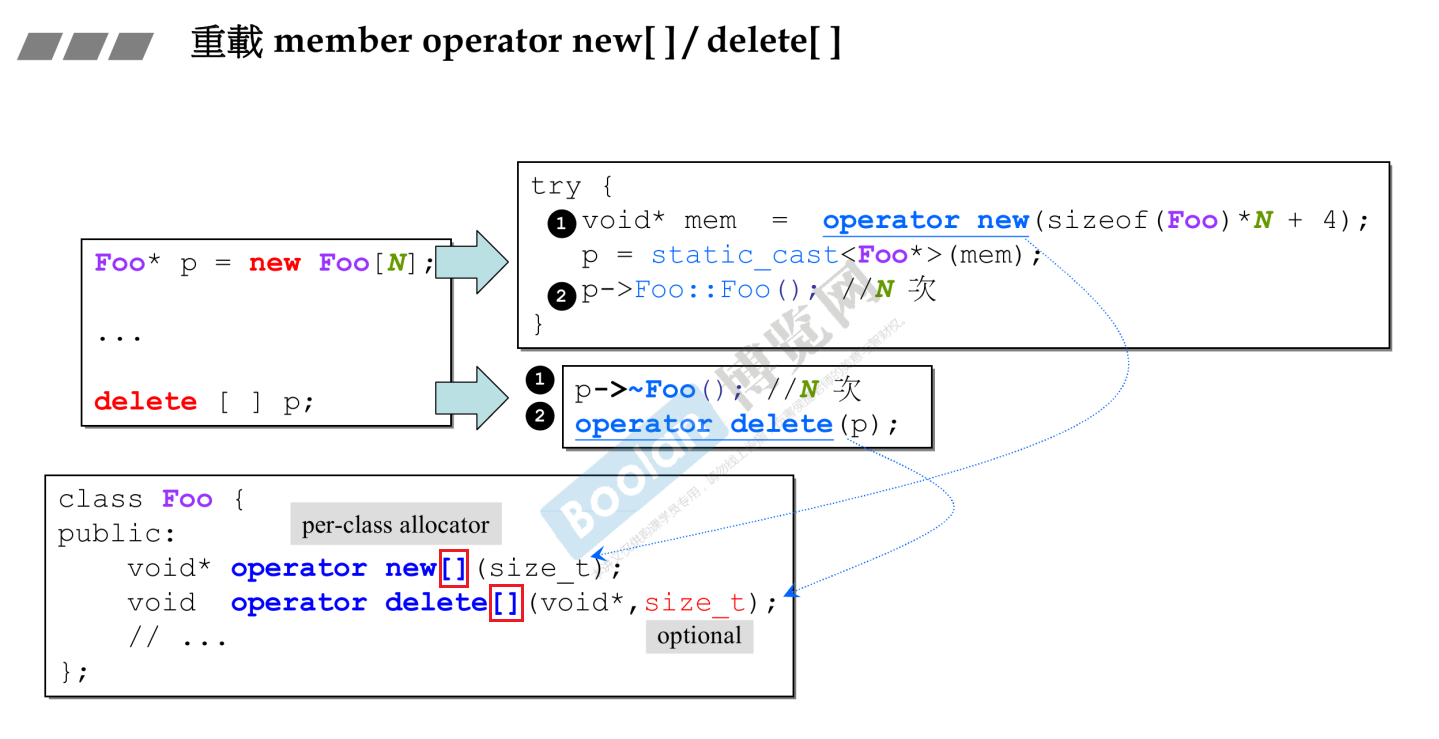
operator new []/operator delete[]的内存大小为什么多4?
对于operator new []/operator delete[]和上面没什么区别,多了一个[]而已。
这里我们发现下图中new operator操作第一步调用operator new的时候分配的是对象的内存$(FOO)*(N个)$后还多了一个4字节,这个表示连续有少个对象,起一个计数器counter作用。
强制调用全局默认的new/delete/new []/delete[]:
即使你定义了成员函数里写了operator new/delete的重载函数,你依然可以强制调用global的new/delete,操作方法为: 在new/delete前加::
1 | |
最后一个具体使用示例:
重载new()/delete()

new() 称之为placement new(),我们需要重载operator new实现,那么和上面的普通的重载operator new有什么区别呢?他的区别就是在operator new()重载函数中的参数多了一些东西。

- placement new()的第一参数必须是
size_t,其余的参数就是所谓的placement arguments。 
一个标准库中placement new()的例子:
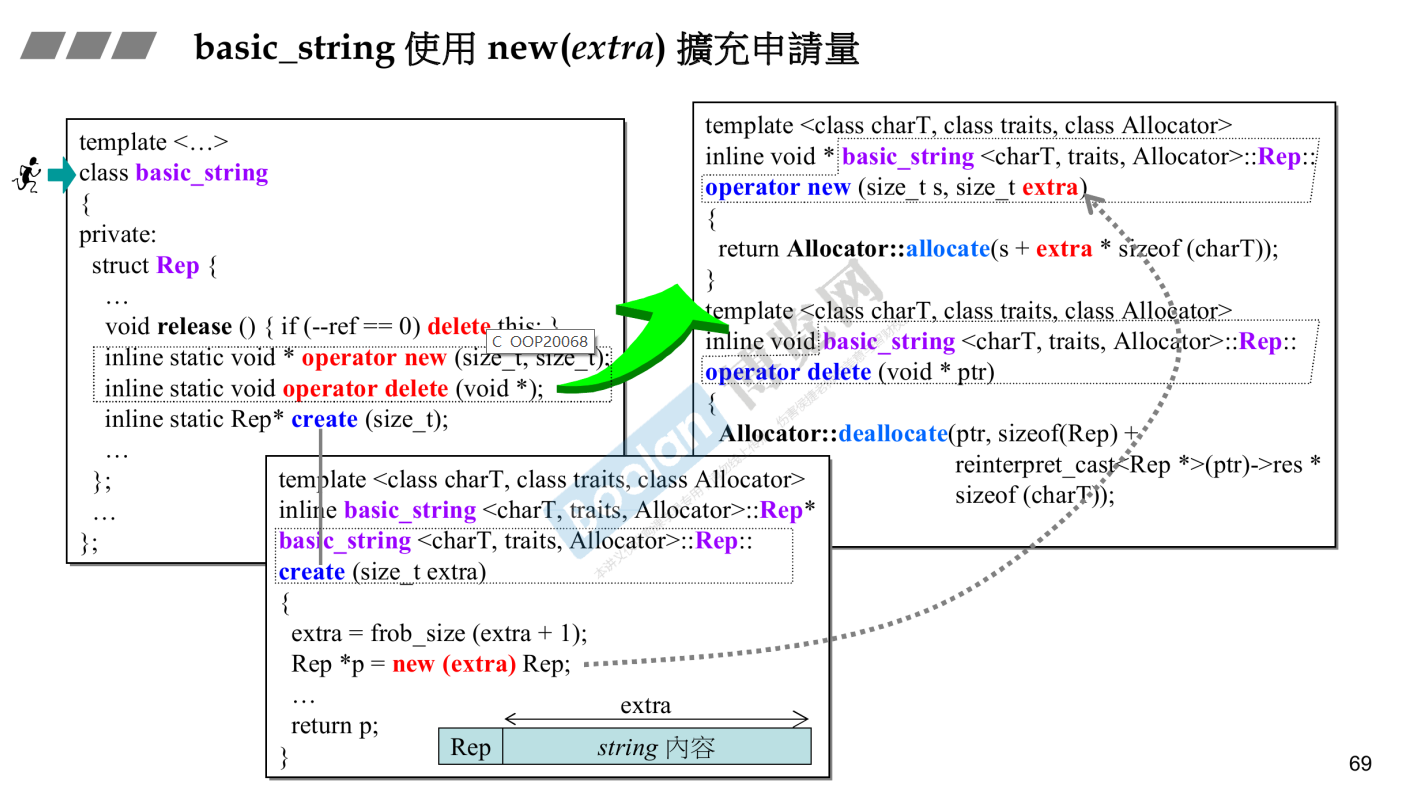
sgi在basic_string内部定义了一个Rep的结构体,负责COPY-ON-WRITE的实现。要实现COPY-ON-WRITE,就必须对分配的内存块进行计数,Rep就用来进行计数,并把它放在每个内存块的起始位置。同时Rep里还存有一些状态信息。
所以内存布局是这样的,Rep|char_type, char_type, char_type……
写入时复制(英语:Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时要求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!