C++11新特性
ariadic Templates数量不定的模板参数
下面是一个数量不定的模板参数的例子,print()函数做得是一个将一堆参数输出的动作。
每次取出第一个参数输出,剩下的参数包递归下去每次输出参数的第一个。但请不要忘记写void print(){ },因为当参数空的时候,你需要一个无参的print来结束print的递归。
如果你想知道 后面那一部分参数包有几个,你可以使用sizeof...(args)。
1 | |
下面考虑这样一个函数可以和上面的void print(const T& firstArg,const Types&... args)函数共存吗?一般来说答案是否定的,但是在Variadic Templates中是允许的, 即C++不认为这是有歧义的。
1 | |
那么这两者的谁更泛化,谁更特化?当然是第一种的void print(const T& firstArg,const Types&... args)更特化。
标准库中有一个很好的例子如下图,hash_val有三个版本,分别是:
1 | |
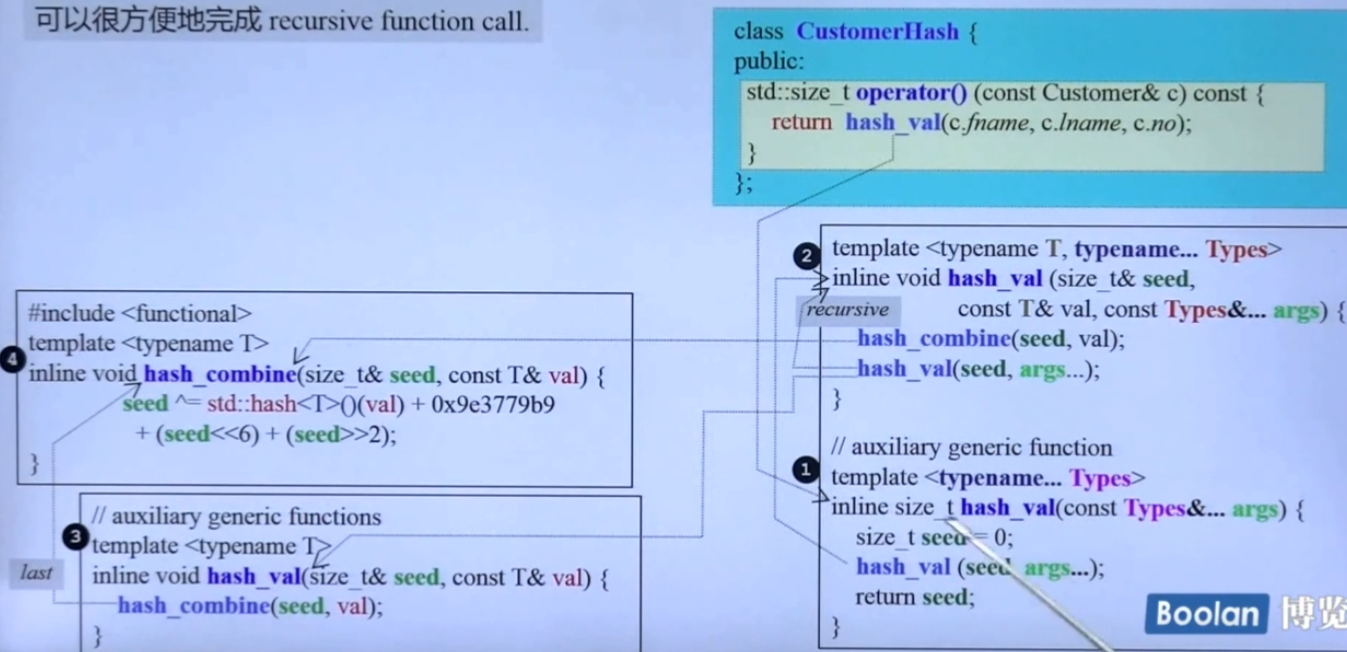
如上图②会一直调用自己本身,直到args...只剩下一个时则会调用③。
而③由于第一参数不是size_t&没有其他人特化,所以一直没有被调用。当第一参数不是size_t&时的函数调用时他这个更泛化的版本才会被调用到。
Tuple的实现也利用了Variadic Template来做递归继承。

Spaces in Template Expressions
1 | |
原来编译器不够智能会导致>>被认为是流操作符,现在已经可以这么使用了
nullptr and std::nullptr_t
在nullptr出现之前,我们一直使用NULL代表指针的空,其实NULL定义就是0,这会带来一些问题:
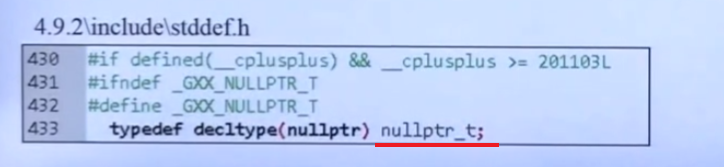
f(NULL)会带来歧义,为了解决这个歧义,C++11提出了nullptr关键字,他的类型是:std::nullptr_t
这个类型是如何定义的呢?
auto
基本用法
使用它来做自动类型推导,可以和其他操作符(&,*,const),一般来说auto 是根据变量的初始值来推导出变量类型的,比如一些容器的迭代器完整写下来就很长,使用auto就很方便
1 | |
auto只建议在类型过长时使用,例如lambda表达式的类型,迭代器等…,而不该滥用auto
auto trick
=右边是一个引用类型时auto会自动把引用抛弃,推导出原始类型:这是符合直觉的,我们希望引用与否掌握在程序员手上,因此这种帮助了我们根据意志自由决定。
1 | |
- 当类型不为引用时,
auto的推导结果将不保留表达式的const属性; - 当类型为引用时,
auto的推导结果将保留表达式的const属性。
对于上边两条做出解释:
1.当类型不为引用时,auto 的推导结果将不保留表达式的 const属性;
1 | |
2.当类型为引用时,auto 的推导结果将保留表达式的 const 属性。
1 | |
这么做的原因是为了安全,如果你的auto推出的是int,那么也就是说可以通过这个引用去修改一个const的变量,这是不合理的(编译器会禁止这样做)。因此为了合理性、安全性,推导出const int是最好的选择。
- auto 不能在函数的参数中使用 (版本低于C++20)
如果为了减少代码重复,模板是一个更好的替代方法
注意:C++20已经允许auto在函数参数中使用了
1 | |
- auto 不能作用于类的非静态成员变量(也就是没有 static 关键字修饰的成员变量)中
1 | |
- auto 关键字不能定义数组 (char[]不行,用char*的可以)
1 | |
Reference : https://stackoverflow.com/questions/7107606/why-cant-i-create-an-array-of-automatic-variables
虽然auto x[4] ={ ....}是一个错误的用法,但是auto x = {1,2,3,4}会推出x是一个std::initializer_list<int>类型。
- auto 不能作用于模板参数
1 | |
Uniform Initialization一致性初始化
在C++11之前初始化一个东西的方式各种各样,为了解决这个问题:

C++11提出了Uniform Initialization, 即变量后边设置花括号来初始化:

编译器可以通过<T>来获取模板中的类型,然后看到{t1,t2,t3...}便做出一个initializer_list<T>,他背后本质是array<T,n>,其中n代表花括号中的个数,调用函数(比如构造函数)时,array内的元素可以被编译器分解注意传送给函数。
那如果一个类就有接受initializer_list<T>类型的构造函数呢?那么就会把initializer_list<T>直接作为参数传递,而无需分解。标准库中的容器都有 带有这种参数的构造函数。
因此initializer_list<T>是有两种方法来被函数解析的:一种是直接作为整体传入函数,另一种是通过背后的array分解成n个元素一个一个传给构造函数。

Initializer_list
花括号可以用来设初值:

Initializer_list的初始化方法和原来小括号的初始化在一些地方是有区别的:

Initializer_list不允许窄化的转型,例如float转int是不允许的,而用7初始化char是允许的。在某些编译器上只会给出警告,有些编译器会给出error。
当存在两个版本的构造函数:分别为普通的方法和Initializer_list的方法,那么调用时如果使用了花括号就调Initializer_list的版本,如果使用了()初始化的方式就会调用普通的构造函数。

那么当没有Initializer_list版本②的存在时,只存在普通版本①时,{}依然可以初始化,编译器会帮我们拆解开{}里的内容,然后再调用到版本①。
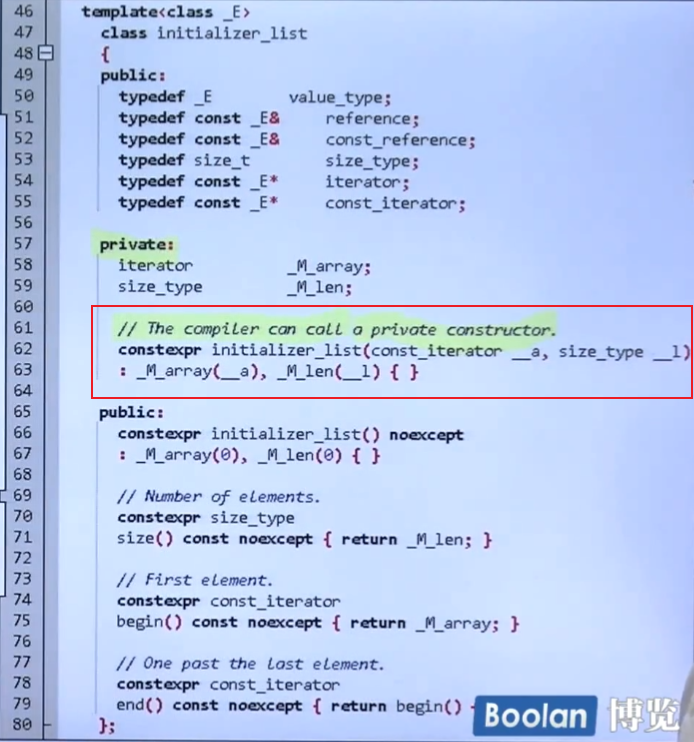
观察下面的代码红框中,编译器可以调用一个私有的Initializer_list的构造函数,因此编译器会构造出来他,给他分配一个array的头的迭代器,array中存有初始化花括号中的数据,这验证了前面我们所说的,Initializer_list的内部实现有array在支持。这也提示我们在拷贝Initializer_list时要小心,这会导致多个迭代器指向同一片区域,他们共有array这一片区域,而非独占,因为这是浅拷贝。
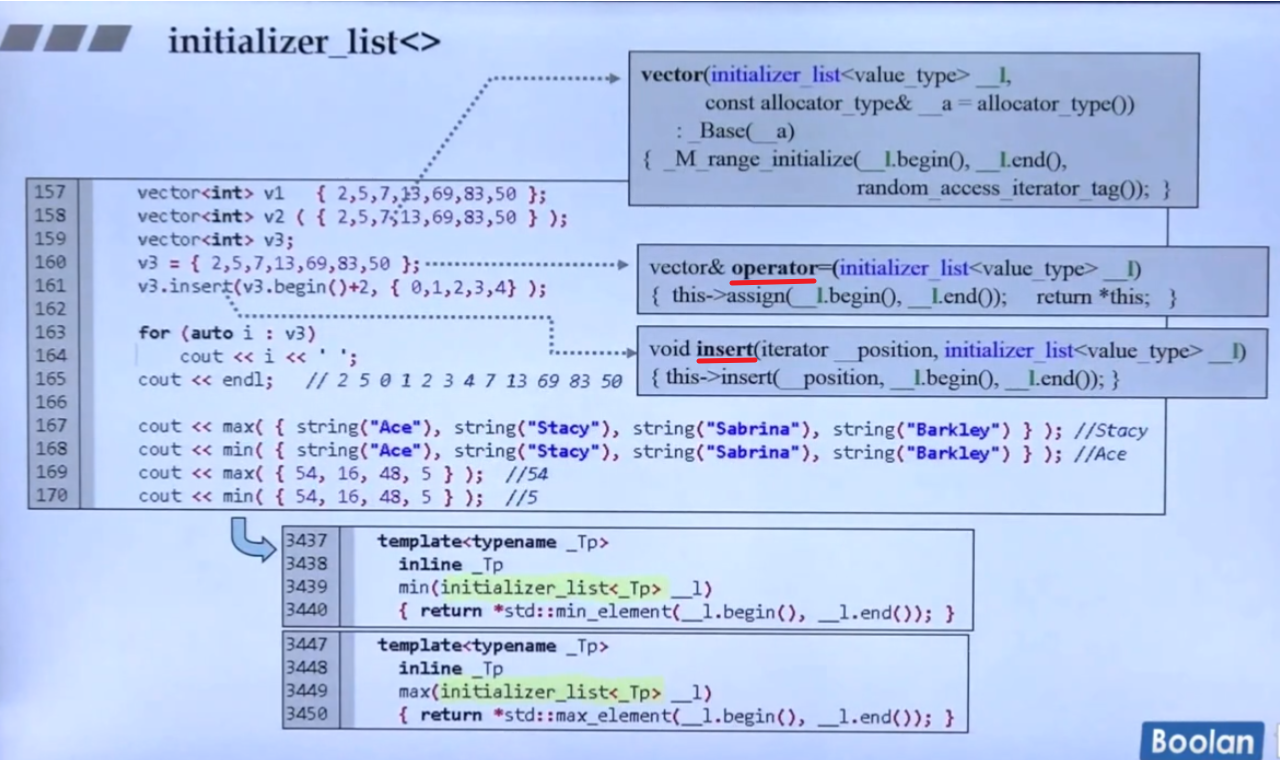
Initializer_list给了我们更多符合直觉的方法,比如min在Initializer_list的支持下,可以在底层用min_element改进一下,从而可以同时比较多个数,同理vector中的insert函数也可以一次insert多个。
Explicit for ctors taking more than one arguement
首先要理解什么是Explicit:原来的博文有详细介绍Explict和non-Explict
Explicit中文译为明白的明确的,简单来说就是不要隐式调用构造函数,如下图。

在C++11以前,隐式调用只存在于单一实参的构造函数(Non-Explict One Arguement),如上图Complex的Complex(int re,int im=0)只存在一个实参,第二个为默认参数,因此它可以发生隐式调用。这很符合直觉,因为c1+5的时候参数就5一个,参数多的时候似乎在C++11前是没有意义的。但是在Initializer_list出现后,好像也可以出现这种用法:t + {1,2,3} ,{1,2,3}去隐式调用了构造函数。那么explicit就有必要做出扩展,表示 多参数的构造函数也不允许被隐式调用。
下面例子: 加上explicit禁止多参数隐式调用的用法。
1 | |
Range-based for statement

编译器对range-based的解释如下:

同理explict也可以禁止range-based中的隐式转换:
vs中的每个string赋值给C会触发隐式调用,而explicit禁止了这种隐式调用。

=default,=delete
1 | |
五大(Big Five)默认实现的:
拷贝构造,移动构造,拷贝复制,移动赋值,析构函数。 其实还有一个默认的Zoo()编译器也会帮我们实现,但是当有一个构造函数自己写出来后,这个空的构造函数便不能使用了。

下面例子:
1.构造函数如果签名不同是可以同时存在的,因为构造函数可以有多个版本。

2.对于编译器可以默认生成的函数(拷贝构造函数/赋值构造函数/移动构造函数/移动赋值函数),如果你自己已经定义了,那就不可以再用default/delete声明
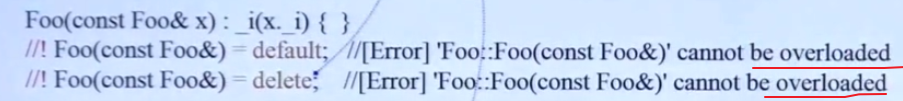

3.普通函数没有=default的操作,但是可以=delete:

4.析构函数不能=delete,但是可以=default
析构函数必须存在进行内存回收,因此不可以delete。=default默认是ok的,符合逻辑直觉。
总结一下:
1.=default只用于BIg-Five(拷贝构造,移动构造,拷贝复制,移动赋值,析构函数)
2.=delete可以用于任何函数身上,除了virtual虚函数(虚函数也有一个=的用法,叫做=0表示纯虚函数)
因此一个空的class在C++处理过后不在是空,会有默认生成的Big-five。
一般来说对于数据成员有指针的类,我们如果希望是深拷贝,那么最好不要用默认default,default只会帮我们做浅拷贝。
Alias Template模板别名
考虑这样的一个用法:利用Vec这个别名可以帮助我们减少模板的定义,比如原来vector需要std::vector<T,MyAlloc<T>>的方法来声明一个vector,现在我们仅仅需要Vec<T>即可。

这是原来的宏定义无法做到给模板一个别名的,无论是define还是typedef:
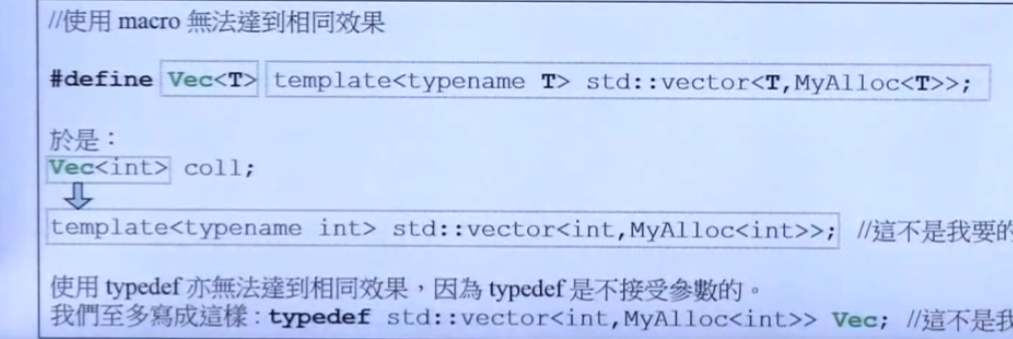
因此这个方法给模板定义了一个别名,叫做模板别名。但是模板别名是无法做到模板偏特化和特化的
考虑如何写一个支持输入容器名字和容器内元素的类型就可以实现对容器遍历?
下面是第一种方法:通过萃取机iterator_traits萃取出容器内元素的类型。
1 | |
还有一种方法需要用到模板模板参数(template template parameter)。
template template parameter,模板的模板参数
模板的模板参数就是:模板中还存在模板作为的参数。注意:函数模板不支持模板的模板参数,类模板才支持这种操作
这个的应用场景是,比如我们想这么用:
1 | |
此时希望list自动辨别出来我们要用的是string,并把list自己的容纳元素类型绑定成string。一个简单的方法就是:
1 | |

这样可以达到我们想要的效果吗?
奇怪的是并不可以:这是因为XCLs中的Container<T>c这部分的T填入的是类型T(string),然而我们平时可以这么用list<string>是因为string填入后,其实<>后面还会有一些默认参数,比如:allocator分配器等….。
但是如果你用T表示,c++就会认为你没有填入后面的默认参数(语言的规定)。简单来说如果你用了T做容器的参数,那么容器的后面的默认参数会失效,你需要自己补上这些参数。
因此我们可以这么用(c++2.0新特性(c++11/14)),使得第二种是对的:即利用using定义模板别名

1 | |
这个模板推导过程是:T推出string,然后从CONT<T>c推出U是string,然后从U再推到T2是string。
下面这并不叫做一个模板模板参数,因为XCLs<string,set<string>>mylist1;中的set<string>就已经绑定好容器的元素类型了,使得class CONT变成set<string>根本没有模板进行推导。
1 | |
Alias Type类型别名(补充一些函数指针的知识)
我们经常可以在标准库看到typedef T value_type的用法,现在利用using也可以做到:using value_Type = T,其实这种看起来更容易阅读一些,在模板别名。
但是他的易读性在函数指针中更凸显,首先介绍一下函数指针:
1 | |
既然double (*pf)(int)是一个函数指针,那么这个指针的类型就是double (*pf)(int)去掉变量名即可,即:double (*)(int)
现在我们已经补充了一些什么是函数指针的知识,下面利用alias type来替代一下试试:
可以直接用func_pointer指代函数指针
1 | |
也可以指代函数原型,然后声明的时候自己加上指针符。
1 | |
值得一提的是:在alias type上,using和typedef没任何区别,只是更易读而已。下面是typedef等效的写法
1 | |
总结using
我们总结一下using:
using在namespace(
using namespace std)和namespace member(using std::cout)。using在class member中

如果你写了using了上面这些,那么在类中你就可以不写namespace
_Base::,直接写函数成员名字即可Alias type和Alias template
noexcept 和 vector扩容中如何利用移动语义扩容 的关联
noexcept表示保证不会出现异常:
1 | |
exp里面若为true,则需要保证foo函数noexcept,反之无需保证。
当不写(exp), 则表示永远不会出现异常:
1 | |
noexcept这个保证不出现异常有什么意义呢?
在可成长的容器,即会发生内存重分配,比如vector和deque,以vector为例子,当扩容时不是原地扩容,而是重新开辟一片内存,然后让之前的内容搬移过来,在搬移时有两种方法,一种是拷贝构造函数,另一种是移动构造函数。
他们有什么区别呢?
What does the copy constructor and move constructor look like behind the scenes, in terms of memory usage?
If any constructor is being called, it means a new object is being created in memory. So, the only difference between a copy constructor and a move constructor is whether the source object that is passed to the constructor will have its member fields copied or moved into the new object.
拷贝构造会把对象的拷贝到另一块内存,包括他的成员变量。而移动构造中,源对象的成员变量不会被复制,而是直接通过指针的方式直接指向原来的内存,直接重复利用这些成员变量,接管源对象的内存,因此无需对成员变量进行复制。
那如果我自己声明了一个Mystring类,我想让他在vector存储的时候,扩容时调用Mystring的移动构造函数怎么办呢?这时就需要我们在MyString的移动构造函数和移动赋值函数上添加noexcept,vector才会利用MyString移动语义。
Override 与 final
当我们想重载vfunc(float),但是不小心重载成了void vfun(int),那么也没人告诉我们这不对,因为编译器会完全认为这是一个全新的函数 。

我们可以在写重载函数时加上一个override函数,表示这个函数是重载的,这样在我们在写错函数签名的时候就会提示我们:这个函数在基类中没有,没法重载,而此时的编译器就不会把他认作新的函数通过编译。

final就是表示这个函数不会被重载,如果子类重载了这个函数就会提示你这是错误的。

这两种关键字都是为了减少 低级错误的发生 而产生的。
decltype
以前写过这个特性相关的内容,这一次只写他的应用:
auto和decltype除了在细节上的差异外(比如是否完美保留const,&等),auto只可以帮助我们不用写这个类型,类似于一个语法糖,而比如我们想把一个类型定义出来,那么还是需要decltype来做:
1 | |
那么decltype除了简单的获取类型外,更重要的意义是在元编程上:

如上图,我们可以用decltype获取出模板容器的迭代器。
在lambda表达式中常用的是auto来表达lambda类型,而在某些容器例如set中,需要指定比较方式的函数类型,因此decltype可以很好的解决这个问题。

Lambda表达式
再谈Variadic Template
Variadic Template变化的是模板参数,即:
- 参数个数—参数个数逐一减少,通过函数递归调用实现
- 参数类型—参数类型变化
这也是Variadic Template的使用场景。
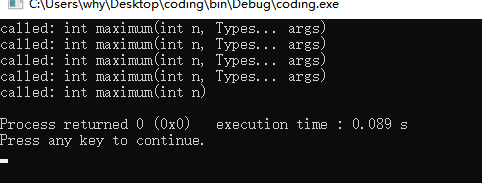
我们自己实现一个如下函数发现,当调用到最后1 + 1形式的时候,即args只剩下一个的时候会调用 maximum(int n)而不会调用 maximum(int n, Types... args)拆成1+0的形式
1 | |
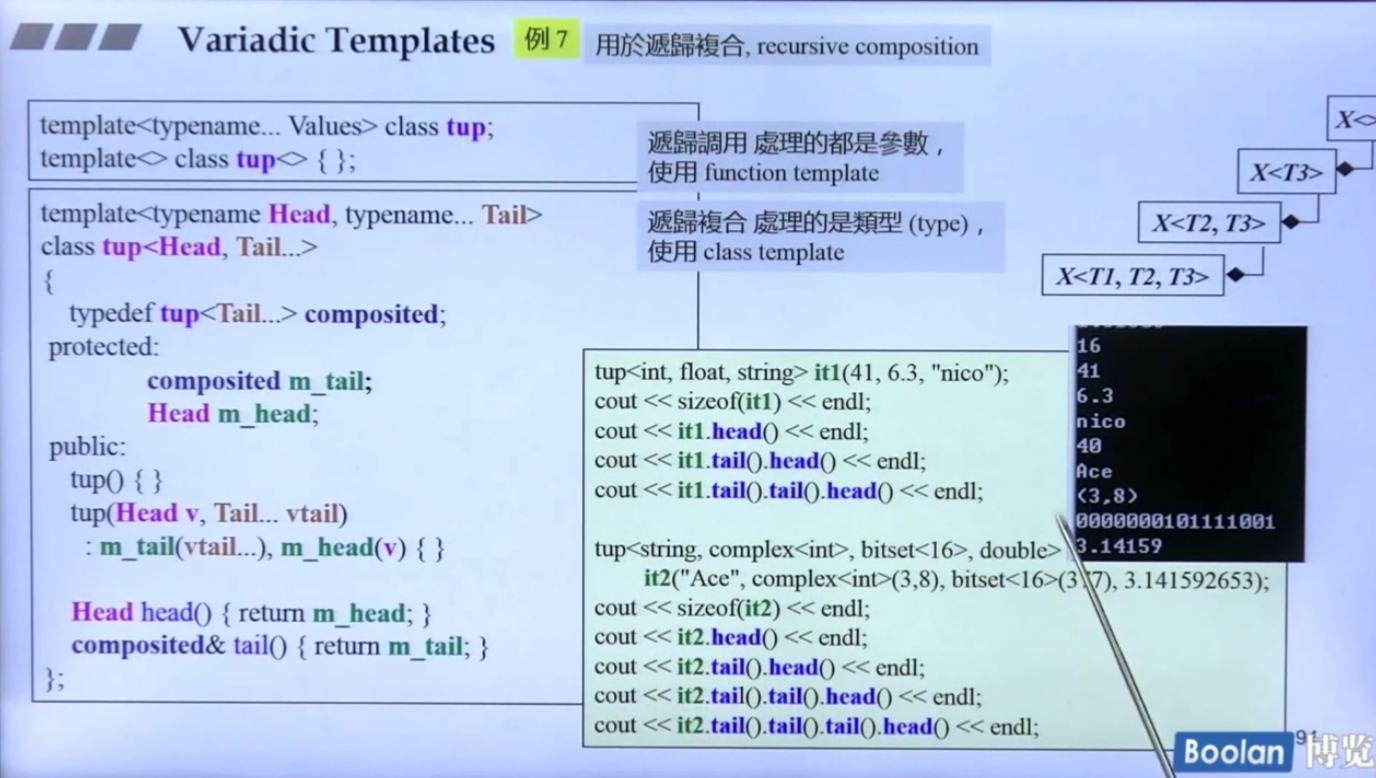
如何输出一个tuple?

1 | |
上述代码有两个版本的struct PRINT_TUPLE,其中第二个做了参数上的偏特化,第二个版本是为了终止循环调用print。
递归继承,以tuple为例:
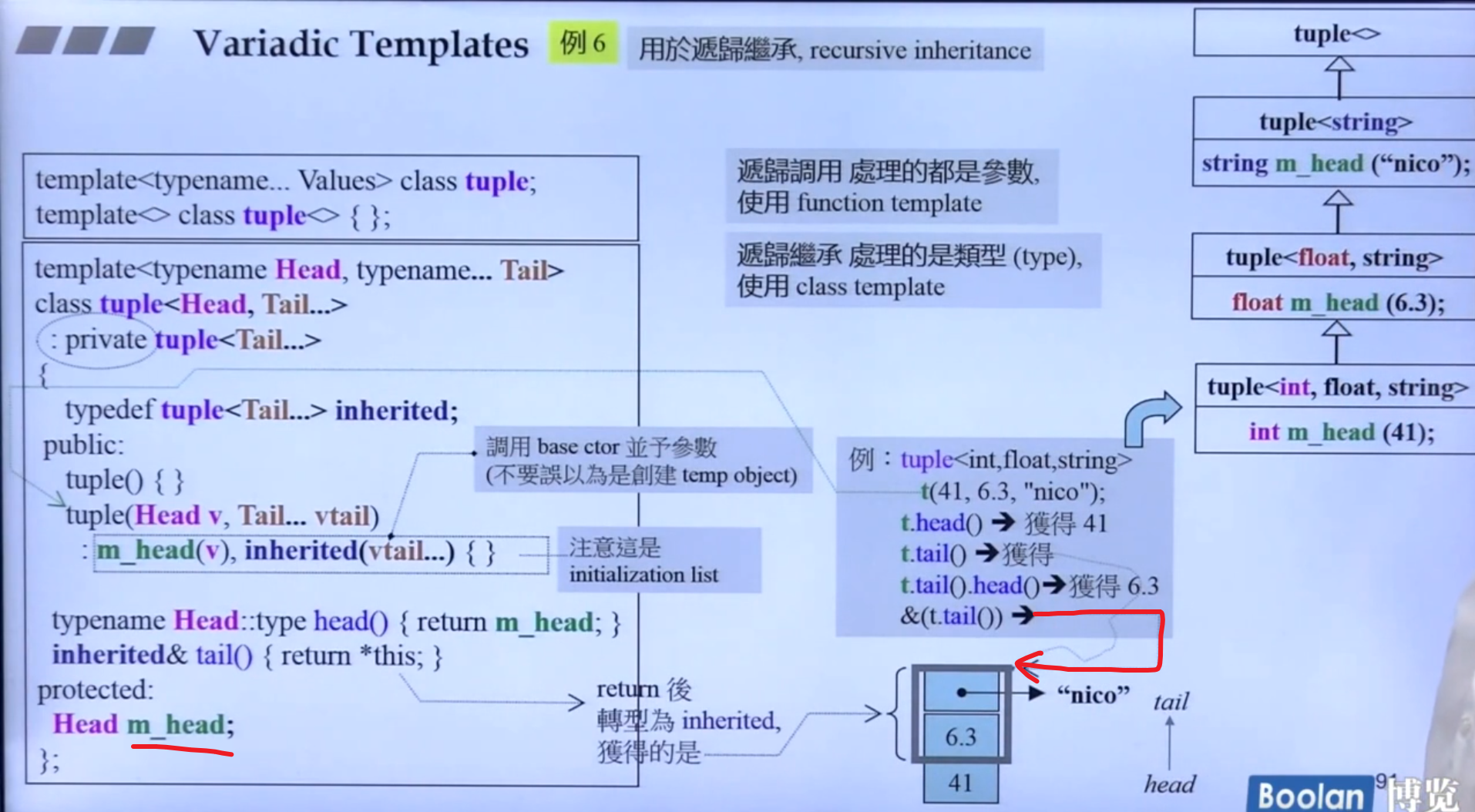
how to fix?
1 | |
递归复合:
右值引用/移动语义
前要:
在本节将终点怎么写一个好的移动语义,前置基础知识在上方链接。
左值/右值

简单来说左值可以出现在operator =左边也可以出现在operator =右边,而右值只可以出现在operator =的右边。临时对象是右值。
其中右值只可以出现在operator =的右边这个说法可能会引发歧义,因为上图中临时对象也出现了operator =左边,也就是说C++为什么要允许给临时对象赋值呢?
解释如下:简单来说算一个历史遗留问题
C++为什么允许给临时对象赋值? - 暮无井见铃的回答 - 知乎 https://www.zhihu.com/question/533946012/answer/2495821727

右值引用
函数的返回值也是一个右值,右值没有一个确定的地址,因此右值是不可以取地址的,需要右值引用这种新的产物来引用右值:

1 | |
如何在调用端/被调用端 告知 右值这个概念
如何解决这个问题呢?

- 如何在调用段告诉我是右值:
- 1.自己本身就是右值:函数返回值,临时变量等…
- 2.自己本身是左值:
move()函数转成右值
- 如何在被调用端专门出一个处理右值的移动函数:
fun(...,...,Type&& x),用右值引用来接着即可。
移动语义是怎么节省开销的
移动构造就是接管了 右值的内存空间,把 右值内的指针成员变量 置为空这个操作可以帮助我们使得右值不调用析构函数,从而延续了右值的生命。
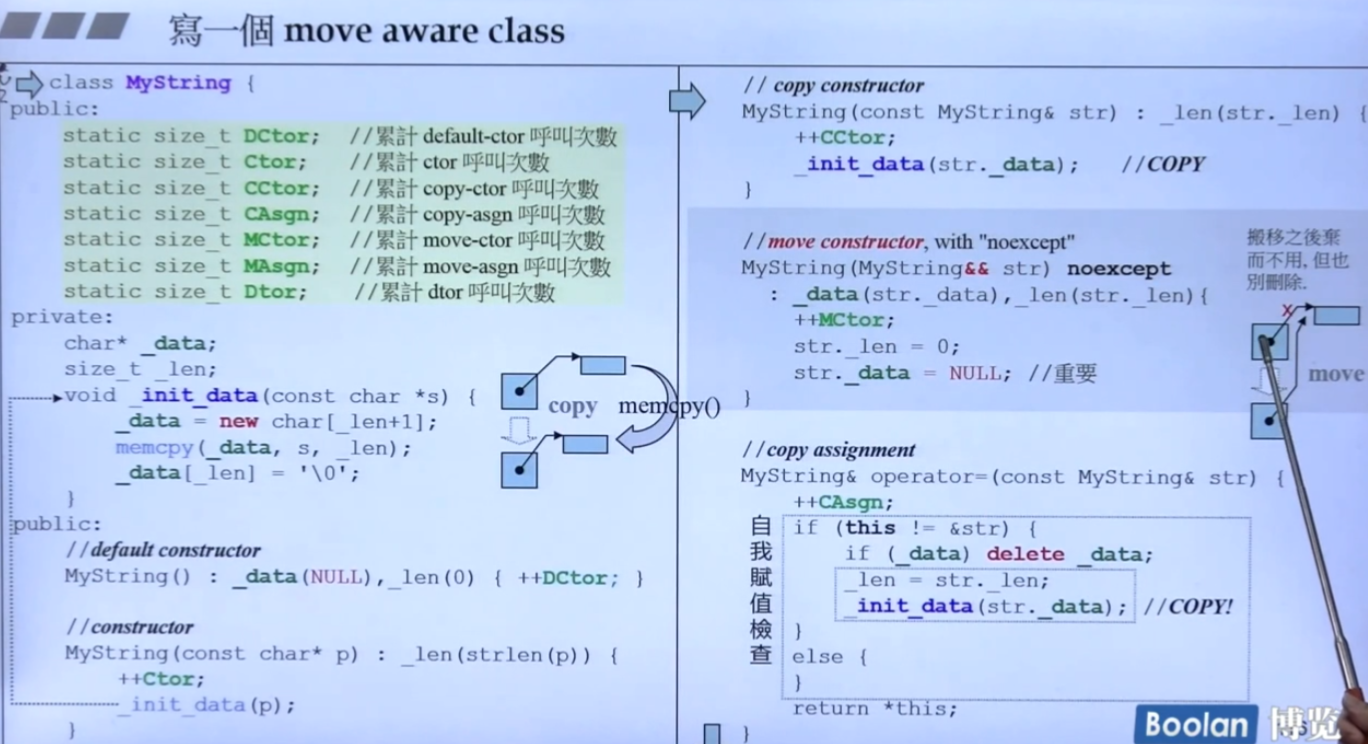
怎么写一个移动语义的构造/赋值函数呢?下面微软的文档讲的很好。
简单来说,首先下面是一个类的定义:
1 | |
这是他的移动构造函数/移动赋值函数:
1 | |
我们来比较下: Copy constructor和Move constructor
1 | |
总结下:
- 如果你的类没有指针那就没必要搞移动语义,也就是说用户自定义类型且内部存在指针类型移动构造才有意义。而互联网上大量的例子都没有指针类型在内部的类也在用移动语义,这是没有意义的。
- 移动语义的函数请把
noexcept加上。 - 在写移动语义时请把source obejct中的所有pointer释放掉(如上代码中的
other._data = nullptr;),释放指针(指针=nullptr)可以保证source object不被析构。
完美转发(Perfect Forwarding)
基本的用法:
1 | |
不完美的转发:
1 | |
1 | |
上面出现了一个常量右值引用,关于常量右值引用有没有用:https://stackoverflow.com/questions/4938875/do-rvalue-references-to-const-have-any-use/60587511#60587511

如何完美转发? 利用std::forward

更多的细节,forward的实现等看这个文章:
谈谈完美转发(Perfect Forwarding):完美转发 = 引用折叠 + 万能引用 + std::forward:https://zhuanlan.zhihu.com/p/369203981
再来一个侯捷老师的例子:
一些很好的相关资料
- C++高阶知识:深入分析移动构造函数及其原理 : https://avdancedu.com/a39d51f9/
- 聊聊C++中的完美转发:https://zhuanlan.zhihu.com/p/161039484
- 谈谈完美转发(Perfect Forwarding):完美转发 = 引用折叠 + 万能引用 + std::forward:https://zhuanlan.zhihu.com/p/369203981
万能引用/引用折叠/完美转发
作者:ReFantasy
链接:https://zhuanlan.zhihu.com/p/50816420
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
引用折叠
我们把 引用折叠 拆解为 引用和 折叠 两个短语来解释。
首先,引用的意思众所周知,当我们使用某个对象的别名的时候就好像直接使用了该对象,这也就是引用的含义。在C++11中,新加入了右值的概念。所以引用的类型就有两种形式:左值引用T&和右值引用T&&。
其次,解释一下折叠的含义。所谓的折叠,就是多个的意思。上面介绍引用分为左值引用和右值引用两种,那么将这两种类型进行排列组合,就有四种情况:
1 | |
这就是所谓的引用折叠!引用折叠的含义到这里就结束了。
但是,当我们在IDE中敲下类似这样的代码:
1 | |
既然不允许使用,为啥还要有引用折叠这样的概念存在 ?
原因就是:引用折叠的应用场景不在这里,引用折叠在模板中的应用:完美转发。
在介绍完美转发之前,我们先介绍一下万能引用。
万能引用
所谓的万能引用并不是C++的语法特性,而是我们利用现有的C++语法,自己实现的一个功能。因为这个功能既能接受左值类型的参数,也能接受右值类型的参数。所以叫做万能引用。
万能引用的形式如下:
1 | |
接下来,我们看一下为什么上面这个函数能万能引用不同类型的参数。
为了更加直观的看到效果,我们借助Boost库的部分功能,重写我们的万能引用函数:
如果不了解Boost库也没关系,Boost库主要是为了帮助大家看到模板里参数类型)
1 | |
通过上面的代码可以清楚的看到,void PrintType(T&& param)可以接受任何类型的参数。嗯,真的是万能引用!到这里的话,万能引用的介绍也就结束了。但是我们只看到了这个东西可以接受任何的参数,却不知道为什么它能这么做。
下面,我们来仔细观察并分析一下main函数中对PrintType()的各个调用结果。
1.传入左值
1 | |
我们将T的推导类型int&(为什么推导int&这个下面会解释)带入模板,得到实例化的类型:
1 | |
重点来了!编译器将T推导为 int& 类型。当我们用 int& 替换掉 T 后,得到 int & &&。
MD,编译器不允许我们自己把代码写成int& &&,它自己却这么干了 =。=
那么 int & &&到底是个什么东西呢?它就是是引用折叠,刚开始就说了啊
下面,就是引用折叠的精髓了。
《Effective Modern C++》
所有的引用折叠最终都代表一个引用,要么是左值引用,要么是右值引用。
规则就是:
如果任一引用为左值引用,则结果为左值引用。否则(即两个都是右值引用),结果为右值引用。
也就是说,int& &&等价于int &。void PrintType(int& && param) == void PrintType(int& param)
所以传入右值之后,函数模板推导的最终版本就是:
1 | |
所以,它能接受一个左值a。
现在我们重新整理一下思路:编译器不允许我们写下类似int & &&这样的代码,但是它自己却可以推导出int & &&代码出来。它的理由就是:编译器虽然推导出T为int&,但是我在最终生成的代码中,利用引用折叠规则,将int & &&等价生成了int &。推导出来的int & &&只是过渡阶段,最终版本并不存在。所以也不算破坏规定。
关于有的人会问,我传入的是一个左值a,并不是一个左值引用,为什么编译器会推导出T 为
int &呢。首先,模板函数参数为
T&& param,也就是说,不管T是什么类型,T&&的最终结果必然是一个引用类型。如果T是
int, 那么T&&就是int &&;如果T为
int &,那么T &&,即int& &&就是int &如果T为
int&&,那么T &&(&& &&)就是int &&。很明显,接受左值的话,T只能推导为
int &。抛开上面这种分析,更直观的来说,你把一个左值扔给万能引用不就是希望他被引用吗,左值的引用那就是左值引用
int&因此在下面
2.明白传入左值的推导结果,剩下的几个调用结果就很明显了:部分中的例子你也可以看到:左值引用(也就是左值) 会被引用成 左值引用,右值会被引用成右值引用,同理右值引用(左值)也会被引用成左值引用

2.明白传入左值的推导结果,剩下的几个调用结果就很明显了:
whysb:下面这些要多考虑下,目前还有问题和误解
1 | |
- 以上就是万能引用的全部了。总结一下,万能引用就是利用模板推导和引用折叠的相关规则,生成不同的实例化模板来接收传进来的参数。
完美转发
好了,有了万能引用。当我们既需要接收左值类型,又需要接收右值类型的时候,再也不用分开写两个重载函数了。那么,什么情况下,我们需要一个函数,既能接收左值,又能接收右值呢?
答案就是:转发的时候。
于是,我们马上想到了万能引用。又于是兴冲冲的改写了以上的代码如下:
1 | |
我们执行上面的代码,按照预想,在main中我们给 PrintType 分别传入一个左值和一个右值。PrintType将参数转发给 f() 函数。f()有两个重载,分别接收左值和右值。
正常的情况下,PrintType(a);应该打印f(T&),PrintType(int());应该打印f(T&&)。
但是,真实的输出结果是
1 | |
为什么明明传入了不同类型的值,但是void f()函数只调用了void f(int &)的版本。这说明,不管我们传入的参数类型是什么,在void PrintType(T&& param)函数的内部,param都是一个左值引用!
没错,事实就是这样。当外部传入参数给 PrintType 函数时,param既可以被初始化为左值引用,也可以被初始化为右值引用,取决于我们传递给 PrintType 函数的实参类型。但是,当我们在函数 PrintType 内部,将param传递给另一个函数的时候,此时,param是被当作左值进行传递的。 应为这里的 param 是个具名的对象。我们不进行详细的探讨了。大家只需要记住,任何的函数内部,对形参的直接使用,都是按照左值进行的。
WTF,万能引用内部形参都变成了左值!那我还要什么万能引用啊!直接改为左值引用不就好了!!
别急,我们可以通过一些其它的手段改变这个情况,比如使用 std::forward 。
在万能引用的一节,我们应该有所感觉了。使用万能引用的时候,如果传入的实参是个右值(包括右值引用),那么,模板类型 T 被推导为 实参的类型(没有引用属性),如果传入实参是个左值,T被推导为左值引用。也就是说,模板中的 T 保存着传递进来的实参的信息,我们可以利用 T 的信息来强制类型转换我们的 param 使它和实参的类型一致。
具体的做法就是,将模板函数void PrintType(T&& param)中对f(param)的调用,改为f(std::forward<T>(param));然后重新运行一下程序。输出如下:
1 | |
嗯,完美的转发!
那么,std::forward是怎么利用到 T 的信息的呢。
std::forward的源码形式大致是这样:
1 | |
我们来仔细分析一下这段代码:
我们可以看到,不管T是值类型,还是左值引用,还是右值引用,T&经过引用折叠,都将是左值引用类型。也就是forward 以左值引用的形式接收参数 param, 然后 通过将param进行强制类型转换 static_cast
所以,我们分析一下传递给 PrintType 的实参类型,并将推导的 T 类型代入 forward 就可以知道转发的结果了。
1.传入 PrintType 实参是右值类型:
根据以上的分析,可以知道T将被推导为值类型,也就是不带有引用属性,假设为 int 。那么,将T = int 带入forward。
1 | |
param在forward内被强制类型转换为int &&(static_cast<int&&>(param)), 然后按照int && 返回,两个右值引用最终还是右值引用。最终保持了实参的右值属性,转发正确。
2.传入 PrintType 实参是左值类型:
根据以上的分析,可以知道T将被推导为左值引用类型,假设为int&。那么,将T = int& 带入forward。
1 | |
引用折叠一下就是:
1 | |
看到这里,我想就不用再多说什么了。传递给 PrintType 左值,forward返回一个左值引用,保留了实参的左值属性,转发正确。
到这里,完美转发也就介绍完毕了。
总结一下他们三者的关系就是:通过引用折叠,我们实现了万能模板。在万能模板内部,利用forward函数,本质上是又利用了一遍引用折叠,实现了完美转发。其中,模板推导扮演了至关重要的角色。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!