《EffectiveModernC++》第四章:智能指针
第四章 智能指针
item18:对于独占资源使用std::unique_ptr
对于auto_ptr这个C++98的产物,已经被移除了,他的升级版其实就是unique_ptr,
auto_ptr的失败是由于缺少移动语义,具体可以看:
https://zhuanlan.zhihu.com/p/551883955
这一节这里不过多描述,以前读过很多相关的了,这里基本的不再提起。这里提几个原文中几个有趣的东西:
首先要将的第一个是unique_ptr可以自定义删除器
默认情况下,销毁将通过delete进行,但是在构造过程中,std::unique_ptr对象可以被设置为使用(对资源的)自定义删除器:当资源需要销毁时可调用的任意函数(或者函数对象,包括lambda表达式)。如果通过makeInvestment创建的对象不应仅仅被delete,而应该先写一条日志,makeInvestment可以以如下方式实现。
1 | |
初始化std::unique_ptr<Investment, decltype(delInvmt)> pInv(nullptr, delInvmt);即可。
上面这段代码第二个有意思的是,尝试将原始指针(比如new创建)赋值给std::unique_ptr通不过编译,因为是一种从原始指针到智能指针的隐式转换。这种隐式转换会出问题,所以C++11的智能指针禁止这个行为。这就是通过reset来让pInv接管通过new创建的对象的所有权的原因。
item19:对于共享资源使用std::shared_ptr
shared_ptr的引用计数意味着几个性能问题:
std::shared_ptr大小是原始指针的两倍,因为它内部包含一个指向资源的原始指针,还包含一个指向资源的引用计数值的原始指针。(这种实现法并不是标准要求的,但是我(指原书作者Scott Meyers)熟悉的所有标准库都这样实现。)- 引用计数的内存必须动态分配。 概念上,引用计数与所指对象关联起来,但是实际上被指向的对象不知道这件事情(译注:不知道有一个关联到自己的计数值)。因此它们没有办法存放一个引用计数值。(一个好消息是任何对象——甚至是内置类型的——都可以由
std::shared_ptr管理。)Item21会解释使用std::make_shared创建std::shared_ptr可以避免引用计数的动态分配,但是还存在一些std::make_shared不能使用的场景,这时候引用计数就会动态分配。 - 递增递减引用计数必须是原子性的,因为多个reader、writer可能在不同的线程。比如,指向某种资源的
std::shared_ptr可能在一个线程执行析构(于是递减指向的对象的引用计数),在另一个不同的线程,std::shared_ptr指向相同的对象,但是执行的却是拷贝操作(因此递增了同一个引用计数)。原子操作通常比非原子操作要慢,所以即使引用计数通常只有一个word大小,你也应该假定读写它们是存在开销的。
类似std::unique_ptr(参见Item18),std::shared_ptr使用delete作为资源的默认销毁机制,但是它也支持自定义的删除器。这种支持有别于std::unique_ptr。对于std::unique_ptr来说,删除器类型是智能指针类型的一部分。对于std::shared_ptr则不是:
1 | |
std::shared_ptr的设计更为灵活。考虑有两个std::shared_ptr<Widget>,每个自带不同的删除器(比如通过lambda表达式自定义删除器):
1 | |
因为pw1和pw2有相同的类型,所以它们都可以放到存放那个类型的对象的容器中:
1 | |
另一个不同于std::unique_ptr的地方是,指定自定义删除器不会改变std::shared_ptr对象的大小。不管删除器是什么,一个std::shared_ptr对象都是两个指针大小。你可能会感到疑惑,那么删除器在哪儿里存储的呢?shared_ptr类中有一个指向引用计数块(或者叫做控制块)的指针,控制块里会保存删除器。因此shared_ptr对象的大小是不会因为删除器而改变的。
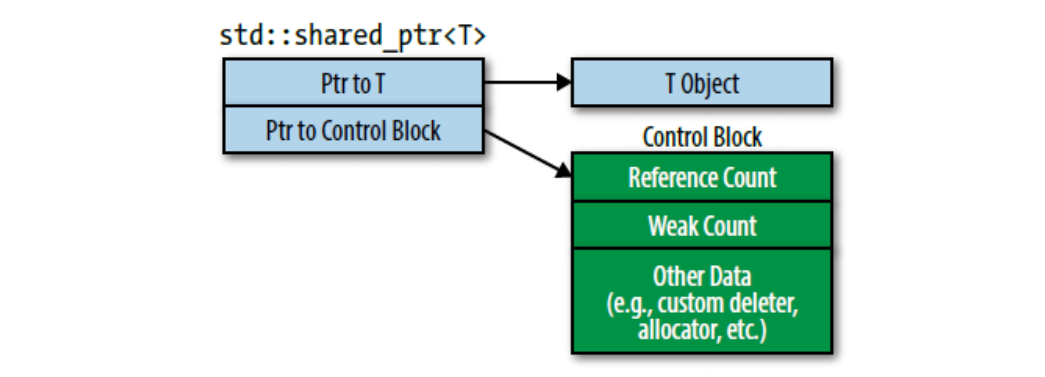
谈到控制块,那么什么时候会创建控制块呢?控制块的创建会遵循下面几条规则:
std::make_shared(参见Item21)总是创建一个控制块。它创建一个要指向的新对象,所以可以肯定std::make_shared调用时对象不存在其他控制块。- 当从独占指针(即
std::unique_ptr或者std::auto_ptr)上构造出std::shared_ptr时会创建控制块。独占指针没有使用控制块,所以指针指向的对象没有关联控制块。(作为构造的一部分,std::shared_ptr侵占独占指针所指向的对象的独占权,所以独占指针被设置为null) - 当从原始指针上构造出
std::shared_ptr时会创建控制块。如果你想从一个早已存在控制块的对象上创建std::shared_ptr,你将假定传递一个std::shared_ptr或者std::weak_ptr(参见Item20)作为构造函数实参,而不是原始指针。用std::shared_ptr或者std::weak_ptr作为构造函数实参创建std::shared_ptr不会创建新控制块,因为它可以依赖传递来的智能指针指向控制块。
这些规则造成的后果就是从原始指针上构造超过一个std::shared_ptr就会让你走上未定义行为的快车道,因为指向的对象有多个控制块关联。多个控制块意味着多个引用计数值,多个引用计数值意味着对象将会被销毁多次(每个引用计数一次)。那意味着像下面的代码是有问题的,很有问题,问题很大:
1 | |
第一,避免传给
std::shared_ptr构造函数原始指针。通常替代方案是使用std::make_shared(参见Item21),不过上面例子中,我们使用了自定义删除器,用std::make_shared就没办法做到。第二,如果你必须传给
std::shared_ptr构造函数原始指针,直接传new出来的结果,不要传指针变量。如果上面代码第一部分这样重写:
1 | |
会少了很多从原始指针上构造第二个std::shared_ptr的诱惑。相应的,创建spw2也会很自然的用spw1作为初始化参数(即用std::shared_ptr拷贝构造函数),那就没什么问题了:
1 | |
一个尤其令人意外的地方是使用this指针作为std::shared_ptr构造函数实参的时候可能导致创建多个控制块。假设我们的程序使用std::shared_ptr管理Widget对象,我们有一个数据结构用于跟踪已经处理过的Widget对象:
1 | |
继续,假设Widget有一个用于处理的成员函数:
1 | |
对于Widget::process看起来合理的代码如下:
1 | |
注释已经说了这是错的——或者至少大部分是错的。(错误的部分是传递this,而不是使用了emplace_back。如果你不熟悉emplace_back,参见Item42)。上面的代码可以通过编译,但是向std::shared_ptr的容器传递一个原始指针(this),std::shared_ptr会由此为指向的Widget(*this)创建一个控制块。那看起来没什么问题,直到你意识到如果成员函数外面早已存在指向那个Widget对象的指针,此时这个控制块的引用计数是不正确的,这完全是未定义行为。
std::shared_ptrAPI已有处理这种情况的设施。它的名字可能是C++标准库中最奇怪的一个:std::enable_shared_from_this。如果你想创建一个用std::shared_ptr管理的类,这个类能够用this指针安全地创建一个std::shared_ptr,std::enable_shared_from_this就可作为基类的模板类。在我们的例子中,Widget将会继承自std::enable_shared_from_this:
1 | |
std::enable_shared_from_this是一个基类模板。它的模板参数总是某个继承自它的类,所以Widget继承自std::enable_shared_from_this<Widget>。代码完全合法,而且它背后的设计模式也是没问题的,并且这种设计模式还有个标准名字,尽管该名字和std::enable_shared_from_this一样怪异。这个标准名字就是奇异递归模板模式(The Curiously Recurring Template Pattern(CRTP))。
std::enable_shared_from_this定义了一个成员函数,成员函数会创建指向当前对象的std::shared_ptr却不创建多余控制块。这个成员函数就是shared_from_this,无论在哪当你想在成员函数中使用std::shared_ptr指向this所指对象时都请使用它。这里有个Widget::process的安全实现:
1 | |
要想防止客户端在存在一个指向对象的std::shared_ptr前先调用含有shared_from_this的成员函数,继承自std::enable_shared_from_this的类通常将它们的构造函数声明为private,并且让客户端通过返回std::shared_ptr的工厂函数创建对象。以Widget为例,代码可以是这样:
1 | |
现在,你可能隐约记得我们讨论控制块的动机是想了解有关std::shared_ptr的成本。既然我们已经知道了怎么避免创建过多控制块,就让我们回到原来的主题。
控制块通常只占几个word大小,自定义删除器和分配器可能会让它变大一点。通常控制块的实现比你想的更复杂一些。它使用继承,甚至里面还有一个虚函数(用来确保指向的对象被正确销毁)。这意味着使用std::shared_ptr还会招致控制块使用虚函数带来的成本。
最后来谈一谈,std::shared_ptr不能处理的另一个东西是数组(注意:C+17后可以了)。和std::unique_ptr不同的是,std::shared_ptr的API设计之初就是针对单个对象的,没有办法std::shared_ptr<T[]>。
一次又一次,“聪明”的程序员踌躇于是否该使用std::shared_ptr<T>指向数组,然后传入自定义删除器来删除数组(即delete [])。这可以通过编译,但是是一个糟糕的主意。
一方面,std::shared_ptr没有提供operator[] (这里需要注意,C++17提供了),所以数组索引操作需要借助怪异的指针算术。
另一方面,std::shared_ptr支持转换为指向基类的指针,这对于单个对象来说有效,但是当用于数组类型时相当于在类型系统上开洞。(出于这个原因,std::unique_ptr<T[]> API禁止这种转换。)更重要的是,C++11已经提供了很多内置数组的候选方案(比如std::array,std::vector,std::string)。声明一个指向傻瓜数组的智能指针(译注:也是”聪明的指针“之意)几乎总是表示着糟糕的设计。
请记住:
std::shared_ptr为有共享所有权的任意资源提供一种自动垃圾回收的便捷方式。- 较之于
std::unique_ptr,std::shared_ptr对象通常大两倍,控制块会产生开销,需要原子性的引用计数修改操作。 - 默认资源销毁是通过
delete,但是也支持自定义删除器。删除器的类型是什么对于std::shared_ptr的类型没有影响。 - 避免从原始指针变量上创建
std::shared_ptr。
item20:当std::shared_ptr可能悬空时使用std::weak_ptr
自相矛盾的是,如果有一个像std::shared_ptr(见Item19)的但是不参与资源所有权共享的指针是很方便的。换句话说,是一个类似std::shared_ptr但不影响对象引用计数的指针。这种类型的智能指针必须要解决一个std::shared_ptr不存在的问题:可能指向已经销毁的对象。一个真正的智能指针应该跟踪所指对象,在悬空时知晓,悬空(dangle)就是指针指向的对象不再存在。这就是对std::weak_ptr最精确的描述。
std::weak_ptr不能解引用,也不能测试是否为空值。std::weak_ptr通常从std::shared_ptr上创建。当从std::shared_ptr上创建std::weak_ptr时两者指向相同的对象,但是std::weak_ptr不会影响所指对象的引用计数:
1 | |
悬空的std::weak_ptr被称作已经expired(过期)。你可以用它直接做测试:
1 | |
但是通常你期望的是检查std::weak_ptr是否已经过期,如果没有过期则访问其指向的对象。这做起来可不是想着那么简单。因为缺少解引用操作,没有办法写这样的代码。即使有,将检查和解引用分开会引入竞态条件:在调用expired和解引用操作之间,另一个线程可能对指向这对象的std::shared_ptr重新赋值或者析构,并由此造成对象已析构。这种情况下,你的解引用将会产生未定义行为。
你需要的是一个原子操作检查std::weak_ptr是否已经过期,如果没有过期就访问所指对象。这可以通过从std::weak_ptr创建std::shared_ptr来实现,具体有两种形式可以从std::weak_ptr上创建std::shared_ptr,具体用哪种取决于std::weak_ptr过期时你希望std::shared_ptr表现出什么行为。
一种形式是std::weak_ptr::lock,它返回一个std::shared_ptr,如果std::weak_ptr过期这个std::shared_ptr为空:
1 | |
另一种形式是以std::weak_ptr为实参构造std::shared_ptr。这种情况中,如果std::weak_ptr过期,会抛出一个异常:
1 | |
但是你可能还想知道为什么std::weak_ptr就有用了。考虑一个工厂函数,它基于一个唯一ID从只读对象上产出智能指针。根据Item18的描述,工厂函数会返回一个该对象类型的std::unique_ptr:
可能到现在你还没有看到weak_ptr有什么实际的作用:下面我们举个例子
考虑一个工厂函数,它基于一个唯一ID从只读对象上产出智能指针。根据Item18的描述,工厂函数会返回一个该对象类型的std::unique_ptr:
1 | |
如果调用loadWidget是一个昂贵的操作(比如它操作文件或者数据库I/O)并且重复使用ID很常见,一个合理的优化是再写一个函数除了完成loadWidget做的事情之外再缓存它的结果。当每个请求获取的Widget阻塞了缓存也会导致本身性能问题,所以另一个合理的优化可以是当Widget不再使用的时候销毁它的缓存。
对于可缓存的工厂函数,返回std::unique_ptr不是好的选择。调用者应该接收缓存对象的智能指针,调用者也应该确定这些对象的生命周期,但是缓存本身也需要一个指针指向它所缓存的对象。缓存对象的指针需要知道它是否已经悬空,因为当工厂客户端使用完工厂产生的对象后,对象将被销毁,关联的缓存条目会悬空。所以缓存应该使用std::weak_ptr,这可以知道是否已经悬空。这意味着工厂函数返回值类型应该是std::shared_ptr,因为只有当对象的生命周期由std::shared_ptr管理时,std::weak_ptr才能检测到悬空。
下面是一个临时凑合的loadWidget的缓存版本的实现:
1 | |
第二个用例:观察者设计模式(Observer design pattern)。
此模式的主要组件是subjects(状态可能会更改的对象)和observers(状态发生更改时要通知的对象)。在大多数实现中,每个subject都包含一个数据成员,该成员持有指向其observers的指针。这使subjects很容易发布状态更改通知。subjects对控制observers的生命周期(即它们什么时候被销毁)没有兴趣,但是subjects对确保另一件事具有极大的兴趣,那事就是一个observer被销毁时,不再尝试访问它。一个合理的设计是每个subject持有一个std::weak_ptrs容器指向observers,因此可以在使用前检查是否已经悬空。
作为最后一个使用std::weak_ptr的例子,考虑一个持有三个对象A、B、C的数据结构,A和C共享B的所有权,因此持有std::shared_ptr:

假定从B指向A的指针也很有用。应该使用哪种指针?

有三种选择:
- 原始指针。使用这种方法,如果
A被销毁,但是C继续指向B,B就会有一个指向A的悬空指针。而且B不知道指针已经悬空,所以B可能会继续访问,就会导致未定义行为。 std::shared_ptr。这种设计,A和B都互相持有对方的std::shared_ptr,导致的std::shared_ptr环状结构(A指向B,B指向A)阻止A和B的销毁。甚至A和B无法从其他数据结构访问了(比如,C不再指向B),每个的引用计数都还是1。如果发生了这种情况,A和B都被泄漏:程序无法访问它们,但是资源并没有被回收。std::weak_ptr。这避免了上述两个问题。如果A被销毁,B指向它的指针悬空,但是B可以检测到这件事。尤其是,尽管A和B互相指向对方,B的指针不会影响A的引用计数,因此在没有std::shared_ptr指向A时不会导致A无法被销毁。
使用std::weak_ptr显然是这些选择中最好的。但是,需要注意使用std::weak_ptr打破std::shared_ptr循环并不常见。在严格分层的数据结构比如树中,子节点只被父节点持有。当父节点被销毁时,子节点就被销毁。从父到子的链接关系可以使用std::unique_ptr很好的表征。从子到父的反向连接可以使用原始指针安全实现,因为子节点的生命周期肯定短于父节点。因此没有子节点解引用一个悬垂的父节点指针这样的风险。
当然,不是所有的使用指针的数据结构都是严格分层的,所以当发生这种情况时,比如上面所述缓存和观察者列表的实现之类的,知道std::weak_ptr随时待命也是不错的。
从效率角度来看,std::weak_ptr与std::shared_ptr基本相同。两者的大小是相同的,使用相同的控制块(参见Item19),构造、析构、赋值操作涉及引用计数的原子操作。这可能让你感到惊讶,因为本条款开篇就提到std::weak_ptr不影响引用计数。我写的是std::weak_ptr不参与对象的共享所有权,因此不影响指向对象的引用计数。实际上在控制块中还是有第二个引用计数,std::weak_ptr操作的是第二个引用计数。想了解细节的话,继续看Item21吧。
请记住:
- 用
std::weak_ptr替代可能会悬空的std::shared_ptr。 std::weak_ptr的潜在使用场景包括:缓存、观察者列表、打破std::shared_ptr环状结构。
item21:优先考虑使用std::make_unique和std::make_shared,而非直接使用new
C++11出现了make_shared, C++14出现了make_unqiue
一个基础版本的std::make_unique是很容易自己写出的,如下:
1 | |
正如你看到的,make_unique只是将它的参数完美转发到所要创建的对象的构造函数,从new产生的原始指针里面构造出std::unique_ptr,然后返回这个std::unique_ptr即可。
用make函数有什么好处呢?
①首先就是可以用auto,方便,不用重复写类型:
例如:
1 | |
关键区别:使用new的版本重复了类型,但是make函数的版本没有。
②然后是异常安全性:
假设我们有个函数按照某种优先级处理Widget:
1 | |
值传递std::shared_ptr可能看起来很可疑,但是Item41解释了,如果processWidget总是复制std::shared_ptr(例如,通过将其存储在已处理的Widget的一个数据结构中),那么这可能是一个合理的设计选择。
现在假设我们有一个函数来计算相关的优先级,
1 | |
并且我们在调用processWidget时使用了new而不是std::make_shared:
1 | |
如注释所说,这段代码可能在new一个Widget时发生泄漏。为何?调用的代码和被调用的函数都用std::shared_ptrs,且std::shared_ptrs就是设计出来防止泄漏的。它们会在最后一个std::shared_ptr销毁时自动释放所指向的内存。如果每个人在每个地方都用std::shared_ptrs,这段代码怎么会泄漏呢?
答案和编译器将源码转换为目标代码有关。在运行时,一个函数的实参必须先被计算,这个函数再被调用,所以在调用processWidget之前,必须执行以下操作,processWidget才开始执行:
- 表达式“
new Widget”必须计算,例如,一个Widget对象必须在堆上被创建 - 负责管理
new出来指针的std::shared_ptr<Widget>构造函数必须被执行 computePriority必须运行
编译器不需要按照执行顺序生成代码。“new Widget”必须在std::shared_ptr的构造函数被调用前执行,因为new出来的结果作为构造函数的实参,但computePriority可能在这之前,之后,或者之间执行。也就是说,编译器可能按照这个执行顺序生成代码:
- 执行“
new Widget” - 执行
computePriority - 运行
std::shared_ptr构造函数
如果按照这样生成代码,并且在运行时computePriority产生了异常,那么第一步动态分配的Widget就会泄漏。因为它永远都不会被第三步的std::shared_ptr所管理了。
使用std::make_shared可以防止这种问题。调用代码看起来像是这样:
1 | |
在运行时,std::make_shared和computePriority其中一个会先被调用。
如果是
std::make_shared先被调用,在computePriority调用前,动态分配Widget的原始指针会安全的保存在作为返回值的std::shared_ptr中。如果
computePriority产生一个异常,那么std::shared_ptr析构函数将确保管理的Widget被销毁。如果首先调用computePriority并产生一个异常,那么std::make_shared将不会被调用,因此也就不需要担心动态分配Widget(会泄漏)。
③make函数还有的好处是 效率的提升:
使用std::make_shared允许编译器生成更小,更快的代码,并使用更简洁的数据结构。考虑以下对new的直接使用:
1 | |
显然,这段代码需要进行内存分配,但它实际上执行了两次。Item19解释了每个std::shared_ptr指向一个控制块,其中包含被指向对象的引用计数,还有其他东西。这个控制块的内存在std::shared_ptr构造函数中分配。因此,直接使用new需要为Widget进行一次内存分配,为控制块再进行一次内存分配。
如果使用std::make_shared代替:
1 | |
一次分配足矣。这是因为std::make_shared分配一块内存,同时容纳了Widget对象和控制块。这种优化减少了程序的静态大小,因为代码只包含一个内存分配调用,并且它提高了可执行代码的速度,因为内存只分配一次。此外,使用std::make_shared避免了对控制块中的某些簿记信息的需要,潜在地减少了程序的总内存占用。
make函数看起来很不错,当然在某些时候情况下他也是有缺点的:
①make函数都不允许指定自定义删除器(见Item18和19)
但是std::unique_ptr和std::shared_ptr有构造函数这么做。有个Widget的自定义删除器:
1 | |
创建一个使用它的智能指针只能直接使用new:
1 | |
对于make函数,没有办法做同样的事情。
②make函数中的 () 和{}初始化问题
make函数第二个限制来自于其实现中的语法细节。Item7解释了,当构造函数重载,有使用std::initializer_list作为参数的重载形式和不用其作为参数的的重载形式,用花括号创建的对象更倾向于使用std::initializer_list作为形参的重载形式,而用小括号创建对象将调用不用std::initializer_list作为参数的的重载形式。make函数会将它们的参数完美转发给对象构造函数,但是它们是使用小括号还是花括号?对某些类型,问题的答案会很不相同。例如,在这些调用中。
1 | |
上面的结果是两种调用都创建了10个元素,每个值为20的std::vector, 说明完美转发中使用的是小括号,如果使用的花括号,那么上面的代码就是含有两个元素的10和20的vector了。
但是,Item30介绍了一个变通的方法:使用auto类型推导从花括号初始化创建std::initializer_list对象(见Item2),然后将auto创建的对象传递给make函数。
1 | |
对于std::unique_ptr,只有这两种情景(自定义删除器和花括号初始化)使用make函数有点问题。
对于std::shared_ptr和它的make函数,还有2个问题。都属于边缘情况,但是一些开发者常碰到,你也可能是其中之一。
③有自定义内存管理的类, 不建议使用make_shared。
一些类重载了operator new和operator delete。这些函数的存在意味着对这些类型的对象的全局内存分配和释放是不合常规的。设计这种定制操作往往只会精确的分配、释放对象大小的内存。例如,Widget类的operator new和operator delete只会处理sizeof(Widget)大小的内存块的分配和释放。这种系列行为不太适用于std::shared_ptr对自定义分配(通过std::allocate_shared)和释放(通过自定义删除器)的支持,因为std::allocate_shared需要的内存总大小不等于动态分配的对象大小,还需要再加上控制块大小。因此,使用make函数去创建重载了operator new和operator delete类的对象是个典型的糟糕想法。
④对象类型非常大,而且销毁最后一个std::shared_ptr和销毁最后一个std::weak_ptr之间的时间很长,那么在销毁对象和释放它所占用的内存之间可能会出现延迟
如果对象类型非常大,而且销毁最后一个std::shared_ptr和销毁最后一个std::weak_ptr之间的时间很长,那么在销毁对象和释放它所占用的内存之间可能会出现延迟。
1 | |
直接只用new,一旦最后一个std::shared_ptr被销毁,ReallyBigType对象的内存就会被释放:
1 | |
导致这个的原因就是我们所认为make_shared的效率优势: 控制块和对象一起进行内存分配。同理std::weak_ptrs比对应的std::shared_ptrs活得更久的也要注意,因为weak count也在控制块里。
最后我们讨论一个场景,当你有不得不用new的理由时,(比如上述的几个理由),保证异常安全性需要使用变量提前保存起来只能指针,但是为了更高效,还需要注意一点,就是 把左值智能指针用std::move转为右值再传入函数。
例如,考虑我们前面讨论过的processWidget函数,对其非异常安全调用的一个小修改。这一次,我们将指定一个自定义删除器:
1 | |
这是非异常安全调用:
1 | |
回想一下:如果computePriority在“new Widget”之后,而在std::shared_ptr构造函数之前调用,并且如果computePriority产生一个异常,那么动态分配的Widget将会泄漏。
这里使用自定义删除排除了对std::make_shared的使用,因此避免出现问题的方法是将Widget的分配和std::shared_ptr的构造放入它们自己的语句中,然后使用得到的std::shared_ptr调用processWidget。这是该技术的本质,不过,正如我们稍后将看到的,我们可以对其进行调整以提高其性能:
1 | |
这是可行的,因为std::shared_ptr获取了传递给它的构造函数的原始指针的所有权,即使构造函数产生了一个异常。此例中,如果spw的构造函数抛出异常(比如无法为控制块动态分配内存),仍然能够保证cusDel会在“new Widget”产生的指针上调用。
一个小小的性能问题是,在非异常安全调用中,我们将一个右值传递给processWidget:
1 | |
但是在异常安全调用中,我们传递了左值:
1 | |
因为processWidget的std::shared_ptr形参是传值,从右值构造只需要移动,而传递左值构造需要拷贝。对std::shared_ptr而言,这种区别是有意义的,因为拷贝std::shared_ptr需要对引用计数原子递增,移动则不需要对引用计数有操作。为了使异常安全代码达到非异常安全代码的性能水平,我们需要用std::move将spw转换为右值(见Item23):
1 | |
这很有趣,也值得了解,但通常是无关紧要的,因为您很少有理由不使用make函数。除非你有令人信服的理由这样做,否则你应该使用make函数。
请记住:
- 和直接使用
new相比,make函数消除了代码重复,提高了异常安全性。对于std::make_shared和std::allocate_shared,生成的代码更小更快。 - 不适合使用
make函数的情况包括需要指定自定义删除器和希望用花括号初始化。 - 对于
std::shared_ptrs,其他不建议使用make函数的情况包括(1)有自定义内存管理的类;(2)特别关注内存的系统,非常大的对象,以及std::weak_ptrs比对应的std::shared_ptrs活得更久。 - 当你有不得不用new的理由时,(比如上述的几个理由),保证异常安全性需要使用变量提前保存起来只能指针,但是为了更高效,还需要注意一点,就是 把左值智能指针用
std::move转为右值再传入函数。
item22:当使用Pimpl惯用法,请在实现文件中定义特殊成员函数
什么是Pimpl?
你可以将类数据成员替换成一个指向包含具体实现的类(或结构体)的指针,并将放在主类(primary class)的数据成员们移动到实现类(implementation class)去,注意是为了减少编译时间。
举个例子,假如有一个类Widget看起来如下:
1 | |
因为类Widget的数据成员包含有类型std::string,std::vector和Gadget,定义有这些类型的头文件在类Widget编译的时候,必须被包含进来,这意味着类Widget的使用者必须要#include <string>,<vector>以及gadget.h。 这些头文件将会增加类Widget使用者的编译时间,并且让这些使用者依赖于这些头文件。
如果一个头文件的内容变了,类Widget使用者也必须要重新编译。 标准库文件<string>和<vector>不是很常变,但是gadget.h可能会经常修订。
在C++98中Pimpl惯用法,可以把Widget的数据成员替换成一个原始指针,指向一个已经被声明过却还未被定义的结构体,如下:
1 | |
因为类Widget不再提到类型std::string,std::vector以及Gadget,Widget的使用者不再需要为了这些类型而引入头文件。 这可以加速编译,并且意味着,如果这些头文件中有所变动,Widget的使用者不会受到影响。
Pimpl惯用法:
- 第一步,是声明一个数据成员,它是个指针,指向一个未完成类型。
- 第二步是动态分配和回收一个对象,该对象包含那些以前在原来的类中的数据成员。 内存分配和回收的代码都写在实现文件里,比如,对于类
Widget而言,写在Widget.cpp里:
1 | |
这些依赖从头文件widget.h(它被所有Widget类的使用者包含,并且对他们可见)移动到了widget.cpp(该文件只被Widget类的实现者包含,并只对他可见)。 我高亮了其中动态分配和回收Impl对象的部分(译者注:markdown高亮不了,实际高亮的是new Impl和delete pImpl;两个语句)。这就是为什么我们需要Widget的析构函数——我们需要Widget被销毁时回收该对象。
当然现在有了智能指针,让我们尝试把代码写的更现代一些:
1 | |
实现文件也可以改成如下:
1 | |
是的,我们这里就不再需要手写widget的析构函数了,shared_ptr因为RAII会在超出作用域自动析构,而智能指针的析构函数会做delete指针这件事情。
以上代码可以编译通过,没有任何错误出现,但此时一个奇怪的事情出现了:
最普通的Widget用法却会导致编译出错:
1 | |
你所看到的错误信息根据编译器不同会有所不同,但是其文本一般会提到一些有关于“把sizeof或delete应用到未完成类型上”的信息。对于未完成类型,使用以上操作是禁止的。
在Pimpl惯用法中使用std::unique_ptr会抛出错误,有点惊悚,因为第一std::unique_ptr宣称它支持未完成类型,第二Pimpl惯用法是std::unique_ptr的最常见的使用情况之一。 你可能会很不解,幸运的是,让这段代码能正常运行很简单。 只需要对上面出现的问题的原因有一个基础的认识就可以了。
在对象w被析构时(例如离开了作用域),问题出现了。在这个时候,它的析构函数被调用。我们在类的定义里使用了std::unique_ptr,所以我们没有声明一个析构函数,因为我们并没有任何代码需要写在里面。根据编译器自动生成的特殊成员函数的规则(见 Item17),编译器会自动为我们生成一个析构函数。 在这个析构函数里,编译器会插入一些代码来调用类Widget的数据成员pImpl的析构函数。 pImpl是一个std::unique_ptr<Widget::Impl>,也就是说,一个使用默认删除器的std::unique_ptr。 默认删除器是一个函数,它使用delete来销毁内置于std::unique_ptr的原始指针。然而,在使用delete之前,通常会使默认删除器使用C++11的特性static_assert来确保原始指针指向的类型不是一个未完成类型。 当编译器为Widget w的析构生成代码时,它会遇到static_assert检查并且失败,这通常是错误信息的来源。 这些错误信息只在对象w销毁的地方出现,因为类Widget的析构函数,正如其他的编译器生成的特殊成员函数一样,是暗含inline属性的。 错误信息自身往往指向对象w被创建的那行,因为这行代码明确地构造了这个对象,导致了后面潜在的析构。
为了解决这个问题,你只需要确保在编译器生成销毁std::unique_ptr<Widget::Impl>的代码之前, Widget::Impl已经是一个完成类型(complete type)。 当编译器“看到”它的定义的时候,该类型就成为完成类型了。 但是 Widget::Impl的定义在widget.cpp里。成功编译的关键,就是在widget.cpp文件内,让编译器在“看到” Widget的析构函数实现之前(也即编译器插入的,用来销毁std::unique_ptr这个数据成员的代码的,那个位置),先定义Widget::Impl。
做出这样的调整很容易。只需要先在widget.h里,只声明类Widget的析构函数,但不要在这里定义它:
1 | |
在widget.cpp文件中,在结构体Widget::Impl被定义之后,再定义析构函数:
1 | |
这样就可以了,并且这样增加的代码也最少,你声明Widget析构函数只是为了在 Widget 的实现文件中(译者注:指widget.cpp)写出它的定义,但是如果你想强调编译器自动生成的析构函数会做和你一样正确的事情,你可以直接使用“= default”定义析构函数体
1 | |
使用了Pimpl惯用法的类自然适合支持移动操作,因为编译器自动生成的移动操作正合我们所意:对其中的std::unique_ptr进行移动。 正如Item17所解释的那样,声明一个类Widget的析构函数会阻止编译器生成移动操作,所以如果你想要支持移动操作,你必须自己声明相关的函数。考虑到编译器自动生成的版本会正常运行,你可能会很想按如下方式实现它们:
1 | |
这样的做法会导致同样的错误,和之前的声明一个不带析构函数的类的错误一样,并且是因为同样的原因。
编译器生成的移动赋值操作符,在重新赋值之前,需要先销毁指针
pImpl指向的对象。然而在Widget的头文件里,pImpl指针指向的是一个未完成类型。(这里可能部分读者会疑惑,为什么要销毁指针,首先读者要明确,比如A = std::move(B), 销毁的是A的pImpl指针指向的对象,很多读者会误认为是B的。 如果不是因为这个导致你读不懂这一条,那么你可能需要重写了解下移动赋值/移动构造,可以看这个:移动语义是怎么节省开销的)移动构造函数的情况有所不同。 移动构造函数的问题是编译器自动生成的代码里,包含有抛出异常的事件,在这个事件里会生成销毁
pImpl的代码。然而,销毁pImpl需要Impl是一个完成类型。
因为这个问题同上面一致,所以解决方案也一样——把移动操作的定义移动到实现文件里:
1 | |
原来的类Widget包含有std::string,std::vector和Gadget数据成员,并且,假设类型Gadget,如同std::string和std::vector一样,允许复制操作,所以类Widget支持复制操作也很合理。 我们必须要自己来写这些函数,因为
第一,对包含有只可移动(move-only)类型,如
std::unique_ptr的类,编译器不会生成复制操作;第二,即使编译器帮我们生成了(当然编译器不会生成=_=),生成的复制操作也只会复制
std::unique_ptr(也即浅拷贝(shallow copy)),而实际上我们需要复制指针所指向的对象(也即深拷贝(deep copy))。
使用我们已经熟悉的方法,我们在头文件里声明函数,而在实现文件里去实现他们:
1 | |
两个函数的实现都比较中规中矩。 在每个情况中,我们都只从源对象(rhs)中,复制了结构体Impl的内容到目标对象中(*this)。我们利用了编译器会为我们自动生成结构体Impl的复制操作函数的机制,而不是逐一复制结构体Impl的成员,自动生成的复制操作能自动复制每一个成员。 因此我们通过调用编译器生成的Widget::Impl的复制操作函数来实现了类Widget的复制操作。 在复制构造函数中,注意,我们仍然遵从了Item21的建议,使用std::make_unique而非直接使用new。
为了实现Pimpl惯用法,std::unique_ptr是我们使用的智能指针,因为位于对象内部的pImpl指针(例如,在类Widget内部),对所指向的对应实现的对象的享有独占所有权。然而,有趣的是,如果我们使用std::shared_ptr而不是std::unique_ptr来做pImpl指针, 我们会发现本条款的建议不再适用。 我们不需要在类Widget里声明析构函数,没有了用户定义析构函数,编译器将会愉快地生成移动操作,并且将会如我们所期望般工作。widget.h里的代码如下,
1 | |
这是#include了widget.h的客户代码,
1 | |
这些都能编译,并且工作地如我们所望:w1将会被默认构造,它的值会被移动进w2,随后值将会被移动回w1,然后两者都会被销毁(因此导致指向的Widget::Impl对象一并也被销毁)。
std::unique_ptr和std::shared_ptr在pImpl指针上的表现上的区别的深层原因在于,他们支持自定义删除器的方式不同。 对std::unique_ptr而言,删除器的类型是这个智能指针的一部分,这让编译器有可能生成更小的运行时数据结构和更快的运行代码。 这种更高效率的后果之一就是std::unique_ptr指向的类型,在编译器的生成特殊成员函数(如析构函数,移动操作)被调用时,必须已经是一个完成类型。
所以 我们发现shared_ptr不对完成类型做要求,但是不是场景不是很适合使用。unique_ptr很适合,但是你需要注意一些坑,实现的规范小心一些。
请记住:
- Pimpl惯用法通过减少在类实现和类使用者之间的编译依赖来减少编译时间。
- 对于
std::unique_ptr类型的pImpl指针,需要在头文件的类里声明特殊的成员函数,但是在实现文件里面来实现他们。即使是编译器自动生成的代码可以工作,也要这么做。 - 以上的建议只适用于
std::unique_ptr,不适用于std::shared_ptr。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!