反走样技术(1)——SSAA,MSAA,TAA
SSAA(SuperSampling AntiAliasing)超采样反走样
SSAA首先是模糊,然后把一个像素分成多份(比如$2*2$四份),会对每一个pixel的subpixel都进行shading(着色计算)。 最后这个pixel的颜色等于四个subpixel的颜色的加权和。
MSAA(MultiSampling Anti-Aliasing)多重采样反走样
很全面的MSAA解释 https://zhuanlan.zhihu.com/p/135444145
4xMSAA也是按照4x分辨率大小来进行渲染计算,只不过它只运行1x的PS,并有一个Coverage mask来记录子Sample是否被三角形覆盖。在4x分辨率下进行深度与模板测试,然后将PS的输出颜色复制到Coverage mask为1的采样点的颜色缓冲之中。最后得到了4x分辨率的颜色缓冲,附加一个对高层透明的pass,通过插值获取到1x的最终输出帧缓冲,这也是我们只用做一次ps的原因。具体如下:
- 覆盖测试Coverage Test:光栅化阶段,对四个X位置的Sample执行三角形Coverage Test,在一个四倍分辨率大小的Coverage Mask中记录每个Sample被覆盖的情况(需要N倍的内存)。
- 像素着色阶段,在像素中心圆点处执行像素着色器。该点的位置、深度、法线、纹理坐标等信息由三角形三个顶点重心插值得到。图中计算得到像素颜色为紫色。
- 遮挡测试:对四个Sample点执行模板测试与深度测试,并将经过测试通过的Sample数据写入四倍分辨率的模板缓冲与深度缓冲。每个Sample都拥有自己的深度值,依然是重心插值得到。
- 上图中左下两个Sample通过了深度测试,并且Coverage Mask为1,因此将紫色复制到这两个Sample对应的颜色缓冲中(依然是每个Sample一个颜色,共四倍大小)。其他两个Sample暂为背景色。
- 重复上述流程绘制第二个黄色三角形,将跑一次像素着色器获得的黄色复制到右上角的Sample中。
- 所有绘制结束之后,通过一个对上层不可见的PASS,将四个Sample的颜色resolve获得最终输出的像素颜色。

不论什么Deferred还是Forwarding,MSAA都会使得Z-buffer和颜色缓冲区 增大。
- Z-buffer:三角形的深度在每一个覆盖的子采样点的位置进行插值,并且跟z-buffer中的深度信息进行比较。由于深度测试是在每个子采样点的级别而不是像素级别进行的,深度buffer必须相应的增大以来存储额外的深度值。在实现中,这意味着深度缓冲区是非MSAA情况下的n倍。
- 颜色缓冲区:需要额外的空间来存储每个子采样点的颜色值。所以,颜色缓冲区的大小也为非MSAA下的n倍。
MSAA到底能不能在延迟管线上使用?
延迟渲染在计算光照时已经无法获取像素的几何信息,因此很难使用MSAA:
- 在前向渲染可以插值出子sample处的法线/颜色信息,而Deferred管线中无法插值出对应信息,因为deferred管线丢失了连续性,即因为可能存在覆盖,我们并不知道某处上面有几个mesh叠在一起,为了拿到准确的信息,只能Gbuffer扩大。
MSAA对显存和显存带宽的消耗过大,在性能上无法实现:
前面提到:”在前向渲染可以插值出子sample处的法线/颜色信息,而Deferred管线中无法插值出对应信息,因为deferred管线丢失了连续性,即因为可能存在覆盖,我们并不知道某处上面有几个mesh叠在一起,为了拿到准确的信息,只能Gbuffer扩大。”。 可是GBuffer扩大后显存占用将变得很大,这往往也不能接受
假设1个RT是$x$ MB,用上4x MSAA你的内存消耗就是$4x$MB。GBuffer我们按depth,normal,basecolor给3张RT好了,我们前面可知4x msaa的内存消耗是4x的关系,假设我们按照2k的原生分辨率来做,一个RT就是64 MB,用来做MSAA的那个RT就会是不低于256MB。那三个MSAA RT就是768MB, 这东西有点离谱了,太不适合DeferRendering了。
最后我们总结下:
MSAA本质上是一种发生在光栅化阶段的技术,也就是几何阶段后,着色阶段前,用这个技术需要用到场景中的几何信息
延迟渲染因为需要节省光照计算的原因,事先把所有信息都放在了GBuffer上,着色计算的时候已经丢失了几何信息
解决方法,扩大四倍GBuffer,但是太耗了,没人会这么干
https://zhuanlan.zhihu.com/p/507230189 这个paper提出了:不是所有地方都需要四倍信息,只在边缘地方才需要,所以我们对边缘地方做一个的GBuffer生成一个对应的链表,记录着边缘的几何信息,这个在Z-Prepass中可以完成。

不过话说回来,各种post-process AA,在几乎不损失性能的情况下也能达到非常接近4x MSAA的效果,FXAA挺香的,TAA也很好用,没必要在延迟渲染中纠结MSAA。
TAA
历史逐帧Blend
静态场景中我们可以使用Halton序列来实现抖动(jitter), 从而在一个像素内进行多次偏移进行多次采样,他的原理与SSAA相似,都采用一个像素中多次采样,不同的是TAA中是逐帧进行采样,根据历史像素进行Blend。
Halton序列如下图

实现Jitter可以对透视投影做一些操作,如下红色框的两项分别代表偏移大小,即一个齐次坐标左乘这个矩阵后再做透视除法即可发现这两项正好是偏移大小:

重投影:解决相机移动
上述我们没有考虑镜头会移动,我们需要考虑镜头移动带来的变化:
即历史帧混合时首先要找到上一帧的位置,假设场景所有内容静止,对于当前帧一像素点$pixel{current}$,我们只需记录上一帧投影矩阵$M{LastFrame}$即可,我们把当前$pixel{current}$通过$M{CurrentFrame}$的逆矩阵计算出世界空间的坐标,再计算这一点在上一帧的相机下应该位于何处,计算方法是把世界坐标左乘$M_{LastFrame}$矩阵即可。这样我们就获得了上一帧应该在哪儿里。

Motion Vector: 解决动态物体
在渲染物体时,我们需要用到上一帧的投影矩阵和上一帧该物体的位置信息,这样可以得到当前帧和上一帧的位置差,并写入到 Motion Vector。对于带蒙皮动画的物体,我们同时需要上一帧的骨骼的位置,来计算处上一帧中投影到的位置。计算上一帧位置和当前帧位置的方法是一样的,都是从 VS 中输出裁剪空间的齐次坐标,在 PS 中读取,然后就可以做差求得 Motion 值。为了使 Motion 的值比较精确,我们在计算 Motion 时,不会添加抖动(在计算前先减去jitter)。
因为 Motion Vector 的精度要求比较高,因此用RG16格式来存储。Motion Vector 可以作为延迟渲染的 GBuffer 的一部分,除了用了实现 TAA,还可以实现移动模糊/Motion Blur 等效果。
同时我们在去上一帧的帧缓冲里寻找时需要判断上一帧位置所在处是否是我们当前所需要的物体id,深度信息是否匹配,防止是上一帧该点还被遮挡,从而拿到了错误的信息。
解决鬼影和闪烁
TAA中,还需要注意鬼影和闪烁:
鬼影具体分析有以下原因:
上一帧对应的点被前一个物体遮挡了,但是仍然用了前一个物体的点。
- 可以用我们上述提到的解决方法,是不是同一个物体id或者深度判断,比如鸣潮中就使用了1bit来记录CharacterMask以保障角色的高质量。
在进行深度筛选的时候,条件过于宽松,引入了错误的点。
- 调整合适的系数
- 使用其他更准确的方法记录,同第一条解决方法
光照条件发生了变化,导致同一点前后帧颜色差异很大
- 颜色Clip / Clamp
解决方法一般是:
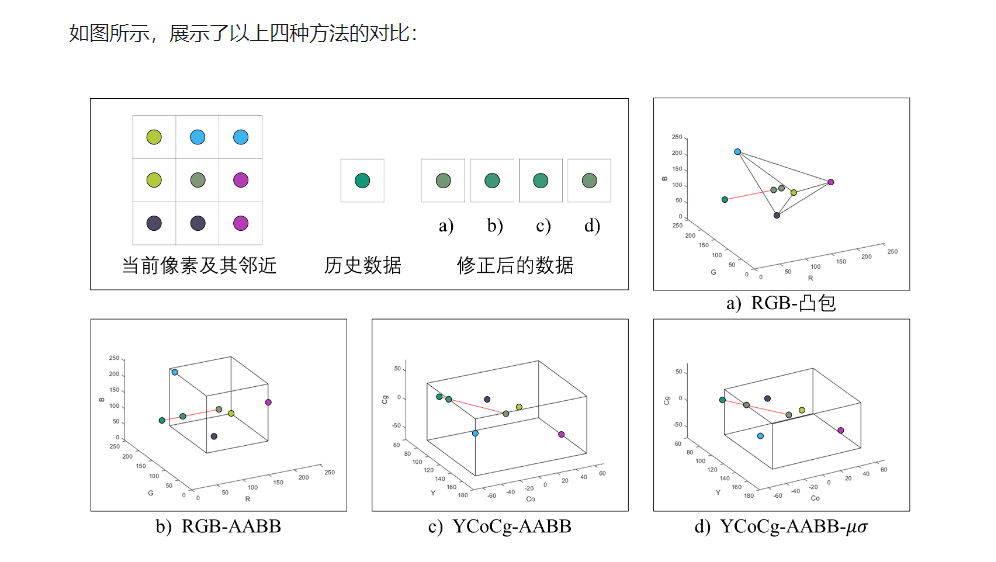
- 一种比较复杂的方法是:用当前数据颜色值及其周围八个点的颜色值,在 RGB 颜色空间计算一个凸包,如果历史数据颜色值在凸包里面,则直接使用,如果在凸包外面,则连接两个颜色值得到一根线,并求这根线与凸包的交点,使用交点处的颜色值进行混合。可预想的是,计算凸包以及连线与凸包的交点这两个操作十分复杂。
- 另一种近似的方法是:将计算凸包转化为计算 AABB,并且计算连线与 AABB 的交点。
改进1中进一步改进:不在 RGB 空间计算,而是在 YCoCg 亮度颜色空间操作,但是有可能点的颜色分布很散,导致 AABB 范围很大,不能很好的修正历史颜色。
改进2中进一步改进, 如上面所说:如果周围颜色分布很广,则AABB范围大,不能很好修正历史颜色,NV提出了Variance Clipping (VC) : 不直接使用近邻点颜色的最大值和最小值来确定 AABB,而是用均值和标准差,统计学意义上进行分析:

另外有两种做法去修正颜色,上面提到的是clip,还有简单的clamp,即Clamp(color, AABBmin,AABBmax)一半来说clip效果更好一些。

TAA中的ToneMapping
如果使用 HDR 颜色作为输入,得到的抗锯齿效果不佳。所以需要把 TAA 放到 Tonemapping 之后。但是这样又会影响后续需要 HDR 的 Bloom 等特效的计算。
需要注意的时TAA做的时候需要进行两次Tonemapping,分别是tonemapping和InvertTonemapping:而在色调映射时,常用的操作是进行 Reinhard 操作$ 1/(1+x)$,因为开销便宜。

实践:鸣潮TAA优化


鸣潮TAA的方案做了几个改进和技术选型:
采样时只采样十字星,周围八个像素都采太耗
做Bound Box没有用上面提到的Variance Clipping,而是AABB
Color space选择在低配机器RGB,高配机器YCocg来做。因为多了一次颜色空间转换。
对于motion vector的Gbuffer(VelocityBuffer)除了记录基本的速度,还会用一个bit记录是不是角色,这样就可以更精确的判断上一帧某个像素点是不是角色,减少鬼影。
由于对于卡渲一个角色需要好多个Pass渲染,单纯的对basepass的本体做一次VelocityBuffer pass是不够的,还需要对勾边也作一次velocitybuffer pass,然而鸣潮为了减少一个勾边velocitybuffer pass,就没有做这个操作。
由于不对勾边做velocitybuffer pass,导致再寻找上一帧历史时勾边不认做是角色的一部分,导致产生闪烁(Flicker)。因此采用一个低通滤波减少闪烁
TAA存在的问题是:历史帧权重高会导致有模糊或者鬼影,历史帧权重低自然就是画面闪烁,我们往往需要调解历史权重来trade-off。其实我们希望的是,动态物体像素要清晰,不要糊有鬼影,静态的不要闪烁。这样对于动静就可以区别对待使其拥有不同的历史权重。可以根据Velocity的大小从静态权重到动态权重进行插值。

考虑动态物体容易糊,还加入了锐化算法,使用unsharp masking kernel,因为他和十字星采样点是匹配的,可以复用。
Reference
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!