vector容器内存释放技巧:swap() vector容器内存释放技巧:swap() .clear()方法并不会释放内存,他只会清空内容,但是容器内存依然占据着,因此我们需要用一种swap trick来解决这个问题: 下面是一个利用swap trick来修整空间的例子: 12345vector<int>v;v.push_back(1);v.push_back(2);v.push_back(3);vector& 2022-02-11 C++
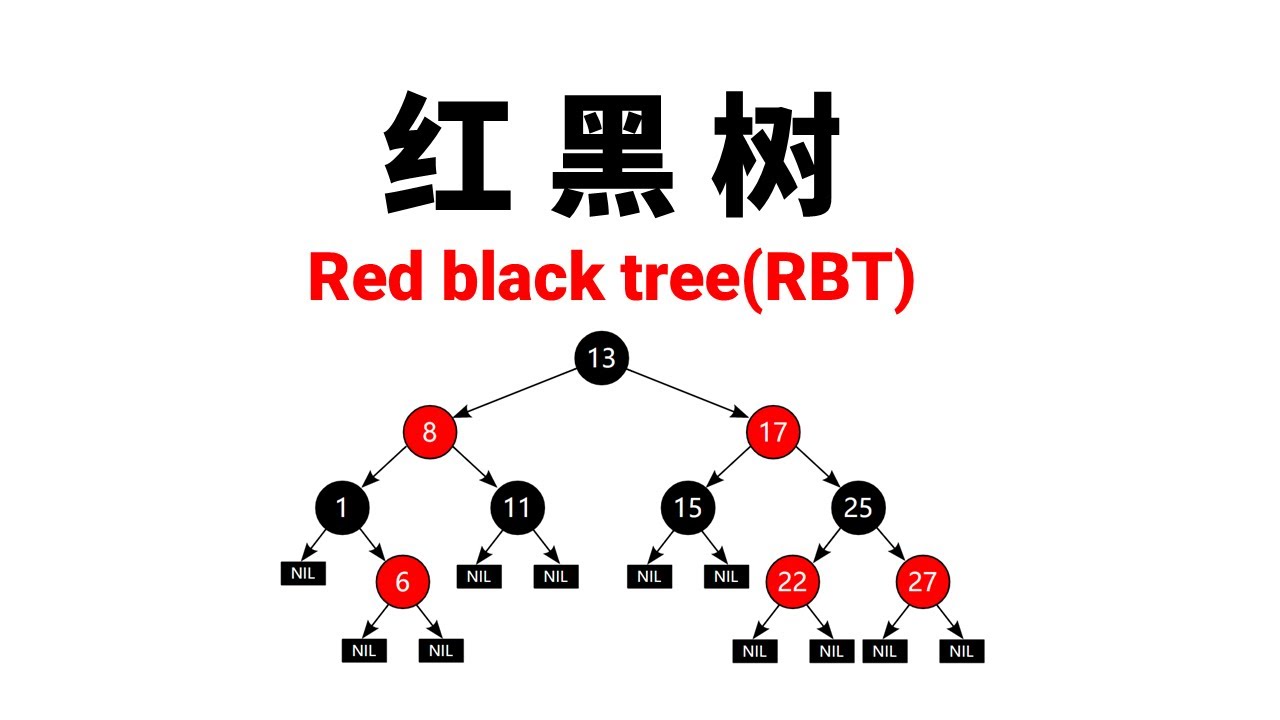
RB-tree红黑树 RB-tree红黑树一些基本性质:1.根节点一定是黑色 2.所有叶子结点(叶子结点都是空节点)都是黑色 3.红色结点的两个子结点一定是黑色 4.从任一个节点,到它每个叶子结点的路径都包含相同数目的黑色节点。 红黑树插入:分三大类情况 1.被插入的节点是根节点,直接把此节点涂黑 2.被插入的节点的父节点是黑色,直接插进去并且把节点变成红色(这是因为变成红色就不会影响上述的 基本性质4) 3.被插 2022-02-09 数据结构
const关键字修饰 相关问题 const关键字修饰 相关问题const修饰问题很麻烦,一个不错的识别方式是:const默认作用于其左边的东西,否则作用于其右边的东西: 辨别方法 const int* const只有右边有东西,所以const修饰int成为常量整型,然后*再作用于常量整型。所以这是a pointer to a constant integer(指向一个整型,不可通过该指针改变其指向的内容,但可改变指针本身所指 2022-01-24 C++
Leetcode第 277 场周赛题解 5989. 元素计数不等于最大或最小元素 统计一下有多少个即可: 12345678910111213class Solution {public: int countElements(vector<int>& a) { sort(a.begin(),a.end()); int n = a.size(); int 2022-01-24 Leetcode
leetcode第 70 场双周赛题解 5971. 打折购买糖果的最小开销从大到小排序,三个三个买(2个花钱,1个赠送),剩余的不够三个就直接花钱买下剩余全部的。 123456789101112131415161718192021class Solution {public: int minimumCost(vector<int>& cost) { sort(cost.begi 2022-01-23 Leetcode
Codeforces Global Round 18(A-E) A - Closing The Gap签到:加起来模n即可。 1234567891011121314151617181920212223242526272829303132333435363738#include<bits/stdc++.h>using namespace std;#define pii pair<int,int>#define pll pair<ll 2022-01-23 ACM-Codeforces
C++面向对象高级编程-下 C++面向对象高级编程(下)Conversion function转换函数 12Fraction f(3,5);double d = 4 + f; 对于double d = 4 + f;这一条语句编译器的动作是: 1.对于上面的操作4+f有没有一个operator+可以使得 double + fraction的函数(不存在,那么下一种方法) 2.是否存在可以让4转换为double的函数(默认存在 2021-12-20 C++
C++面向对象高级编程-上 C++面向对象高级编程header头文件防卫式声明 这是一种防卫式声明,防卫式声明的作用是:防止由于同一个头文件被包含多次,而导致了重复定义。防卫式声明表示,如果__COMPLEX__没有被定义过,那么就展开定义,否则跳过。 __COMPLEX__被称为预处理器变量一般有两种状态:已定义或未定义。 #ifndef 指示检测指定的预处理器变量是否未定义,如果未定义,那么跟在后面的所有指示被处理,直 2021-12-11 C++
(A-G)NEC Programming Contest 2021(AtCoder Beginner Contest 229) (A-G)NEC Programming Contest 2021(AtCoder BeginnerA - First Grid当且仅当有两个#需要判断,其他直接输出YES。当有两个#时,判断这两个#是否在对角线即可。 12345678910111213141516171819202122232425262728293031323334353637383940#include<bits/st 2021-12-07 ACM-Atcoder
比赛板子 一切的开始12345678910111213141516171819202122#include<bits/stdc++.h>using namespace std;#define pii pair<int,int>#define pll pair<ll,ll>#define pdd pair<double,double>#define fastIO 2021-11-23 ACM-板子