CS231n-CH2-损失函数/最优化/特征提取
CS231n:Computer Science
损失函数和优化
损失函数(Loss Function)


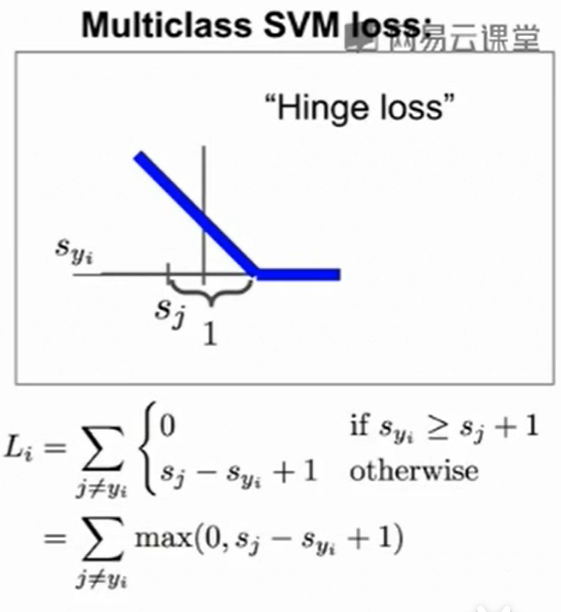
我们这里使用了multiclass SVM loss(hinge loss function),如果属于$y_i$类别的图像在$y_i$类得到的分数比在$j$类中得到的分数多1(这个1可以看作两类差距的一个阈值margin,毕竟如果两类如果差距不大,说明分类还是有些问题的,此时loss也不该为0),那么说明没有损失,也就是$L_i = 0$此时。
反之,属于$y_i$类别的图像在$y_i$类得到的分数比在$j$类中得到的分数低了一些的时候,说明了预测不准确,loss我们直接设置两个类别得到的分数的差值。
如果想知道更多有关hinge loss和SVM的关系,可以查看 :
一个具体计算SVM loss的例子:
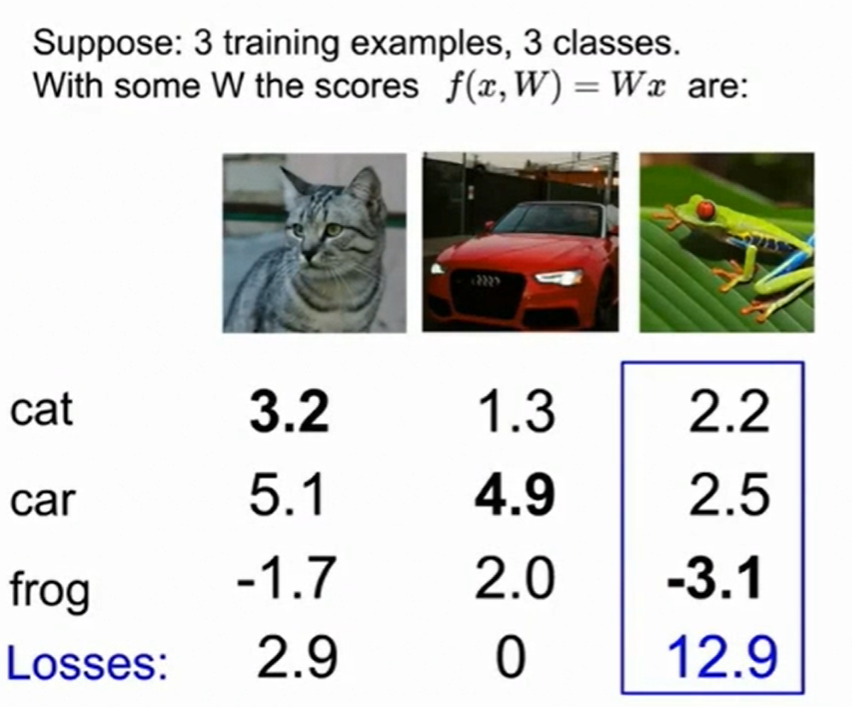
这里的car所得到的4.9分上下稍微浮动并不会影响到loss function的大小,因为在hinge loss中它一直是等于0的。
在我们最小化L(W)时要小心overfitting
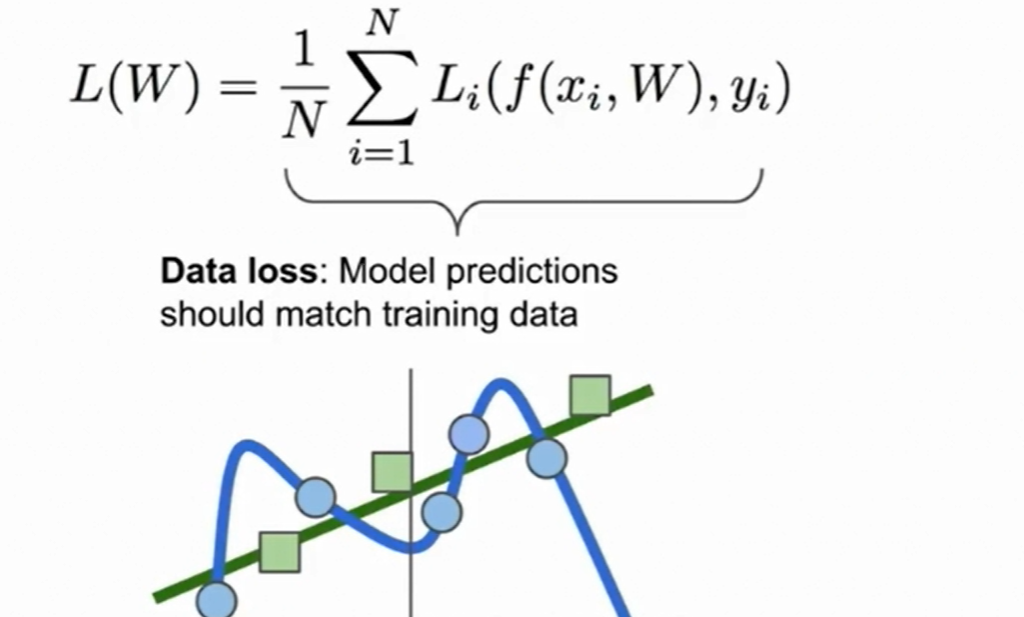
所以加上正则项:
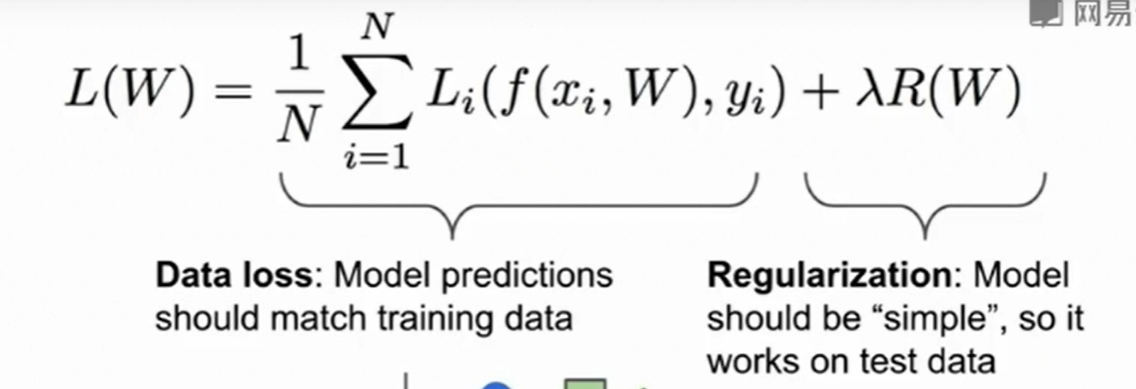
正则化:

L1正则化更喜欢稀疏的解,比如(1,0,0,0)这样的$w$在L1正则化上比比(0.5,0.5,0.5,0.5)小,但是在$L2$正则化上他们是相同的,因此我们可以认为L1更喜欢稀疏的解,他会让一些项趋于0来降低模型复杂度。 反观L2正则化,在(1,0,0,0)这样的w上L2正则化是大于(0.25,0.25,0.25,0.25)的,虽然他们的L1是相同的,这是因为L2正则化更喜欢用一个均匀且整体较小的w来降低模型的复杂度,使得当数据的某一维度发生变化时,这样均匀且较小的权重不会使得结果发生很大的差异,这样降低了模型的复杂度。
还有一种在深度学习中用的classifier,叫做Softmax Classifier(Mutinomial Logistic Regression)。这种方法和上面的SVM不同,SVM只是关心正确分类的分数比其他分类的分数高出一个阈值即可,然而他并不关心这些分数有什么具体的意义,在Softmax 中这些都代表着一种几率。

一个例子:score->exp(score)->normalize(可以看成几率占比)->L=-log(.)

你可能会有疑问,如果-log(.)中是0怎么办?这样损失就是无限小了,而其他即使有损失也会这一项掩盖。还记得我们做了exp()吗,如果而exp()无论里面的值是多少,也不会得到0。
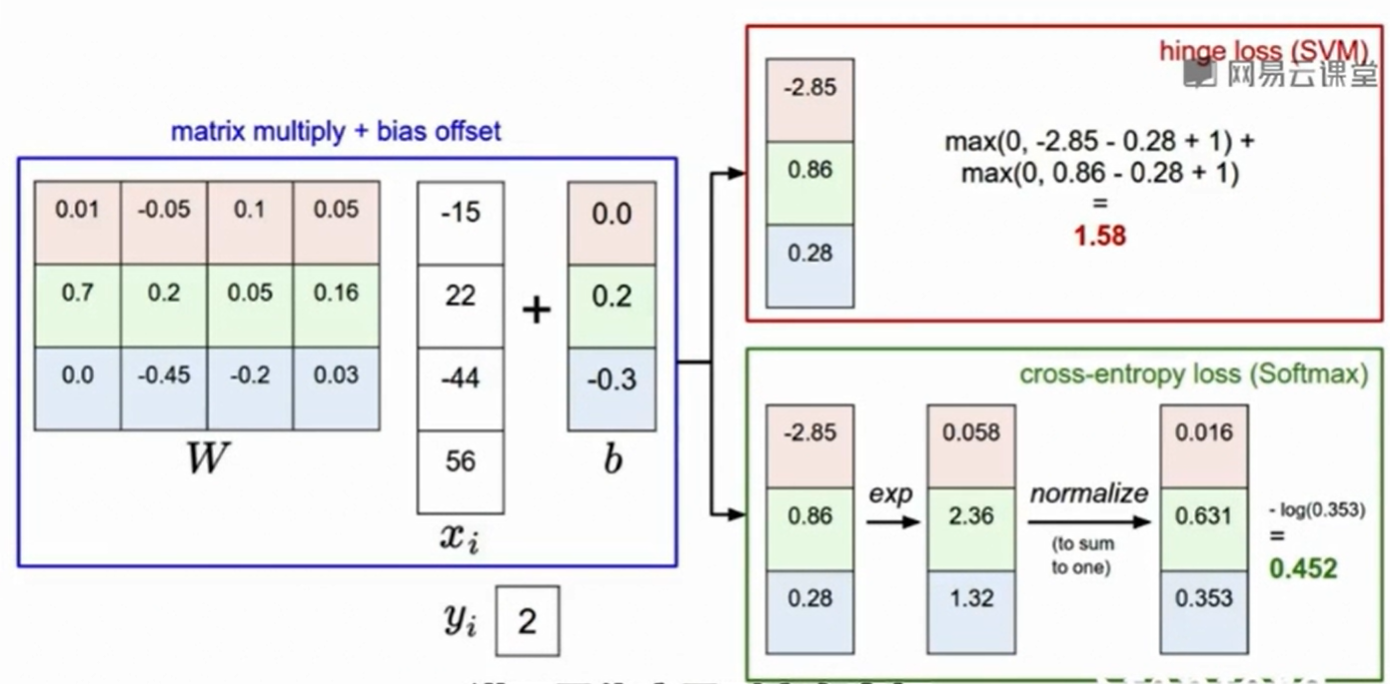
这两者的区别在于:在hinge loss中如果你已经分类正确并且比其他分类的分数高出一个阈值,此时分类正确的分数即使再高一些也不会影响hinge loss的大小,因为他就是0。但是在cross-entropy loss中,他总会使得正确的更加正确,使得正确的几率趋于1。

最优化(Optimization)
普通梯度下降(GD):就是梯度相反方向乘上一个学习率,用这个去更新w,从而做到最优化。
随机梯度下降(SGD):

SGD一大好处就是每次迭代复杂度很低,比如再logistic regression中,梯度的表达式是$1/N *\Sigma_{n=1}^{N} \theta(-y_nw_t^Tx_n)(-y_nx_n)$。需要计算复杂度是$O(N)$,而SGD随机选择一个小的批量,用这个小的批量去更新,那么迭代一次复杂度就是$O(size\ of \ minibatch)$
特征提取(Feature extraction)
我们直接把图像的rgb三个维度扔到向量里去预测一般不会得到很好的效果,我们一般习惯于先寻找与图像的特征或者形象有关的向量,然后用这些代表着图像特征的向量来做预策
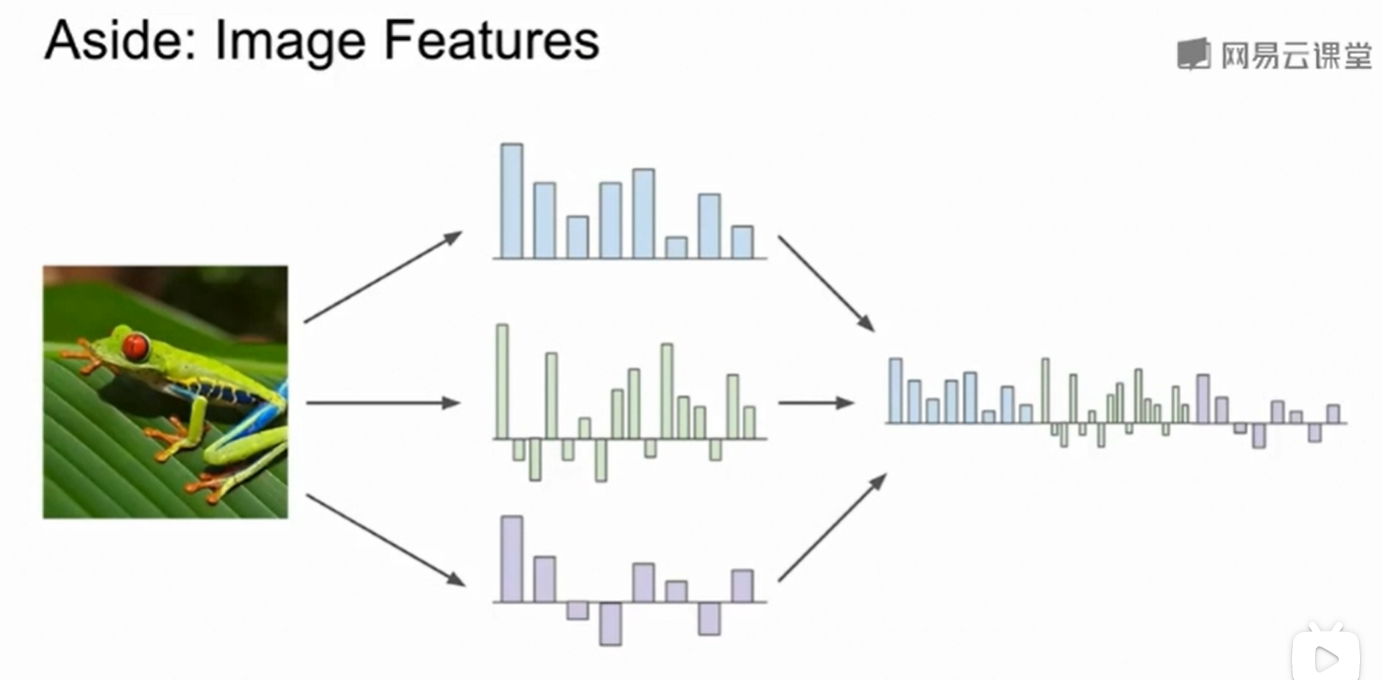
一种很好的表现图像颜色特征的方法是:颜色直方图
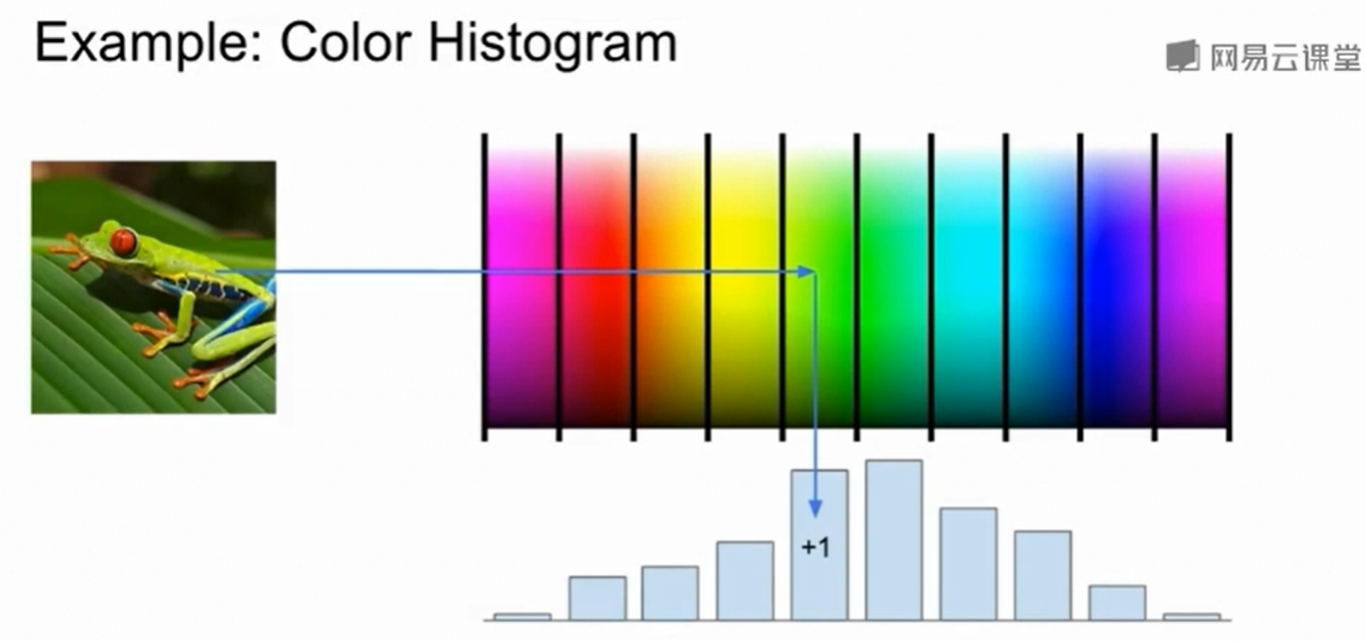
比如这个青蛙,绿色部分就比较高。
还有一种梯度直方图,也可以表现出图片的特征:

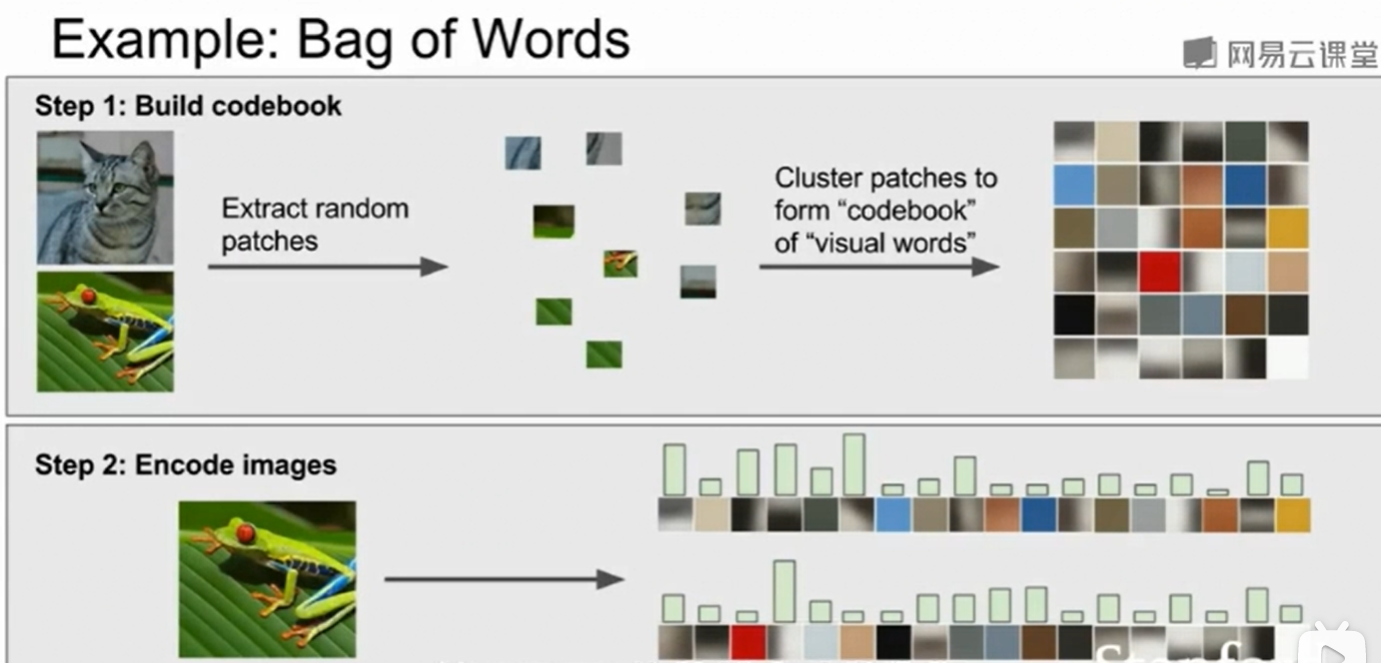
还有一种提取图像特征的方法是:Bag iof words
事实上,这是从NLP中得到的灵感,如果你想对一句话用向量表示,我们可以对这句话中不同的次做一个统计。放在图像中,我们首先需要构建自己的图像字典,做法是首先对图像集随机的抽取小片图像块,然后做聚类得到几种不同类别的图像块,把他们放入图像字典,我们就可以得到图像字典。然后图像就可以用这些图像字典来表示,向量就代表着每种图像块的数量。这是李飞飞在CVPR2005上提到的一种提取图像特征的方法。
现在我们更多采用卷积神经网络来做这件事情。
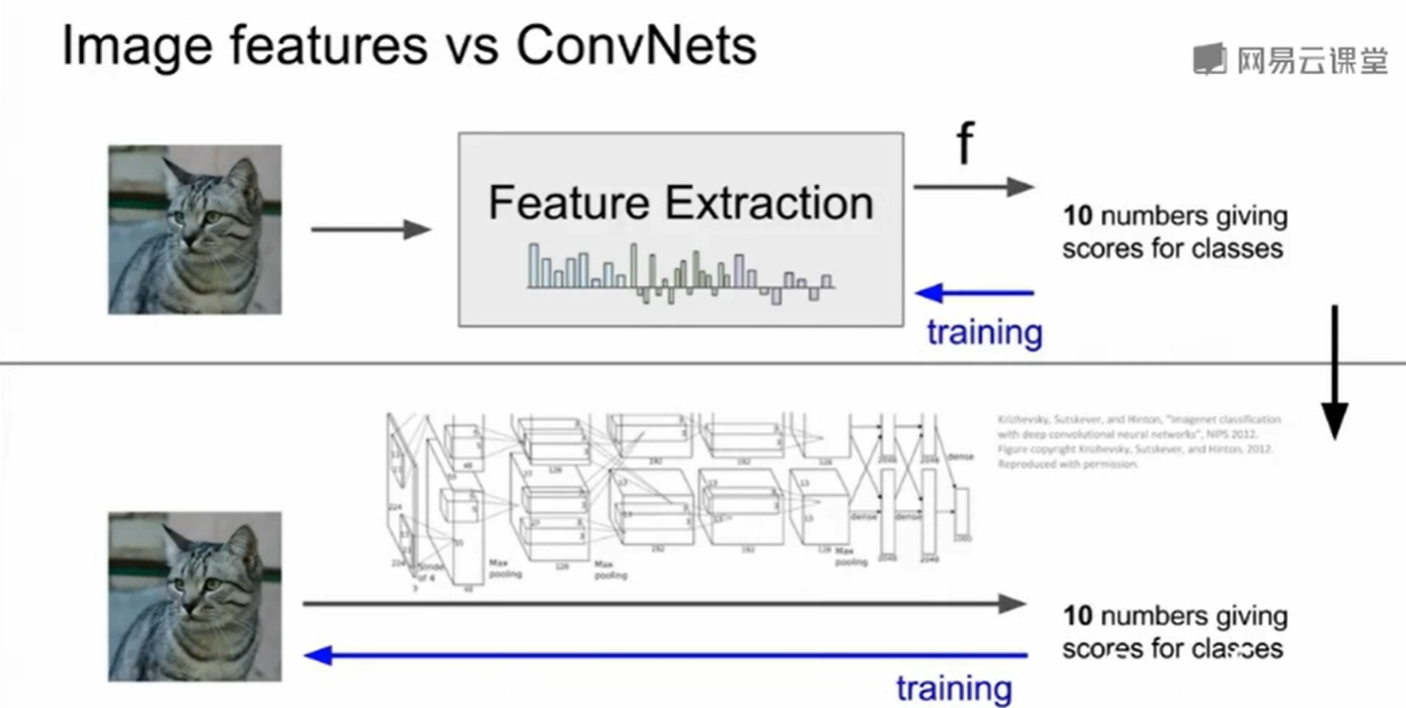
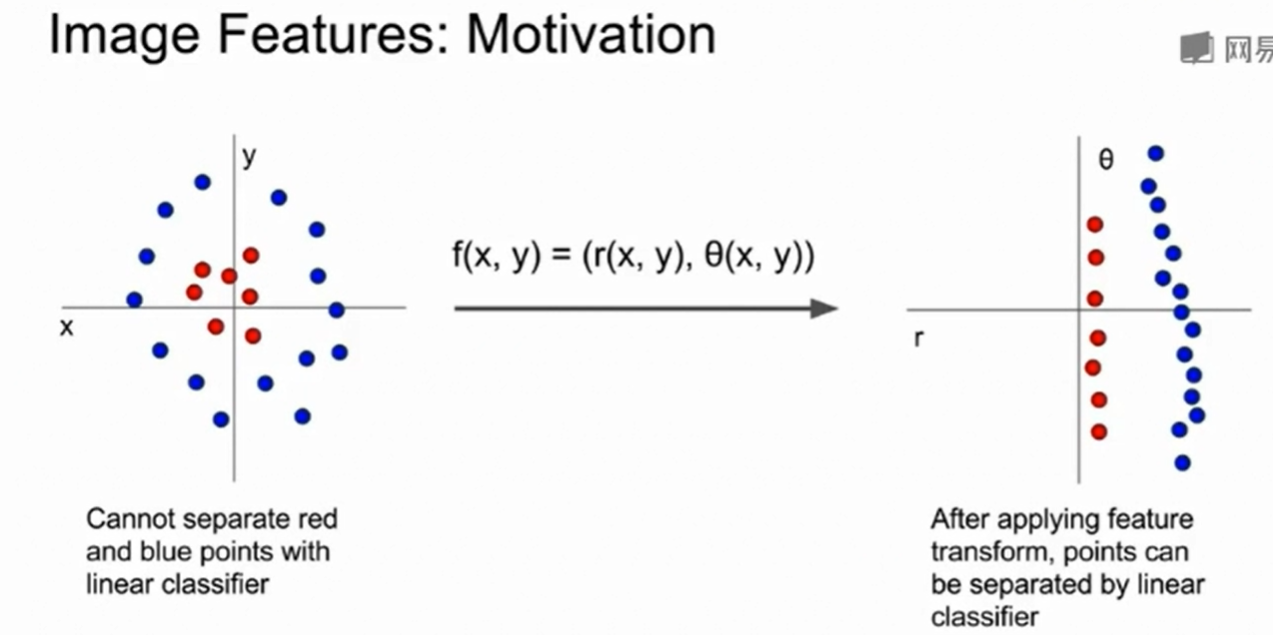
即feature transform
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!