CS231n-CH5-训练神经网络(上)
训练神经网络(上)
激活函数
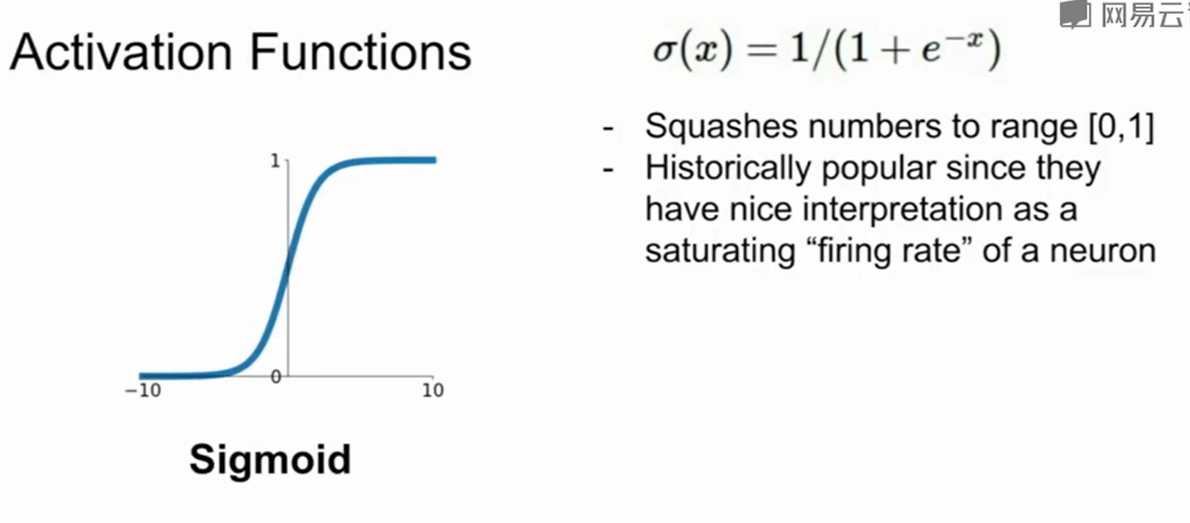
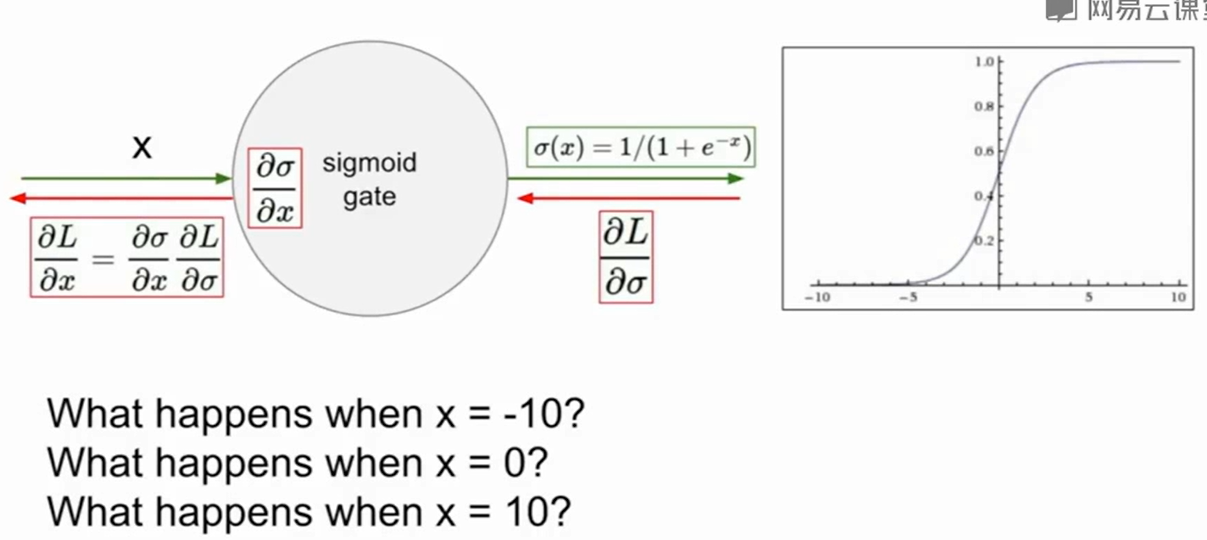
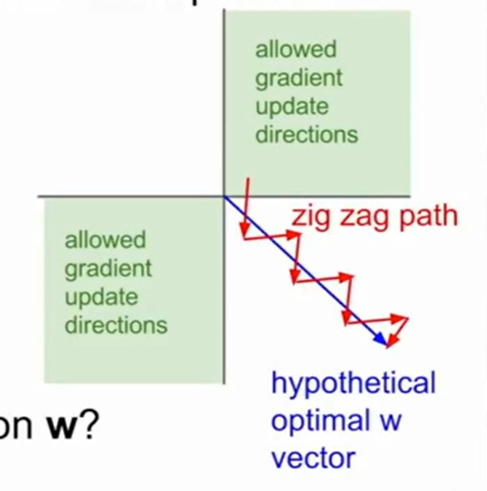
问题:
当x是一个很大/很小的区域时,梯度是一个十分接近0的数值,这会导致upstream如果是0,那么返回值就会十分小。这会使得梯度逐渐消失。
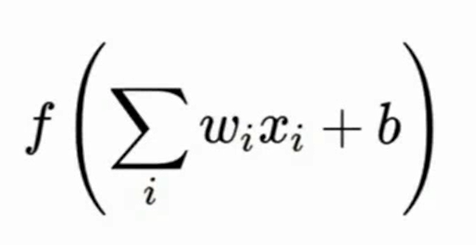
比如这个方程的对$x$的梯度是一堆$w$,我们假设数据的x要么都是大于0/要么都是小于0的,那么$\Sigma w_ix_i+b$这个式子对$w$求梯度是一堆$x$,我们上面假设了这里都是大于0,那么这个梯度也都大于0,同时$f$对$\Sigma w_ix_i+b$求导,由于f在各个点导数倒是正的,所以梯度恒大于0,这就导致了$f$对$w$求导是恒正的。
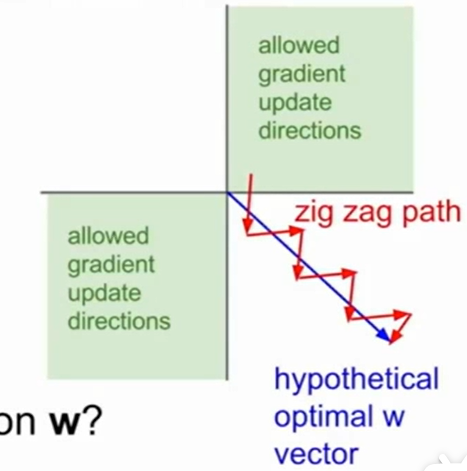
而这样会导致无法想着正确的梯度去走,w增加的永远是正值/负值,这样会导致收敛缓慢。无法向着正确的方向去走,我们仔细想想就会发现数据x中全正/全负是我们无法改变的,真正原因是因为sigmoid函数梯度恒大于0,这样就导致了梯度方向的局限。因此这也是sigmoid的缺点。当然,如果我们的数据是zero-mean的,也就是说有正有负的那种数据,sigmoid是不会影响什么的。总之,两个限制(数据全正全负,sigmoid梯度恒大于0),有一个被解决就可以快速地梯度下降。
exp()计算比较费时。

- $tanh$和$sigmiod$一样在x很大/很小的时候梯度几乎为0,这会导致upstream是0,那么返回值就会十分小。这会使得梯度逐渐消失。

- ReLU梯度不会消失
- 计算高效(不包含exp())
- 收敛快
- 更符合生物上的特点
缺点
缺点是0点处不可导
Dead ReLU Problem(神经元坏死现象):ReLU在负数区域被kill的现象叫做dead relu。ReLU在训练的时很“脆弱”。在x<0时,梯度为0。这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新。
产生这种现象的两个原因:参数初始化问题;learning rate太高导致在训练过程中参数更新太大。
解决方法:采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。

和ReLU比,在负坐标上梯度不是0了。


数据预处理
我们一般会对数据做中心化(零均值化zero-mean),原因就是上面提到的:
对训练的图像求个平均,然后让每张图像都减去这个平均图像。
权重的初始化问题:
深度前馈网络与Xavier初始化原理 - 知乎 https://zhuanlan.zhihu.com/p/27919794
批量归一化(Batch Normalization)

这个式子可以推一推,就是把x的分布变成了均值为0,方差为1的一个分布。

我们通常会那一个batch的数据,然后对每一维度求期望,方差,然后归一化这些数据。

Batch Normalization通常放在全连接层后,卷积层后,非线性层前。

我们可以对Batch Nomalization后的$x$进行缩放,$y = \gamma x+\beta$,其中如果我们的$\gamma=\sqrt{Var[x]},\beta=E[x]$时,就相当于我们没做Batch normaliazation,因此我们的$\gamma,\beta$在学习中也可以恢复到不做normalization的情况,这样加入batch normalization的效果不好时也可以保证恢复回来。
总体来说,Batch Normalization的过程是:

BN的优点:
可以使用更高的学习率

原因大概解释一下就是:首先我们要知道高学习率通常会导致梯度爆炸/梯度消失,这是因为底层的网络对高层的网络会有叠加的影响。而BN由于对层进行归一化,因此这组织了某层输出的值会变得过大或者过小,因此这直接的解绝了梯度爆炸/梯度消失的问题。 因此我们此时就可以用更高的学习率。
同时下面这个数学上的解释也是work的:
深度学习中 Batch Normalization为什么效果好? - Juliuszh的回答 - 知乎 https://www.zhihu.com/question/38102762/answer/302841181

可以防止过拟合,当然作者在原文章中并没拿出什么有力的论证,所以只是含糊的说有了BN就可以不要dropout层了。
对于训练,学习率的一般通过在[1e-5,1e-3]做validation来选择。
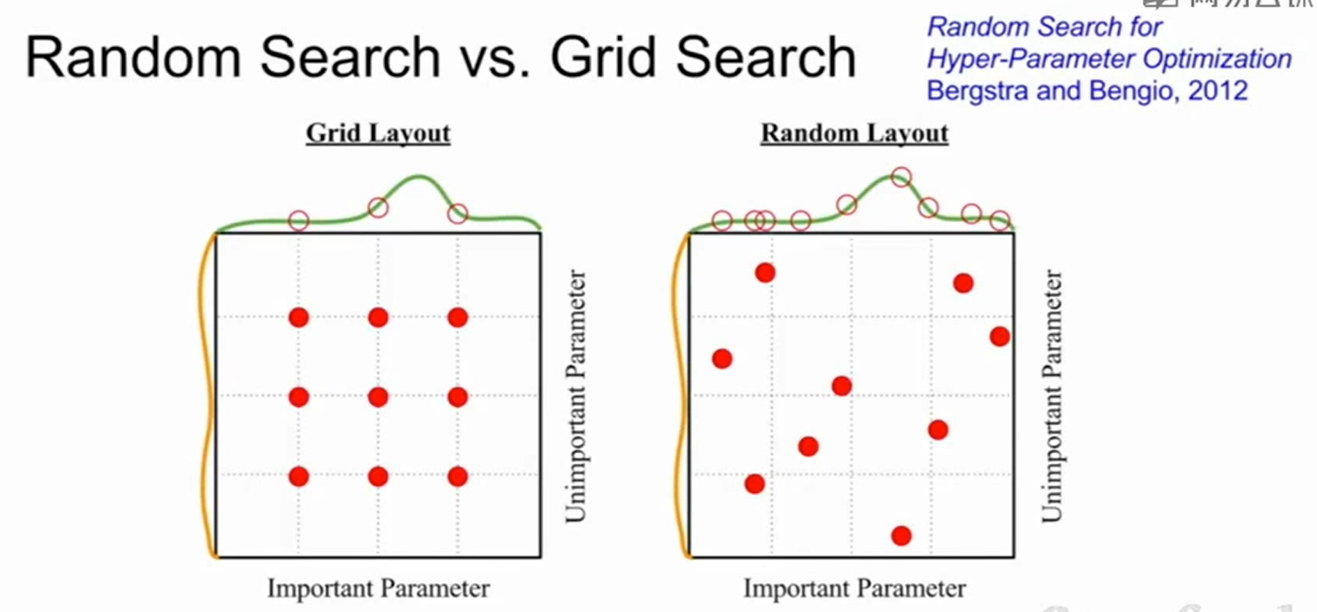
超参数的除了grid search(即一组一组的参数一个一个去做validation,哪儿个好用哪儿个)。也可以random search(给每个超参数设定一个分布,然后去对每个参数从他所属的分布中抽样,用这样的方法获得一组超参数,然后再去validation)。
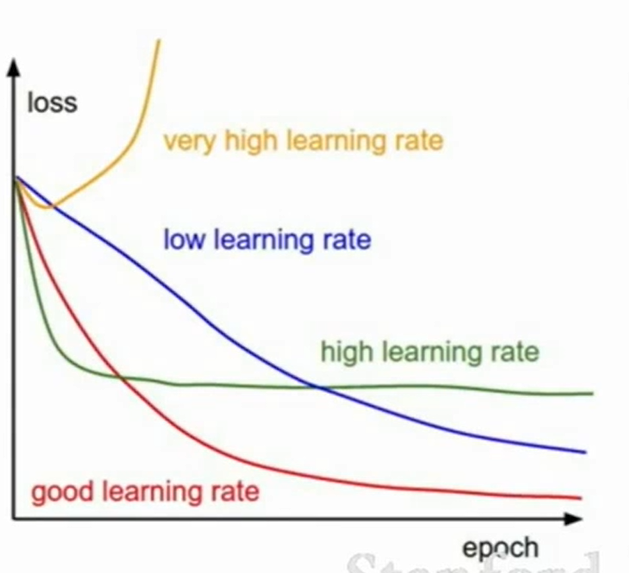
黄色:过高的学习率会导致梯度爆炸
蓝色:低的学习率导致loss下降缓慢
绿色:高的学习率也会导致无法陷入局部最优解
红色:好的学习率,loss下降快。
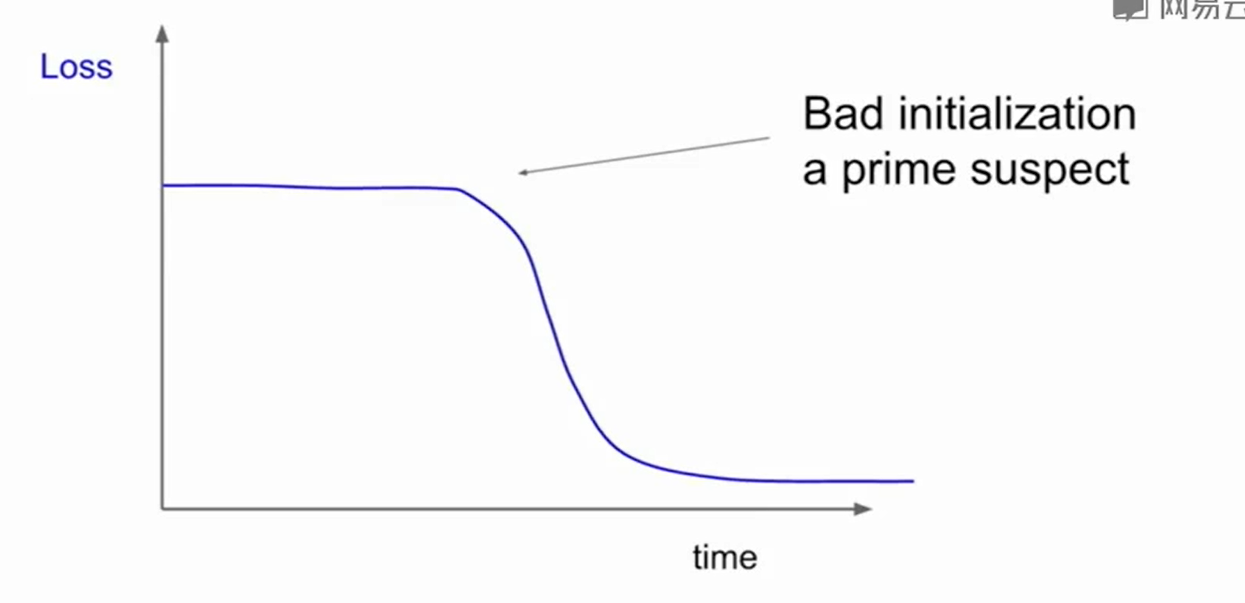
一般这样开始loss不下降,在某一个节点突然下降,说明初始化做的不好。
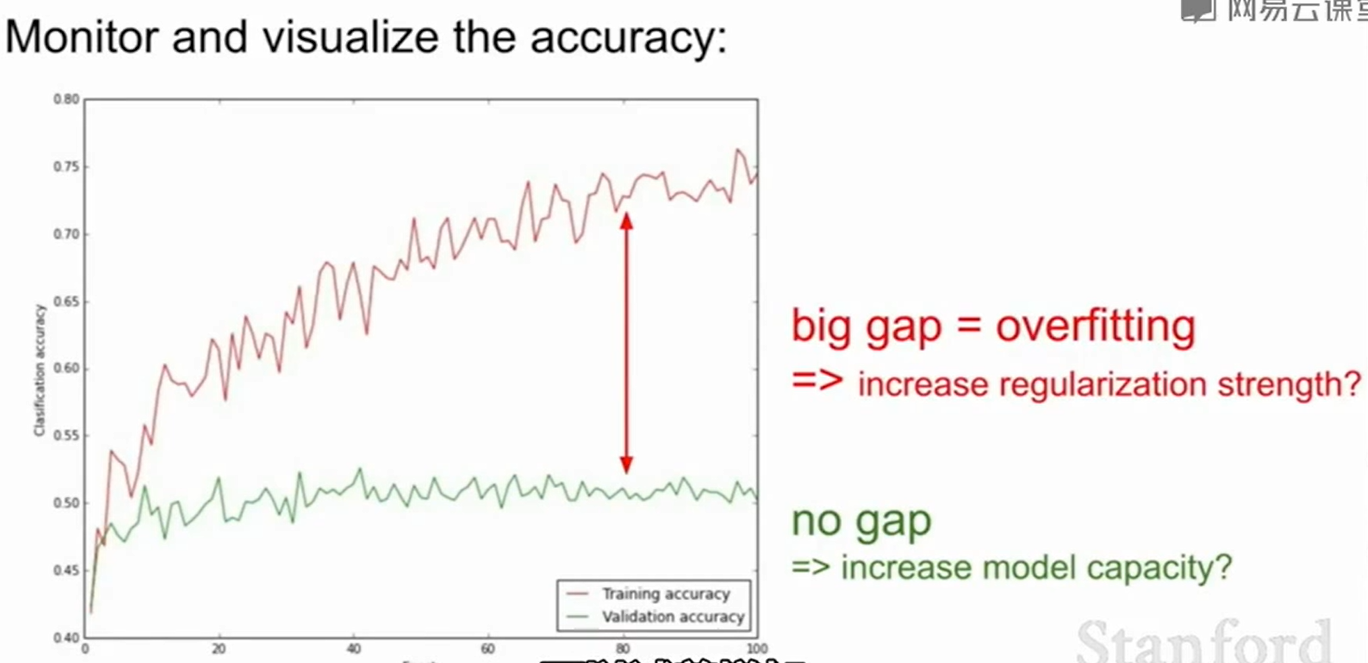
如果validation和train的差别太大,说明是overfitting了,可以试着做一些正则化。如果差别不大且两者准确率都不高,那就应该去找模型的问题了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!