CS231n-CH6-训练神经网络-下
训练神经网络(下)
更好的优化
SGD的缺点:
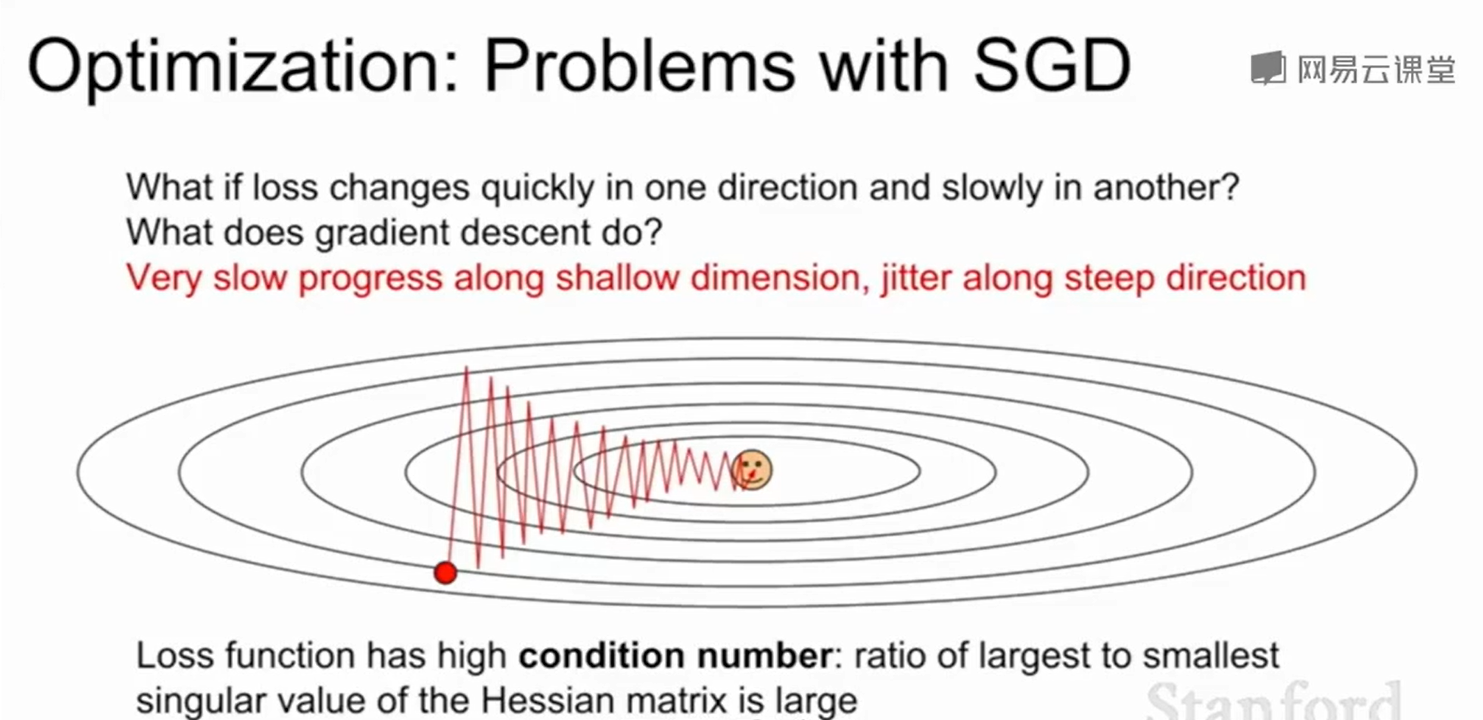
SGD在某些情况下效果并不会很好,比如loss在竖直方向上下降的很快,在另两个维度上loss下降的很慢,这就会导致得到上下剧烈波动的线。在三维空间如此,在高维空间上更容易出现这个问题。最优化过程会变得很慢。
SGD还有一个缺点就是无法处理鞍点:
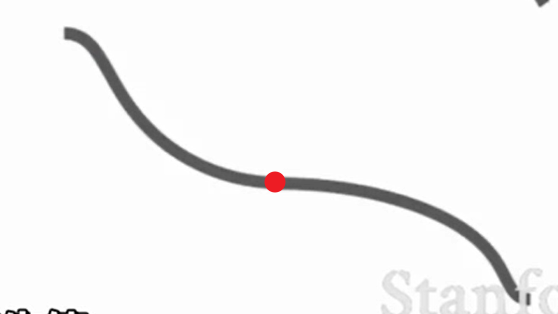
即梯度=0,但是却不是极大值/极小值。
梯度到这个地方时由于梯度变为了0,会导致停止迭代。
在这个一维的情况下,由于一边会导致loss上升,一边会导致loss下降,也就是鞍点时或导致梯度为0无法迭代更新,但这个一般不会遇到,因为几率很小。但如果是在一个大型的网络上,当你的参数有成百上千个,在某个方向上会使loss上升,在另一个方向上会使loss下降,这个其实很常见的情况。此时梯度为0的几率就大了很多。
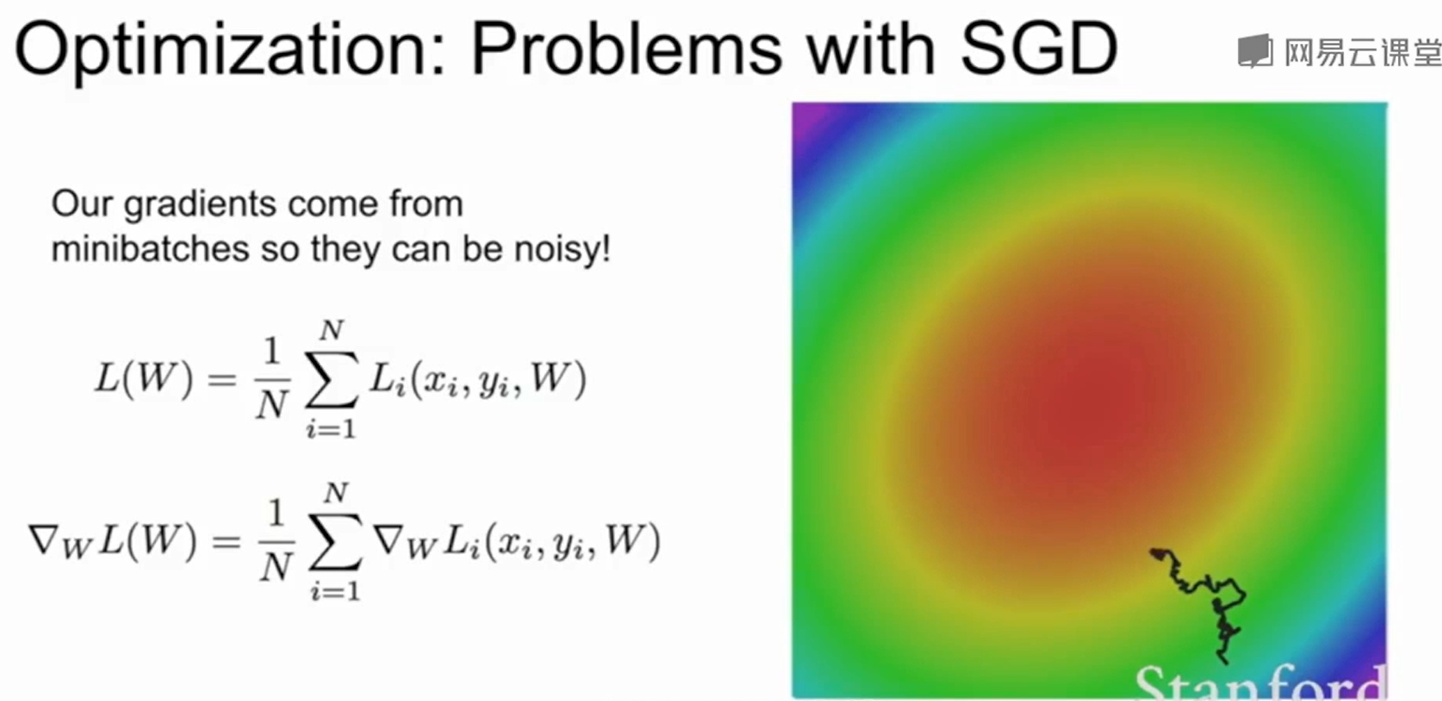
还有一个问题就是由于SGD是选一个mini-batch来作为下降的梯度,但是数据中有噪声的时候,就会导致梯度下降的每一步都不是特别准确,从而导致下降十分缓慢。
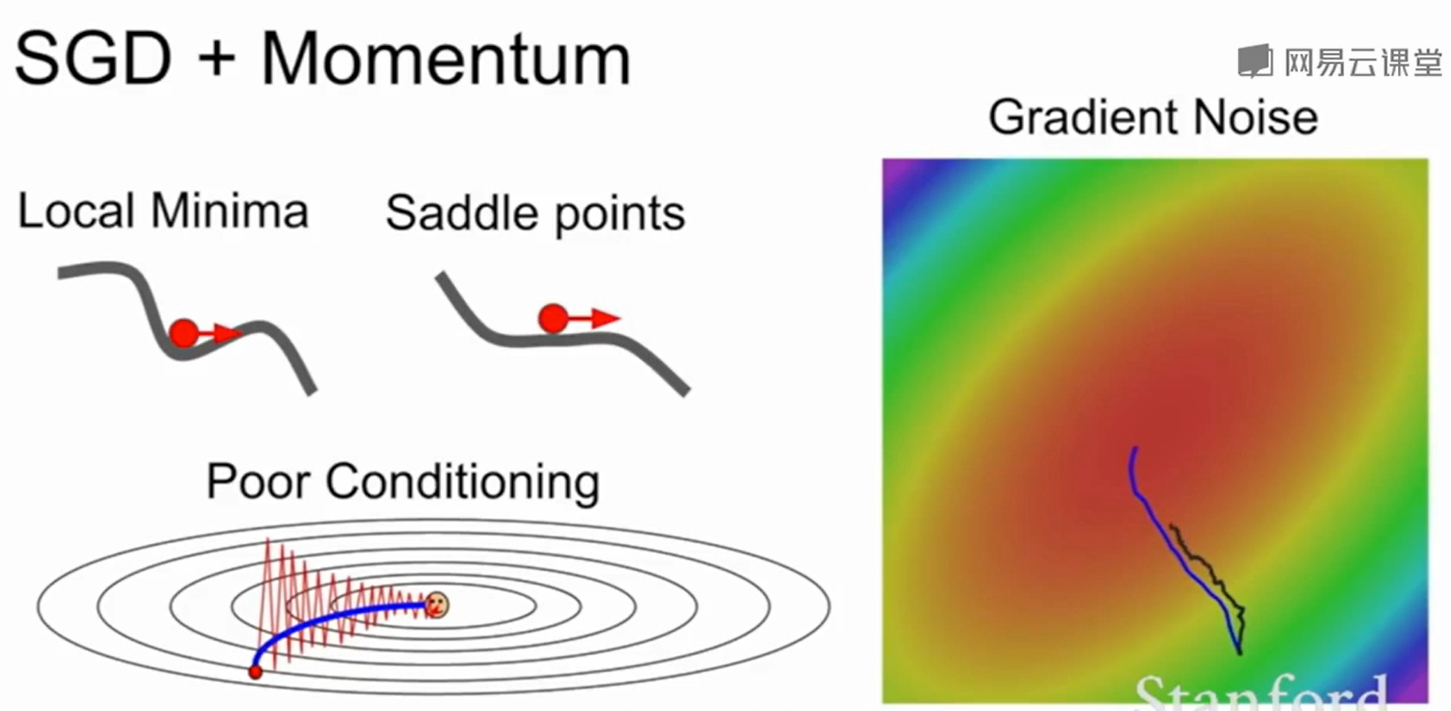
SGD+Momentum(动量梯度下降)

思想就是用速度作为新的梯度。这样在一个很大的下坡(梯度变大)时,速度会累计变大,这样就不会陷入到局部最小值和鞍点,同时如果到了一个比较平的面,即梯度变化不明显时,$\rho$ 作为摩擦系数会使得速度不断减小。最后速度不在变换。
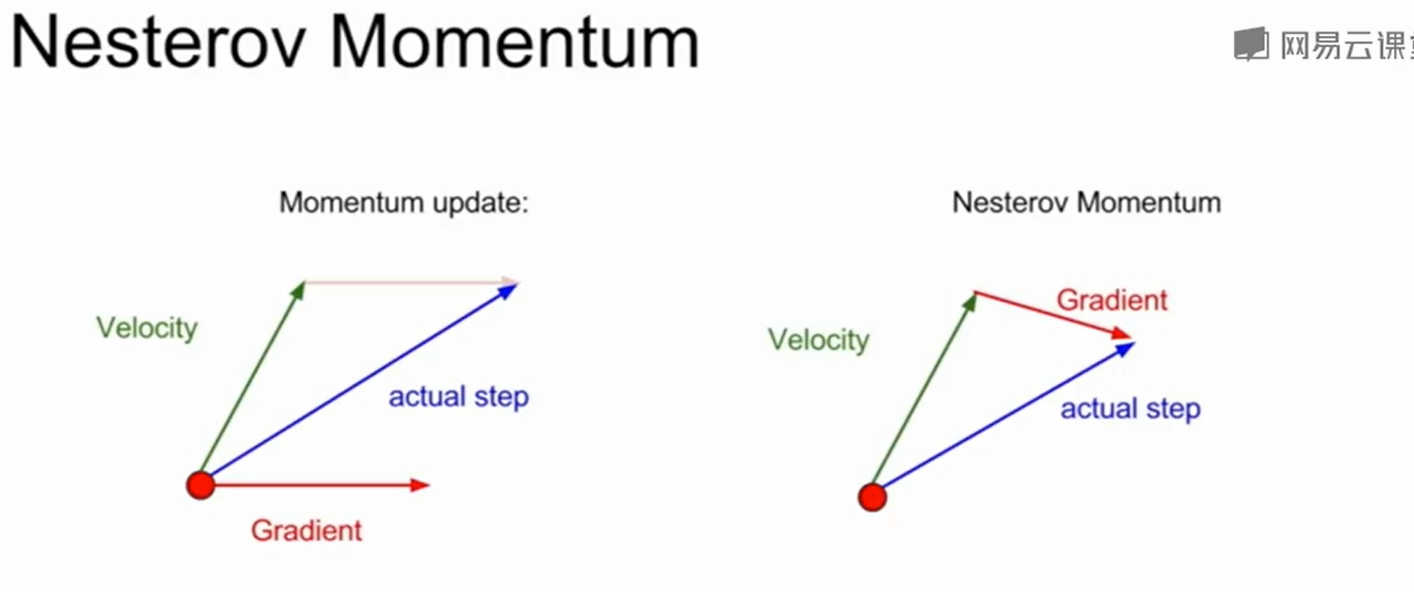

还有一种叫做Nesterov Momentum的SGD,在之前的动量梯度下降中我们是通过速度和梯度的求和得到新的速度,这个速度和真正最好的方向大致相同。而Nesterov Momentum也是求一个速度,然后先用这个速度去更新,然后更新完成后再算他的梯度,然后再返回更新前的状态,用更新前的速度+梯度去真正的做更新。
可以作换元得到:
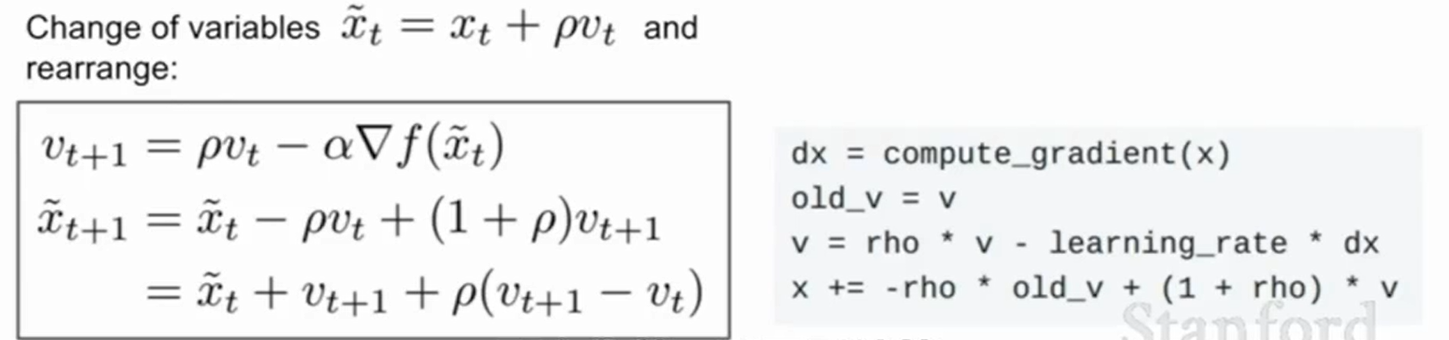
AdaGrad
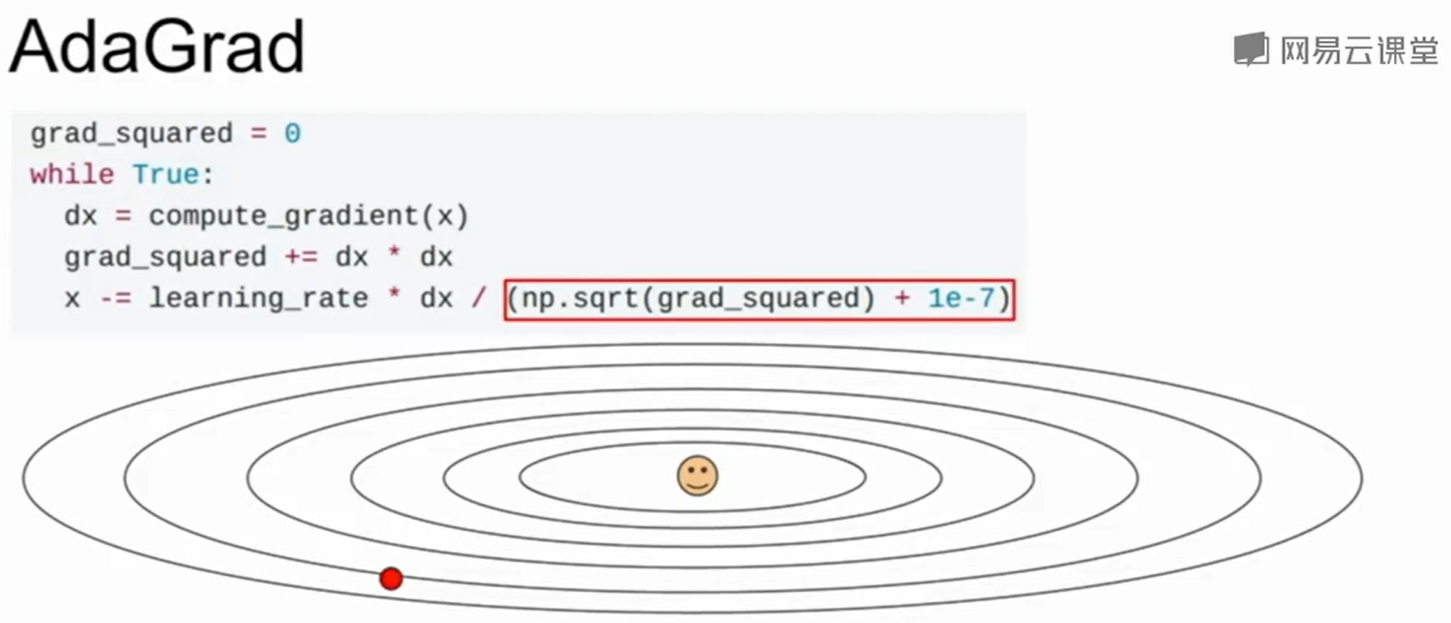
加了一个放缩项,也就是如果你在某一个维度上的梯度特别大,那么就grad_square会帮你更新时减少他的影响。
AdaGrad的问题在于他的step-size会越来越小,在学习目标是一个凸函数的时候,有理论证明这会表现得不错。但是在非凸函数上就会导致在局部极值点上被困住。
RMSProp
RMSProp是在AdaGrad基础上产生的变体,他除了每次对梯度进行叠加外,还增加了一个类似于摩擦系数/衰减系数的东西,来对梯度进行减少。
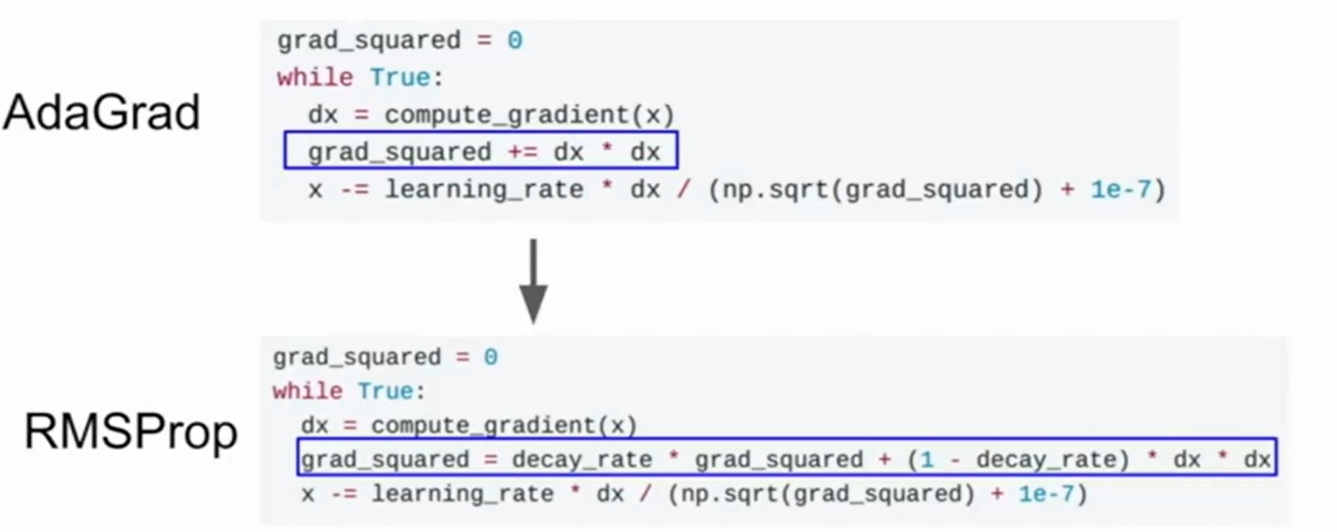
因此在局部极值点的时候,grad_square由于衰减系数会下降,梯度此时更新的步长反而会变大。
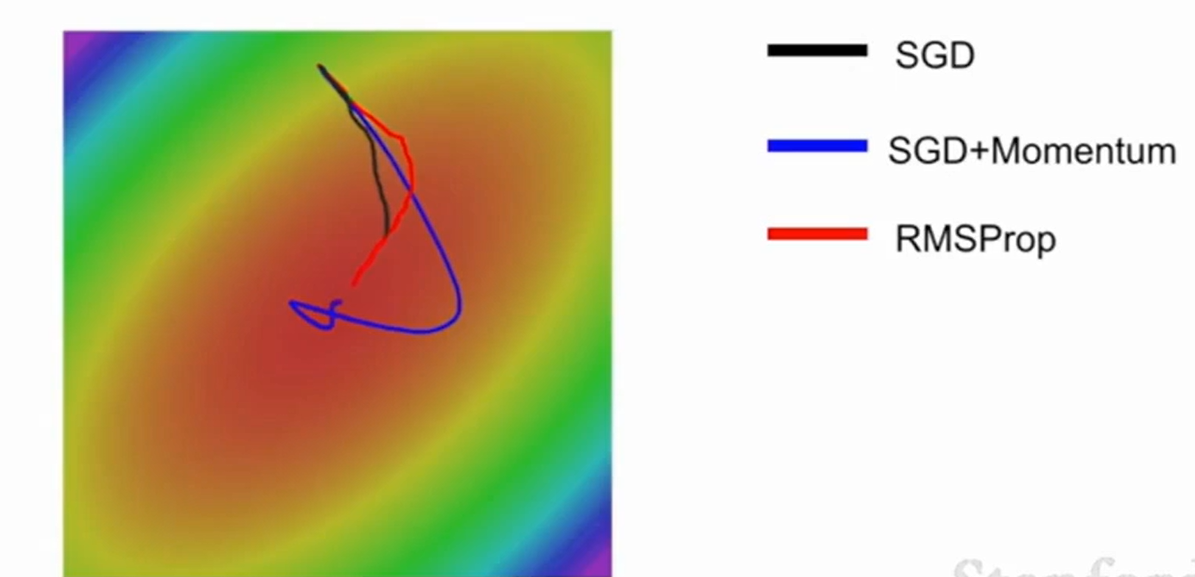
RMSProp会曲折得找最小值,而SGD Momentum会先绕过最小值点然后最后再回到loss最小的地方。
Adam

这种方法搞了两个动量,把动量和RMSProp融合在了一起。
但是在第一步我们会发现 第二动量(Second Momentum)是一个非常小的值,那么x第一步就会走很大的一步。因此可以加入无偏估计:
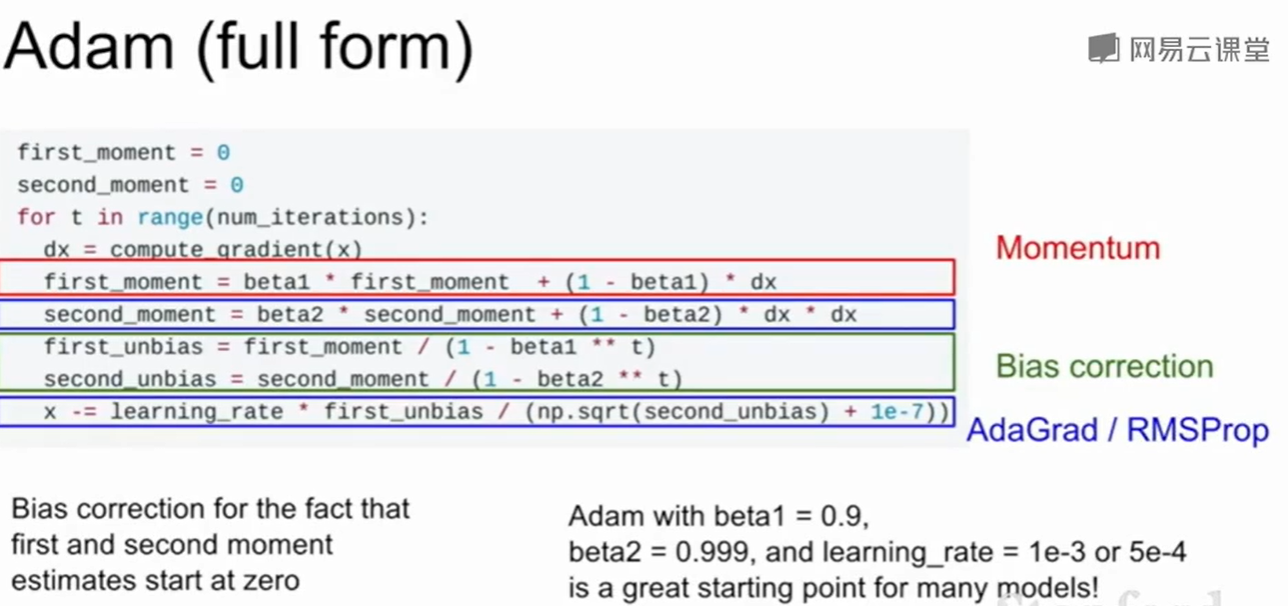
至于无偏估计的设置成这个样子的推到在:
Adam算法中的一阶矩和二阶矩的无偏估计如何证明是无偏的? - 湖海的回答 - 知乎 https://www.zhihu.com/question/325651810/answer/1120697058
一般Adam是我们的首选。
衰减的学习率
无论是什么什么样的梯度下降,学习率这个超参数都是避不开的,有时候学习率可以逐渐衰减也是一种方法。
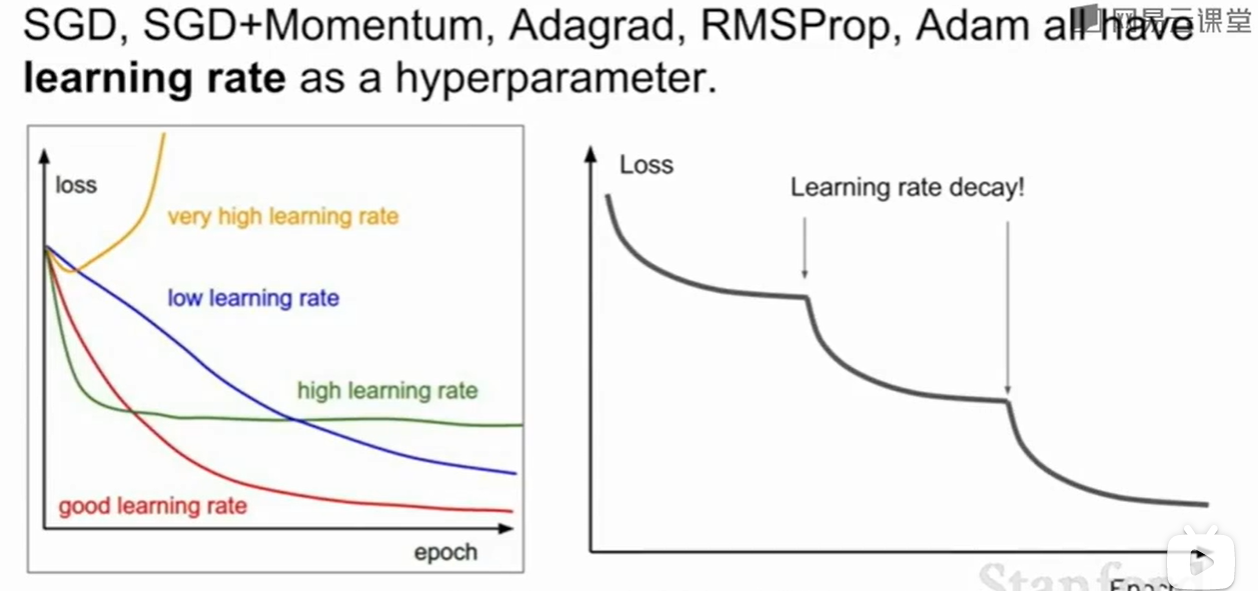
但是实际情况下不要直接让他衰减,应该先用没有衰减的看一看效果,观察loss的变化情况,然后再加上衰减试一试。
正则化(Regularization)
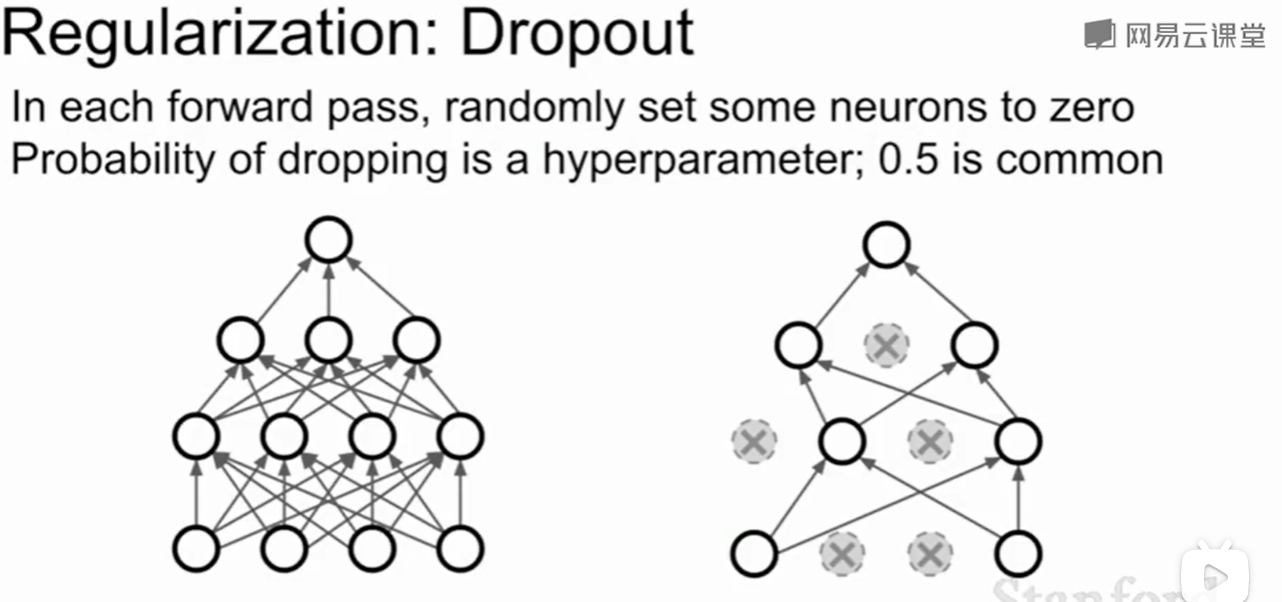
Dropout
一些常见的regularization

神经网络种我们常用$Dropout$这种方法:每层随机的把一些神经元的值置为0
代码实现只需要加上这几行:

为什么这个$Dropout$想法是可取的呢?
一种解释是:比如用网络去判断是否是一个猫,你列出了一堆的特征,是否有毛,有爪子….,而dropout删掉了一些特征,这样网络就不能完全依赖这些特征组合,而是真正的学到了一些东西,这就好比我每次都告诉你一步一步怎么做你是学不会东西的,但是我把其中一些部分去掉你来学习就会学到属于网络自己的东西,这样网络就需要零散不同的特征来判断。这一定程度上就防止了过拟合。

还有一种解释的理解方法是:由于dropout的存在,我们在dropout后用的是一个子网络来计算下面的,每一个dropout都会产生一个子网络,这就像一堆子网络用一个共享参数的集成学习。
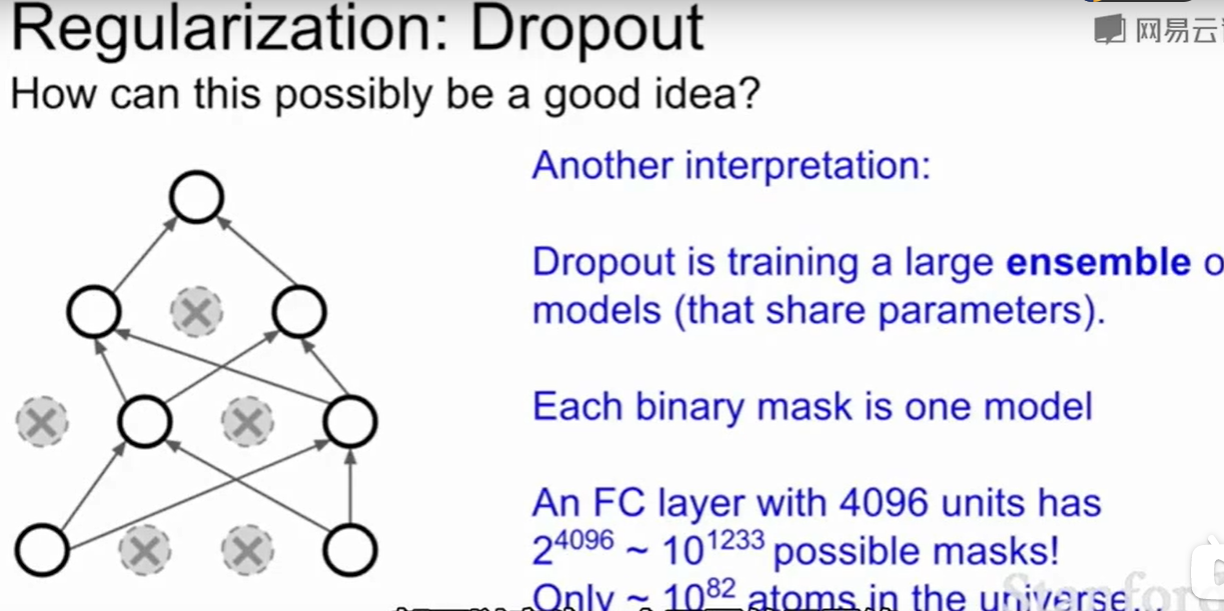
当我们测试时,Dropout的随机性会带来结果不确定,比如我们训练好一个网络,昨天测试还是人,今天就变成了猫,即使你的网络已经训练完成,参数也设定完成,但是随机使一些神经元失效依然会导致测试结果的不稳定。
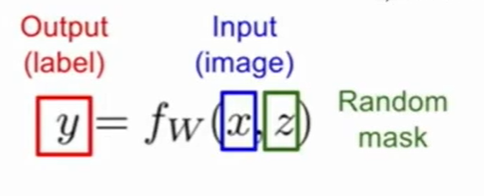
因此此时的网络类似于上述的式子,一种直观的想法是我们可以用平均来确定结果:
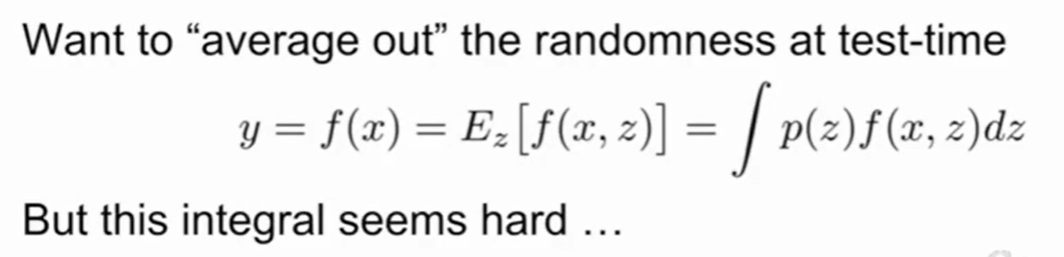
然而这个式子几乎是不可能处理的。
我们也许可以这样处理,考虑一个简单的神经元:

我们去求他的score的期望:得分的期望是不做dropout的一半。
因此我们可以在训练时用dropout,而在测试时把dropout去掉,但做传递得分时我们只传递一半。
这样用一种近似的方法求了原本随机结果的平均。
Batch Normalization
当然还记得Batch Normalization吗?我们一般认为加了BN就不用Dropout了,具体原因可以看上一节的BN。
数据增强(Data Augumentation)
还有一种正则化的思想是:数据增强(Data Augumentation)
数据增强从现有数据中生成更多有用数据的重要技术,用于训练实用的、通用的卷积神经网络,在不改变神经网络结构的前提下能有效降低过拟合,是一种有效的正则方法。目前深度学习中的数据增强方法大致有三类:
- 空间变换
- 颜色失真
- 信息丢弃
Realted:【技术综述】深度学习中的数据增强方法都有哪些? - 言有三的文章 - 知乎 https://zhuanlan.zhihu.com/p/61759947
Dropconnect
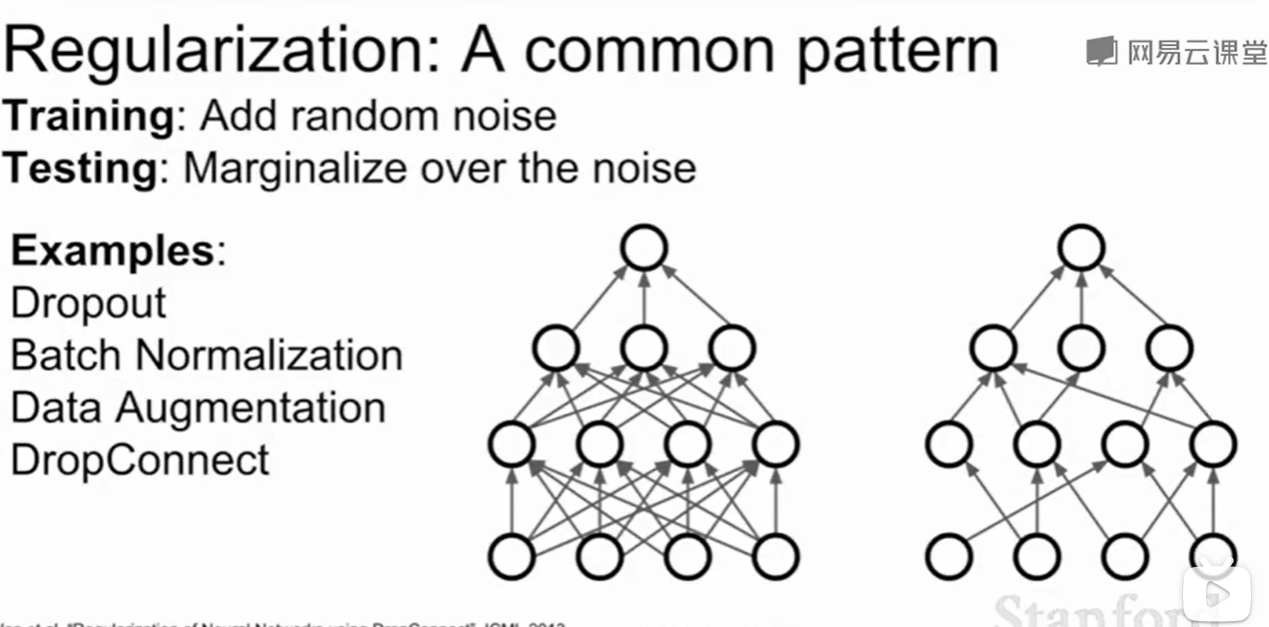
这种方法把层间的权重w矩阵的一部分置为了0。
Stochastic Depth
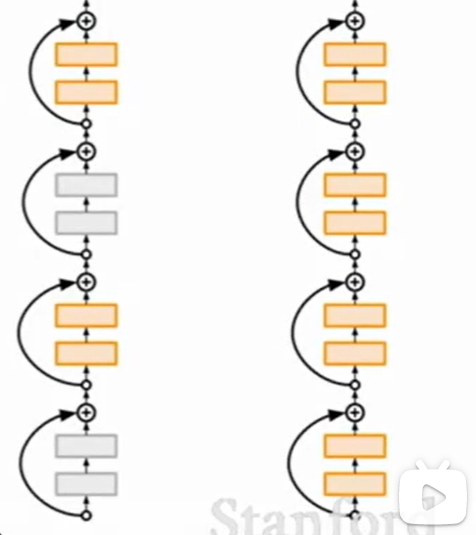
训练的时候只用部分层,测试的时候用所有层。
太过于学术界的trick,实际上没多少人用。
迁移学习(Transfer learning)
Transfer Learning帮助你没有很大的数据集也可以很好的训练网络。
下面引用自:
请问具体什么是迁移学习? - Chuang的回答 - 知乎 https://www.zhihu.com/question/345745588/answer/826649936
迁移学习(Transfer learning) 顾名思义就是把已训练好的模型(预训练模型)参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。
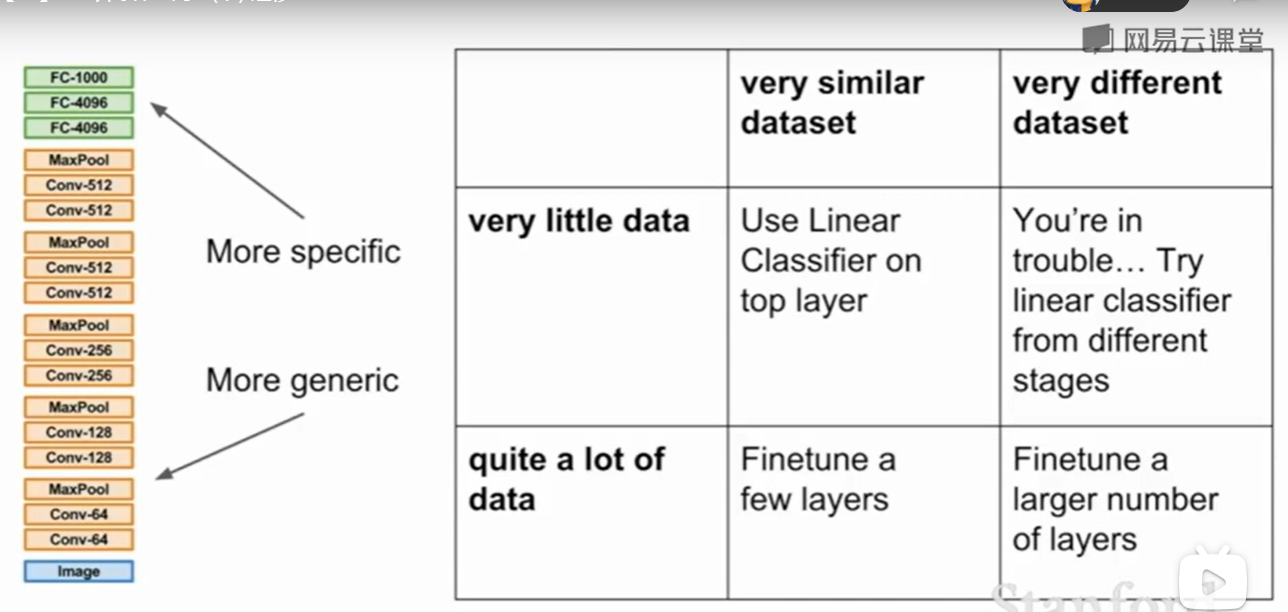
其中,实现迁移学习有以下三种手段:
- Transfer Learning:冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
- Extract Feature Vector:先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。
- Fine-tuning:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层,因为这些层保留了大量底层信息)甚至不冻结任何网络层,训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!