强化学习纲要Ch1-Overview
Intro to Reinforcement learning-Overview
强化学习可以做什么?
强化学习成为近几年来的热点,强化学习这种方法再许多领域上都取得了成功,比如,强化学习可以教计算机在虚拟环境中控制机器人,控制机器手等…

(图:机器手按照规则旋转立方体)
对于一些策略游戏来说,强化学习在近几年同样有很大的突破:比如王者荣耀的觉悟AI(AAAI2020,Mastering Complex Control in MOBA Games with Deep Reinforcement Learning),围棋中的AlphaGo和MOBA游戏DOTA(Dota 2 with Large Scale Deep Reinforcement Learning)。这些策略游戏需要角计算机在无数的像素构成画面中学会策略游戏,并学习人类的操作。
强化学习的主要思想:
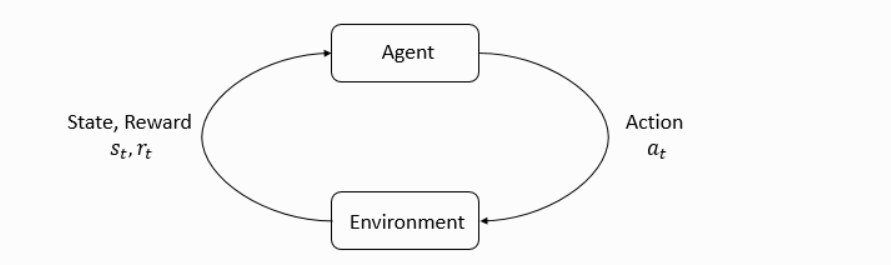
强化学习中的两个重要角色是:Agent(智能体)和Environment(环境),Environment是Agent不仅所处的地方,也是Agent进行交互的对象。在每次交互时,Agent首先观察Environment的状态,并作出一种决策后开始行动后。此时环境也由于Agent的行动开始发生变化。需要注意的是,环境的变化也可能是自己变化导致的,不一定是Agent导致的。
环境的变化/状态会使得智能体获得激励信号(reward signal),激励信号可以简单理解为一个数值,或者向量,它会告诉智能体此时环境的状态是好还是坏,当然这里的好坏是由你自己的目标来定义的,智能体的目标就是最大化他的累计奖励(cumulative reward),可以简单理解为智能体所获得的回报(Return)。
强化学习和监督学习的区别:
- 强化学习中的数据是一个序列,但是却不是独立同分布的,比如打砖块这个游戏,他的输入序列就是一帧帧的图像,图像间很显然不是独立的。
- 学习者无法告诉你哪儿个动作好,而是自己去尝试,同时也导致了强化学习的reward是delay的,不会实时反应。
- Trial and error exploration,我们要平衡exploration和exploitation,exploration指我们会尝试一些新的方法,有可能效果会很好,也有可能会导致效果变差,浪费了时间,exploitation指就按照现在已经尝试过的方法中效果最好的一种接着训练。
- 我们只有reward signal来判断我们的效果如何,而这个激励信号也是是delay的。

历史就是输入的一个序列:观测,动作,回馈这样的序列
我们可以把state看成有关历史的一个函数:
我们一般有两个state,分别是:环境状态和智能体状态
全观测:
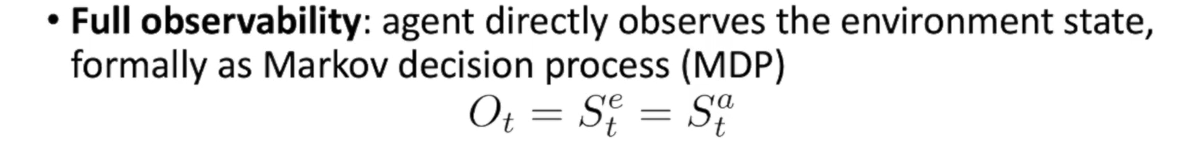
部分观测:

对于扑克牌这种游戏,我们是无法看到对方的牌的,所以无法做到全观测。

对于一个agent需要有下面几个内容:
- policy:策略,agent的有关动作的函数

策略有随机策略和确定策略,随即策略是对于策略分布进行抽样,抽出一种策略。
value function:价值函数,评价每个状态/动作的好坏

价值函数就是在某一种策略下,未来的奖励在折价后的和的期望。
这个折价是折价因子(Discount factor)造成的,折价因子的出现是因为我们想在较短的时间里获得较多的收益,所以时间越后面所获得的回报应该做一个折扣。
value function可以用在两个方面
一个是评价状态和动作的好坏:
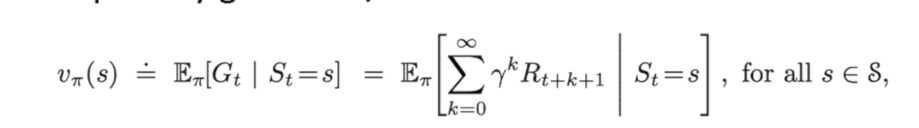
也可以通过这个函数来选择动作:
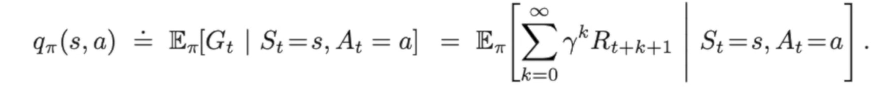
model:模型,agent对环境的理解,预策环境的状态

基于策略的方法:
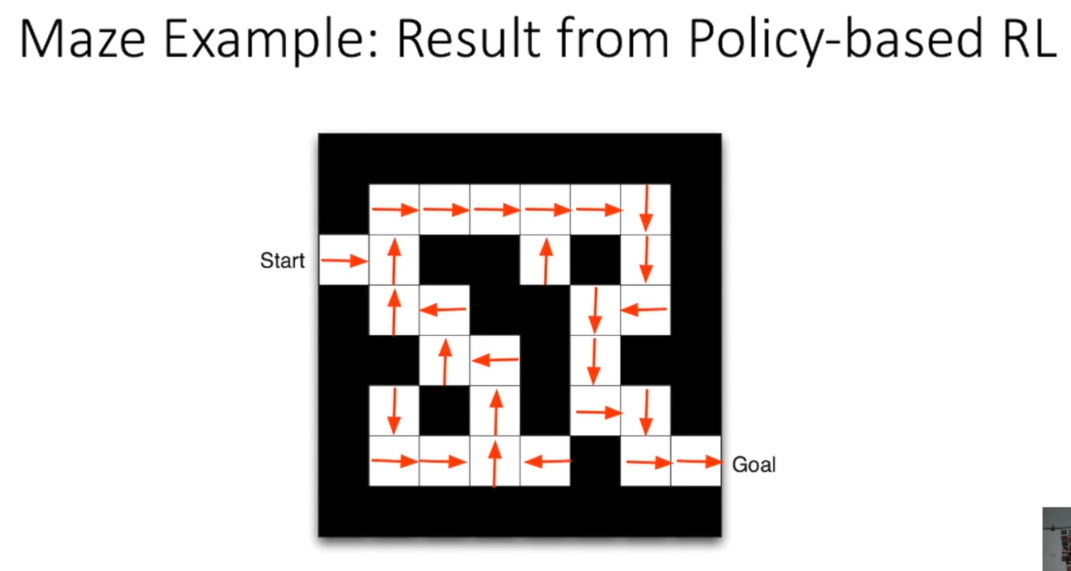
基于价值函数的方法:

agent有三种(基于学习方法):

一种是value-based agent:它通过价值函数来做决策,就像上面的走迷宫,距离终点的距离大小就是他的决策方法。同时他隐式的学习到策略,也就是走最近的路。
还有policy-based agent:直接学习策略
还有Actor-Critic agent:两者都学习
基于是否有模型,agent分为:

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!