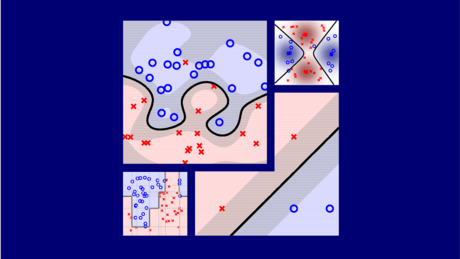
机器学习技法CH2:Dual Support Vector Machine CH2:Dual Support Vector MachineMotivation of Dual SVM我们上节提到过,如果想让SVM来做非线性的分类,那么我们是需要feature transform的,此时的问题变为了: 这个$\phi(x_n)$就是对原来的$x_n$做了feature transform。 我们的二次规划问题也变为了: 为什么想到用SVM来做这件事情呢,因为在 2021-02-05 机器学习
机器学习技法CH1:Linear SVM CH1:Linear SVMLarge-Margin separating Hyperplane 这三种线都可以把这些点分开。 PLA算法不一定会得出哪儿一种线 从我们的VC Bound来看,$E{in}=0$都一样,$d{VC}$=也一样,那么 VC Bound所带来的保证$E_{out}$都相同。 但其实我们的直觉告诉我们第三种好一点,因为他如果有一些数据有误差,那么也不会 2021-02-03 机器学习
机器学习基石CH16:Three Learning Principle(完结) CH16:Three Learning PrincipleOccam’s Razor(奥卡姆剃刀) 对数据最简单的解释也是最有说服力的解释。 我们肯定认为左边的好一些。 什么叫做simple model,hypothesis很简单的model,hypothesis set里的hypothesis不是很多。 如果我们的资料很乱随机给出,毫无规律可循,那么我们可以完美的分开这些资料的概率是: 2021-01-27 机器学习
机器学习基石CH15:Validation CH15:ValidationModel Select Problem选择的依据: 第一种:只做$E_{in}$ 做低一些,这样选模型肯定不是很好 第二种:选择在最终测试集上的一部分数据,然后对每个模型进行测试,然后选取准确率最高的。 由hoeffding不等式来看,这样的结果还不错: 但是现实中我们几乎不能拿到最终测试集的,这是一个自欺欺人的做法。 以上两种方法都不是很好,或许我 2021-01-27 机器学习
机器学习基石CH14:Regularization CH14:RegularizationRegularized Hypothesis Set 我们之前由于overfit造成了右边图所示的状况,我们今天要把右图转化为左图通过:Regularization 因此我们要从高次的hypothesis走回到低次的hypothesis,因此我们想找一种方法可以提供一种指标使得高次走回到低次。 因此我们可以看出:低次多项式其实就是高次多项式 加上了一些限 2021-01-25 机器学习
机器学习基石CH13:Hazard of Overfitting CH13:Hazard of OverfittingWhat is overfitting 比如我们现在的数据是通过一个二次曲线+noise 造出来的数据,然后我们用这个数据进行机器学习,假如你用了5次曲线(即一定可以经过上述的五个点),那么我们就会画出图中红色的曲线(且$E_{in}=0$) 但是她和我们的target function蓝色线差距很大。 一个overfitting的例子: o 2021-01-24 机器学习
《线性代数及其应用》CH3:行列式 第三章 行列式3.1 行列式介绍注: $det \ A$ 代表行列式A的值 一个矩阵展开成代数余子式可以按行或者列展开(即 定理1) 定理2: 3.2 行列式的性质行变换的性质: 可逆与行列式的联系: 列变换: 有了定理5我们不难想到,行列变换规则是一样的。 行列式乘积: 例题: 行列式函数的一个有趣的线性性质: 证明:(2)这个其实就是列变换,显而易见 2021-01-24 线性代数
机器学习基石CH12:Nonlinear Transformation CH12:Nonlinear TransformationQuadratic Hypotheses(二次假设)Linear Hypothesis 线性模型可以算一个分数,它最大的好处是$d_{VC}$ 可以被控制,当然线性模型在某些数据上每条线都做不到效果很好。 我们这里用一个圈就可以很好地进行分类。 那么我们可以设一个圆形的PLA,可是图形是千变万化的,我们不可能每个都设计出来一个PLA 2021-01-23 机器学习
机器学习基石CH11:Linear Models for Classification CH11:Linear Models for ClassificationBinary Classification我们回顾一下线性模型: 我们看一下三个error function在做classification时的区别: $ys$代表着正确的分数。 下面我们画个图来看一下3个error function的图像: 这个cross-entropy可以稍微移动下,移动到ys=0的那个阶梯直角 2021-01-21 机器学习
机器学习基石CH10:Logistic Regression CH10:Logistic RegressionLogistic Regression Problem(逻辑回归)我先我们看两个例子,看一看 他们的不同: 根据一些指标来预策是否会有心脏病, 很明显是一个分类的问题,我们关心的是错误率为多少。 再看看看这个问题,求心脏病出现的可能性。 这不在是一个简单的二元分类问题,而是需要给出概率,我们称之为: soft binary classificat 2021-01-20 机器学习