CS231n-CH6-训练神经网络-下 训练神经网络(下)更好的优化SGD的缺点: SGD在某些情况下效果并不会很好,比如loss在竖直方向上下降的很快,在另两个维度上loss下降的很慢,这就会导致得到上下剧烈波动的线。在三维空间如此,在高维空间上更容易出现这个问题。最优化过程会变得很慢。 SGD还有一个缺点就是无法处理鞍点: 即梯度=0,但是却不是极大值/极小值。 梯度到这个地方时由于梯度变为了0,会导致停止迭代。 在这个一维的情况 2021-04-13 计算机视觉CV
CS231n-CH5-训练神经网络(上) 训练神经网络(上)激活函数 问题: 当x是一个很大/很小的区域时,梯度是一个十分接近0的数值,这会导致upstream如果是0,那么返回值就会十分小。这会使得梯度逐渐消失。 比如这个方程的对$x$的梯度是一堆$w$,我们假设数据的x要么都是大于0/要么都是小于0的,那么$\Sigma w_ix_i+b$这个式子对$w$求梯度是一堆$x$,我们上面假设了这里都是大于0,那么这个梯度也都大于 2021-04-12 计算机视觉CV
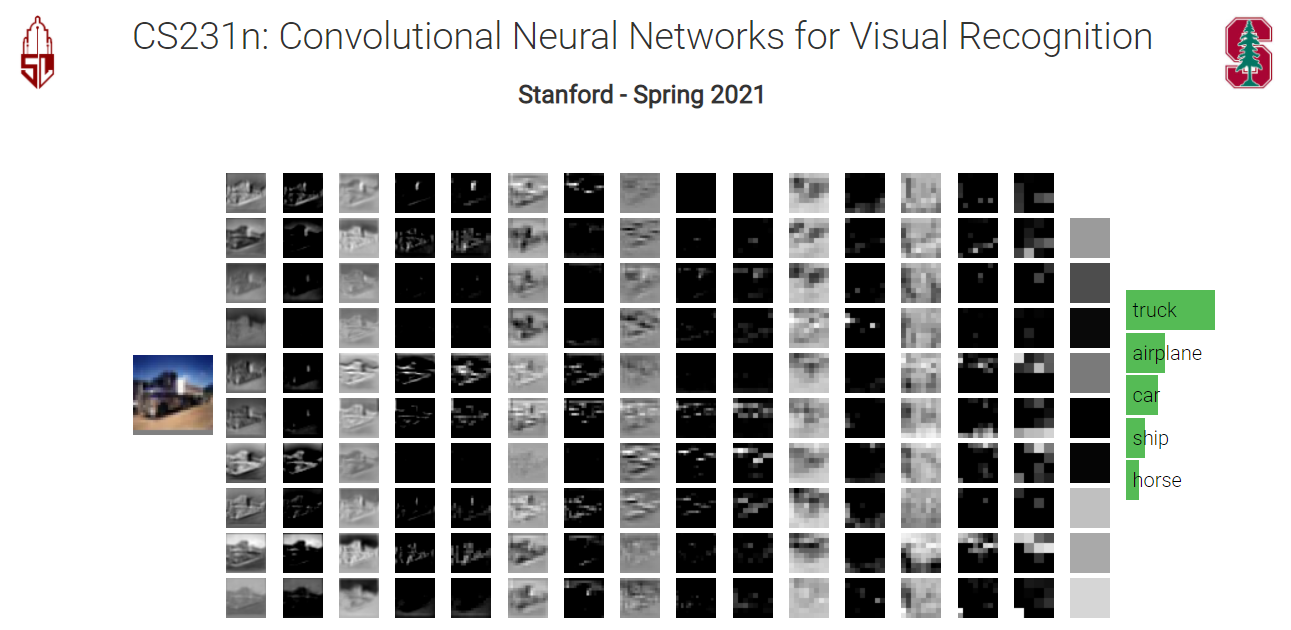
CS231n-CH4-卷积神经网络 卷积神经网络卷积全连接层: 卷积层(convolution Layer): 卷积网络就是一系列的卷积层的叠加,并加上各种各样的激活函数。 随着层数的增加,所包含的信息越来越多。 卷积计算过程: 我们可以一步一步的来走,那么得到的就是 5*5的结果 但是步长调整到2时: 那么得到的就是一个3*3的结果。 步长为3时:(7-3)/3+1 = 2.33 所以这样会导致不平衡的结果,所以步长 2021-04-09 计算机视觉CV
CS231n-CH3-介绍神经网络 介绍神经网络反向传播(backpropagation)梯度的计算是通过计算图 : 链式法则告诉我们,我们只需要把计算图上的每一段相邻的梯度算出来,我们连乘上他们就是最后一个变量对最前面一个变量的梯度。 backpropagation的运行方式: 一个比较复杂的例子: 对于add门,求对两边梯度都是1,因此直接传过去梯度upstream gradient即可: 对于max门,local 2021-04-08 计算机视觉CV
CS231n-CH2-损失函数/最优化/特征提取 CS231n:Computer Science损失函数和优化损失函数(Loss Function) 我们这里使用了multiclass SVM loss(hinge loss function),如果属于$y_i$类别的图像在$y_i$类得到的分数比在$j$类中得到的分数多1(这个1可以看作两类差距的一个阈值margin,毕竟如果两类如果差距不大,说明分类还是有些问题的,此时loss也 2021-04-07 计算机视觉CV
CS231n-CH1-图像分类 CS231n:Computer Science图像分类数据驱动方法 800*600*3, 其中3代表三个channels(R,G,B)。 我们可以把图像分类想成这两个大的部分: 第一个是训练部分:放进去(图像,label),训练得到模型 123def train(imgs, labels): #Machine Learning return model 第二个是预策部分:有了模型 2021-04-06 计算机视觉CV
机器学习技法CH15:Matrix Factorization CH15:Matrix FactorizationLinear Network Hypothesis 还记得Netflix推荐系统那个问题吗,他给出的数据$D$ 有两个东西,一个是$\tilde x$,代表着用户的ID,例如:1126,5566,6211 另一个是ID为$n$的人,对电影$m$的评分,我们记为$r_{nm}$。 类似于ID,血型,编程语言 这种feature都是categoric 2021-03-20 机器学习
机器学习技法CH14:Radial Basis Function Network CH14:Radial Basis Function NetworkRBF Network Hypothesis首先回忆一下Gaussian Kernel在SVM中的应用 我们在$x_n$处找$\alpha_n$ 来组合Gaussian Kernel,使得实现最大边界。 高斯核也叫径向基(Radial Basis Function,RBF)核。其中radial代表我们今天算的和距离有关,也就 2021-03-18 机器学习
机器学习技法CH13:Deep Learning CH13:Deep LearningDeep Neural Network Deep NNet特点 : 训练很难 结构复杂,很多层很难决定结构 模型效果很好 层数变多可以获得更多的实际物理意义 实际物理意义举个例子,如下 : 每一层的神经元都有他自己的物理意义,向着从简单到复杂feature的转换。 一些Deep Learning的chllenges和keys: 结构复杂 比如 2021-03-17 机器学习
机器学习技法CH12:Neural Network CH12:Neural NetworkMotivation 我们可以自由决定$w$和$\alpha$ . 首先这种aggregation操作可以做到logic operation(逻辑运算): AND运算: 我们的这种aggregation of Perceptron是很复杂度 : 上图发现,我们用足够多的perceptron就可以得到一个近似于target boundary的结果,因此它 2021-03-16 机器学习