Codeforces Round #754 (Div. 2) A-E 题目地址:链接 A. A.M. Deviation(贪心)每次操作可以使得a+c-2*b +3或者-3 。那么答案只需要%3即可,如果%后结果为2,就让他再减去3等到|-1| = 1; 1234567891011121314151617181920212223242526272829303132333435363738394041424344//#pragma comment(linker, 2021-11-15 ACM-Codeforces
ABC224-G - Roll or Increment(人类智慧,数学) 题意一个$N$个面的骰子,开始的值是$S$,现在希望到$T$,你可以做两种操作,操作可以任意顺序,任意次: 1.花费$A$:将$S$加$1$,但要注意$S$等于$N$时不可以进行该操作。 2.花费$B$:随机投掷骰子一次,等概率出现$1-N$之间的数。 寻求一种$S$到$T$期望花费最小的策略,输出最小期望。 范围 思路 首先思考,如果一个骰子做了操作1在做操作2,这是十分奇怪的,因为既然 2021-11-11 ACM-Atcoder
LeetCode 建信 04.电学实验课(矩阵快速幂,计数) LeetCode 建信 04.电学实验课(矩阵快速幂,计数)题目描述:某电学实验使用了 row * col 个插孔的面包板,可视作二维矩阵,左上角记作 (0,0)。老师设置了若干「目标插孔」,它们位置对应的矩阵下标记于二维数组 position。实验目标要求同学们用导线连接所有「目标插孔」,即从任意一个「目标插孔」沿导线可以到达其他任意「目标插孔」。受实验导线长度所限,导线的连接规则如下: 一条导 2021-11-10 Leetcode
Codeforces Round #753 (Div. 3) F-H F. Robot on the Board 2(搜索)题意: 题意:有一个n*m的棋盘,每个格子上有一个字符,U, D, L, R四个之一。机器人从任意一个格子为起始位置,按着字符方向(U,D,L,R分别是上下左右)走一格,直到碰到走过的格子或者出边界,最长的运动路径长度是多少。输出使运动路径最长的起始位置和路径长度 题解: 遍历每个点并对每个点按照规则搜索,同时记录走过的路径,走过的路径无需重复 2021-11-06 ACM-Codeforces
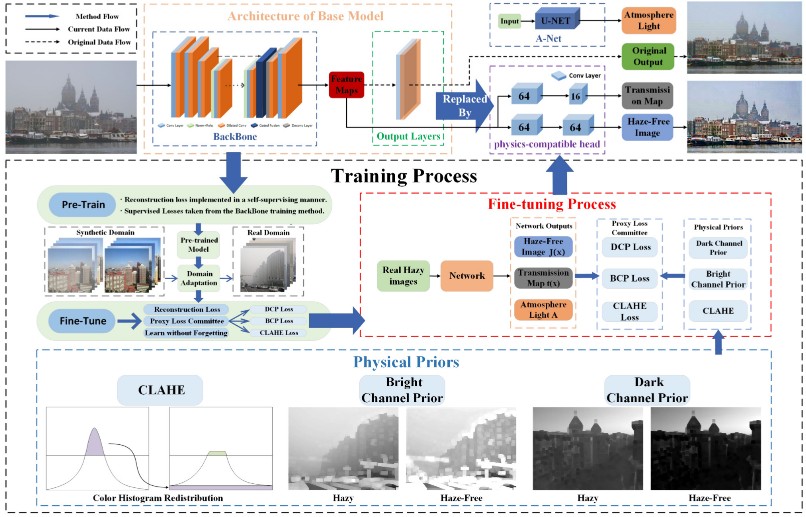
PSD: Principled Synthetic-to-Real Dehazing Guided by Physical Priors介绍 PSD: Principled Synthetic-to-Real Dehazing Guided by Physical PriorsIntroduction首先介绍一下雾霾模型: I(x) = J(x)t(x) + A(1-t(x))其中$J(x)$是原图,$I(x)$是观测的雾霾图像,$t(x)$是透射率,$A$是全局大气光。 早期模型是基于物理先验的方法,然而这些方法鲁棒性很 2021-07-22 计算机视觉CV
MTCNN(Multi-task Cascaded Convolutional Networks)介绍 MTCNN-Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks创新点 MTCNN框架利用级联架构,通过精心设计的深度卷积网络的三个阶段,以从粗略到细致的方式预测人脸和landmark位置。 提出 a new online hard sample mining strategy,即一种 2021-07-19 计算机视觉CV
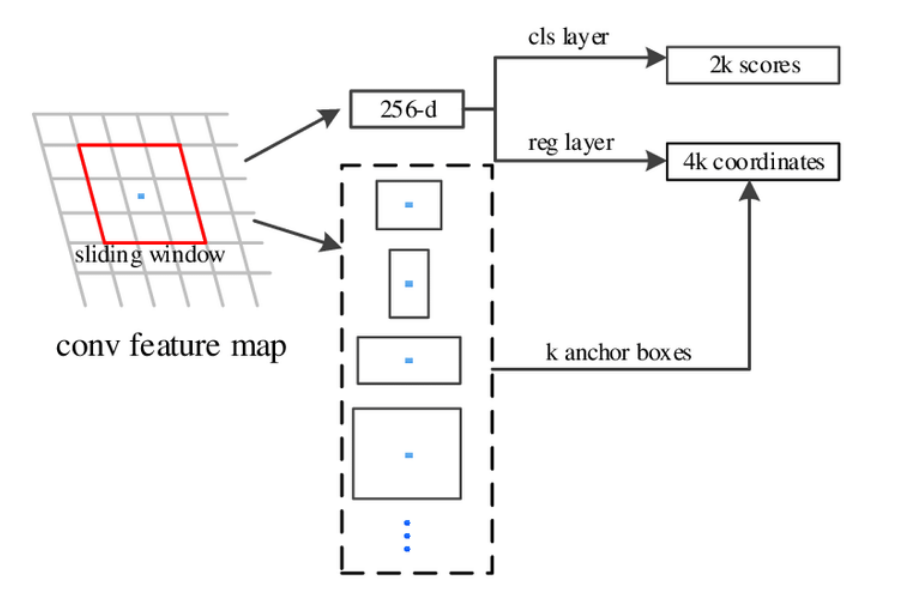
RPN(Region Proposal Network)介绍 RPN(Region Proposal Network)RPN简单来说就是输入一张图片可以得到很多待选框的一个网络,再详细一点就是: RPN的本质是对所有候选框进行判定,前景概率为多少,如果是前景那么其候选框所需要的修正因子应该是多少。 首先经过backbone提取特征: 首先拿到一张原图时,我们要先利用backbone获得feature map,可以看到上图中右部从feat 2021-07-18 计算机视觉CV
强化学习纲要Ch10-策略优化进阶 策略优化进阶——上本次的内容: 首先还是先回顾一下Value-based RL和Policy-based RL区别: 策略目标和策略梯度: 策略梯度(Policy gradient)有下面几种常见的算法: 这里要说一下这四个优化方法的关系: 首先是REINFORCE使用的是$G_t$,是由MC方法获得的,他其实就是Q Actor-Critic方法中$Q^w$的采样。Advantage Ac 2021-06-07 强化学习
强化学习纲要Ch9-策略优化基础-下 策略优化基础——下Score Function Gradient Estimator我们考虑写一个更广义的策略函数: 上面那个推导过程不太详细,下面给出具体的推导步骤: 这个梯度可以理解为: p(x)为采样得到的值,他们梯度就是上图蓝色箭头,而f(x)代表给这些梯度一个权重。 比如当权重分布如下时: 此时这个p(x)分布会向权值大的哪个方向平移,最后移动至下图: 可以看到概率函数p(x) 2021-06-07 强化学习
机器学习中的KernelModel/LinearModel总结 机器学习中的KernelModel/LinearModel总结 对学到的一些KernelModel/LinearModel做了一下梳理,便于以后忘记时能知道他们提出的动机和与其他模型的联系. PDF文件链接:谷歌云盘 2021-05-25 机器学习